Hadoop中MapReduce基本案例及代码(三)
84 浏览量
2021-01-20
12:38:41
上传
评论
收藏 101KB PDF 举报

Hadoop中中MapReduce基本案例及代码(三)基本案例及代码(三)
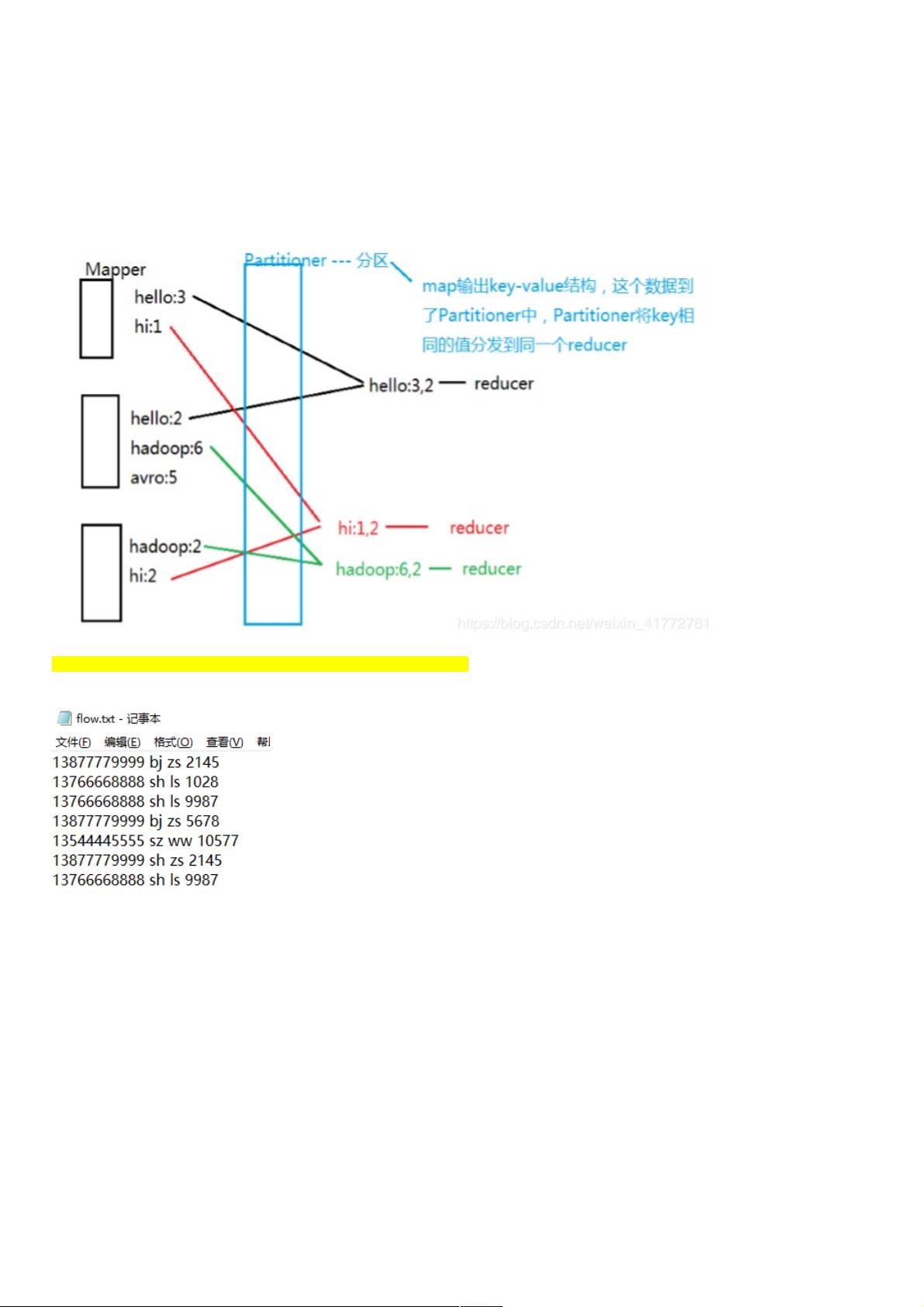
分区分区Partitioner
分区操作是shuffle操作中的一个重要过程,作用就是将map的结果按照规则分发到不同reduce中进行处理,从而按照分区得到
多个输出结果。
Partitioner是partitioner的基类,如果需要定制partitioner也需要继承该类HashPartitioner是mapreduce的默认partitioner。
计算方法是:which reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
注:默认情况下,reduceTask数量为1 很多时候MR自带的分区规则并不能满足我们需求,为了实现特定的效果,可以需要自
己来定义分区规则。
案例:根据城市区分,来统计每一个城市中每一个人产生的流量案例:根据城市区分,来统计每一个城市中每一个人产生的流量
数据源数据源
自定义自定义Flow类类
与上一节所讲一样,自定义类实现Writable接口,重写其中readFields(),write()方法。详情看上一节。
Mapper类类
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class FlowMapper extends Mapper {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split(" ");
Flow f = new Flow();
f.setPhone(arr[0]);
f.setCity(arr[1]);
f.setName(arr[2]);













评论0