
MySQL索引深入剖析索引深入剖析
1. 索引是什么?索引是什么?
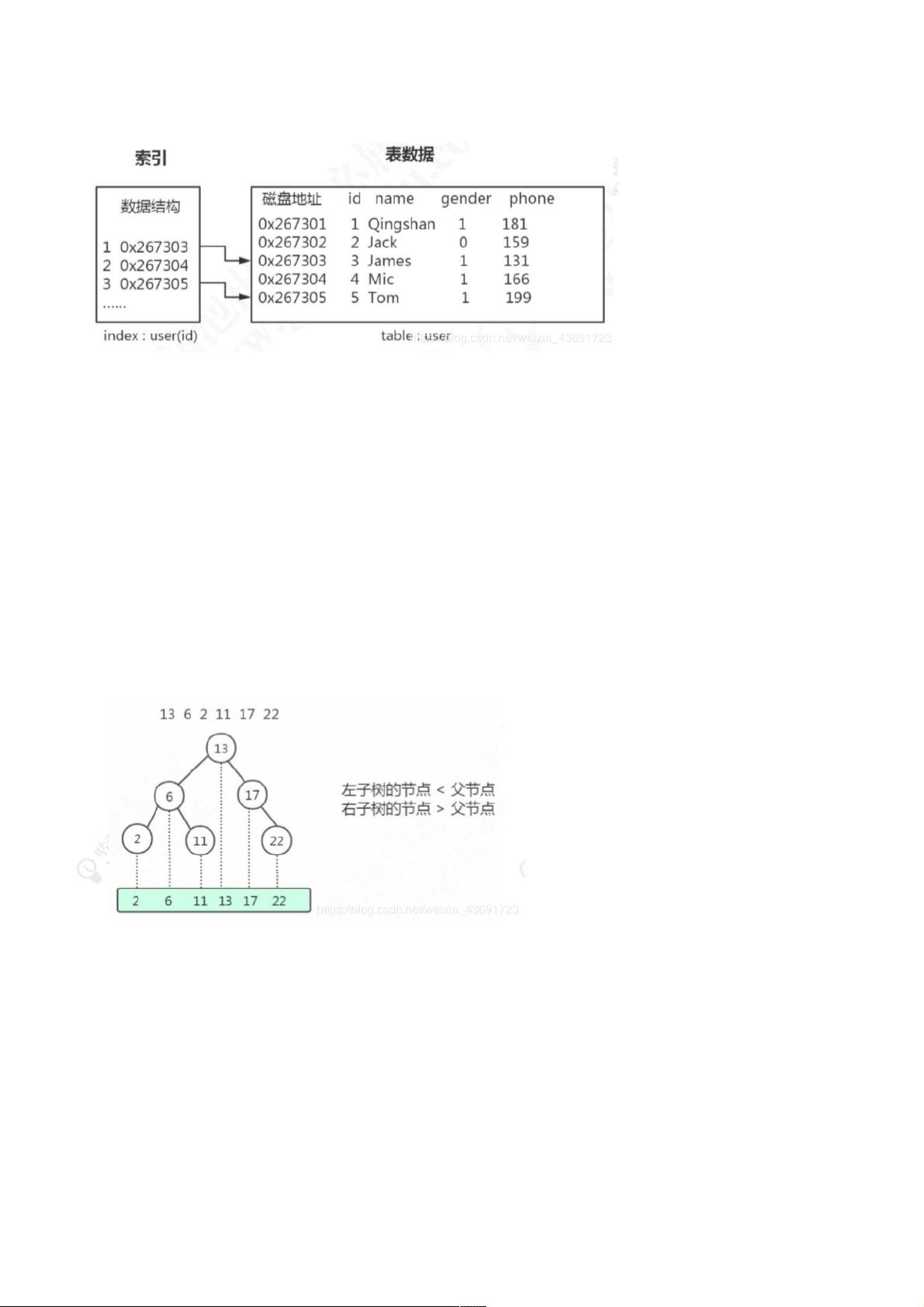
1.1 索引图解索引图解
数据库索引,是数据库管理系统(DBMS)中一个排序的数据结构,以协助快速查询、更新数据库表中数据。
数据是以文件的形式存放在磁盘上面的,每一行数据都有它的磁盘地址。如果没有索引的话,我们要从500万行数据里面检索一条数据,只能依次遍历这张表
的全部数据(循环调用存储引擎的读取下一行数据的接口),直到找到这条数据。但是有了索引之后,只需要在索引里面去检索这条数据就行了,因为它是一
种特殊的专门用来快速检索的数据结构,我们找到数据存放的磁盘地址以后,就可以拿到数据了。
1.2 索引类型索引类型
普通索引(Normal):也叫非唯一索引,是最普通的索引没有任何的限制。
create index index_name on table(column(length));
alter table table_name add index index_name on column(length);
--创建表的时候直接指定
CREATE TABLE table(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
如果是CHAR,VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length。
唯一索引(Unique):唯一索引要求键值不能重复。另外需要注意的是,主键索引是一种特殊的唯一索引,它还多了一个限制条件,要求键值不能为空。主键
索引用primary key 创建。唯一索引的创建方式和普通索引的相似,只需加上在前面加上unique就行
全文索引(Fulltext): 针对比较大的数据,比如我们存放的是消息内容,有几KB的数据的这种情况,如果要解决like查询效率低的问题,可以创建全文索引。
只有文本类型的字段才可以创建全文索引,比如char、varchar、text。MyISAM和InnoDB支持全文索引。
2.索引存储模型推演索引存储模型推演
2.1 二叉查找树(二叉查找树(BST Binary Search Tree))
二叉查找树的左子树的所有节点都小于父节点,右子树所有的结点都大于父节点。投影到平面以后,就是一个有序的线性表。
二叉查找树既能够实现快速查找,又能够实现快速插入。
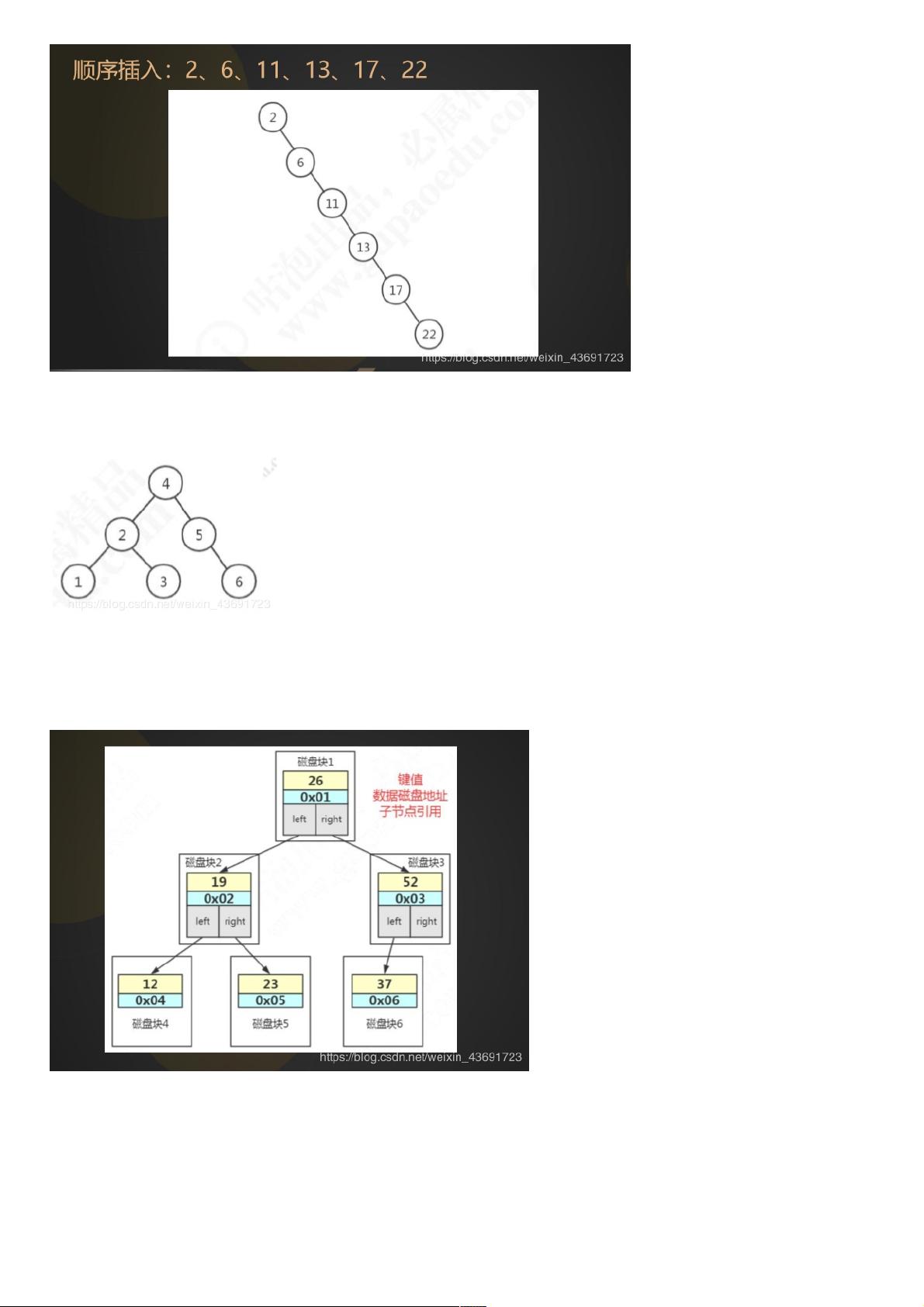
但是二叉查找树有一个问题:
就是它的查找耗时是和这棵树的深度相关的,在最坏的情况下时间复杂度会退化成O(n)。
什么情况是最坏的情况呢?
如果我们插入的数据刚好是有序的,2、6、11、13、17、22。它会变成链表(我们把这种树叫做“斜树”),这种情况下不能达到加快检索速度的目的,和顺序
查找效率是没有区别的。
剩余7页未读,继续阅读
资源评论


weixin_38675969
- 粉丝: 2
- 资源: 957











