
Nodejs爬虫进阶教程之异步并发控制爬虫进阶教程之异步并发控制
之前写了个现在看来很不完美的小爬虫,很多地方没有处理好,比如说在知乎点开一个问题的时候,它的所有回答并不是全部加载好了的,当你拉到回答的尾部时,点击加载更
多,回答才会再加载一部分,所以说如果直接发送一个问题的请求链接,取得的页面是不完整的。还有就是我们通过发送链接下载图片的时候,是一张一张来下的,如果图片数量
太多的话,真的是下到你睡完觉它还在下,而且我们用nodejs写的爬虫,却竟然没有用到nodejs最牛逼的异步并发的特性,太浪费了啊。
思路
这次的的爬虫是上次那个的升级版,不过呢,上次那个虽然是简单,但是很适合新手学习啊。这次的爬虫代码在我的github上可以找到=>NodeSpider。
整个爬虫的思路是这样的:在一开始我们通过请求问题的链接抓取到部分页面数据,接下来我们在代码中模拟ajax请求截取剩余页面的数据,当然在这里也是可以通过异步来实现
并发的,对于小规模的异步流程控制,可以用这个模块=>eventproxy,但这里我就没有用啦!我们通过分析获取到的页面从中截取出所有图片的链接,再通过异步并发来实现对这
些图片的批量下载。
抓取页面初始的数据很简单啊,这里就不做多解释啦
/*获取首屏所有图片链接*/
var getInitUrlList=function(){
request.get("https://www.zhihu.com/question/")
.end(function(err,res){
if(err){
console.log(err);
}else{
var $=cheerio.load(res.text);
var answerList=$(".zm-item-answer");
answerList.map(function(i,answer){
var images=$(answer).find('.zm-item-rich-text img');
images.map(function(i,image){
photos.push($(image).attr("src"));
});
});
console.log("已成功抓取"+photos.length+"张图片的链接");
getIAjaxUrlList();
}
});
}
模拟ajax请求获取完整页面
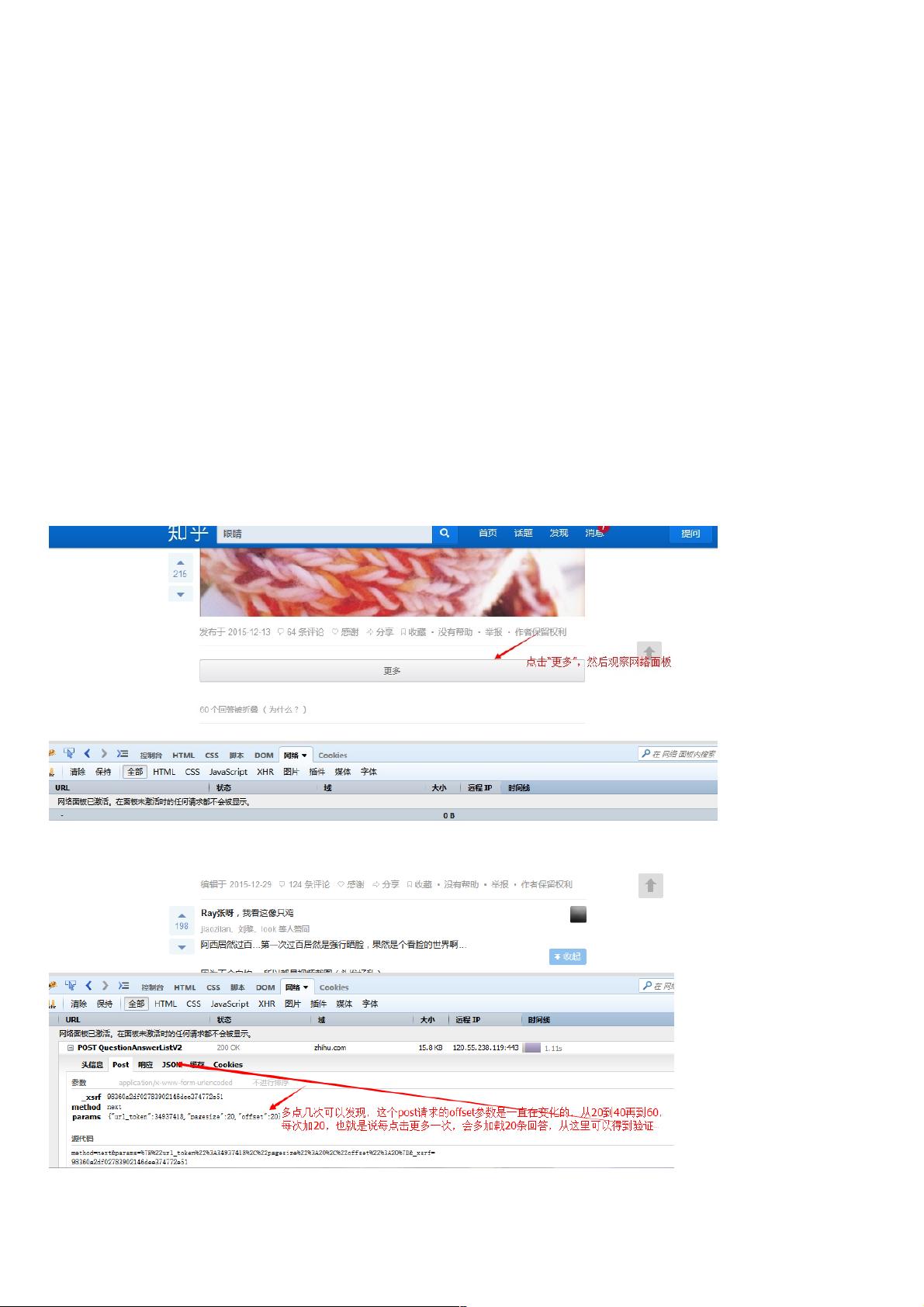
接下来就是怎么去模拟点击加载更多时发出的ajax请求了,去知乎看一下吧!

weixin_38680340
- 粉丝: 4
- 资源: 979









最新资源
- bfgbghjyujkyuh
- 基于Java的宠物狗销售系统的设计与实现.doc
- 废物垃圾分类检测41-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- gperftools依赖到的unwind库,用于c++性能分析
- 数据管理界面插件REPORT11
- 基于java的大学生二手书在线买卖系统论文.doc
- RabbitMQ 的7种工作模式
- 停电自动关机程序.EXE
- ODrive 固件 0.5.6
- 基于Java的电影订票网站的设计与开发毕业设计论文.doc
- 基于tensorflow和cnn做的图像识别,对四种花卉进行了分类项目源代码+使用说明,可识别:玫瑰花、郁金香、蒲公英、向日葵
- 探索CSDN博客数据:使用Python爬虫技术
- SSM技术助力创客教育:小码创客教学资源库的构建与实现
- 废物垃圾检测28-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- Java SSM框架在农产品质量安全检测网站中的应用
- 基于javaweb的动漫网站管理系统毕业设计论文.doc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0