

Spark技术解析及在百度开放云技术解析及在百度开放云BMR应用实践应用实践
2015年1月10日,一场基于Spark的高性能应用实践盛宴由Databricks软件工程师连城、百度高级工程师甄鹏、百度架构师孙
垚光、百度美国研发中心高级架构师刘少山四位专家联手打造。
2014年,Spark开源生态系统得到了大幅增长,已成为大数据领域最人气的开源项目之一,活跃在Hortonworks、IBM、
Cloudera、MapR和Pivotal等众多知名大数据公司,更拥有Spark SQL、Spark Streaming、MLlib、GraphX等多个相关项目。
同时值得一提的是,Spark贡献者中有一半左右的中国人。
短短四年时间,Spark不仅发展为Apache基金会的顶级开源项目,更通过其高性能内存计算及其丰富的生态快速赢得几乎所有
大数据处理用户。2015年1月10日,一场基于Spark的高性能应用实践盛宴由Databricks软件工程师连城、百度高级工程师甄
鹏、百度架构师孙垚光、百度美国研发中心高级架构师刘少山四位专家联手打造。
Databricks软件工程师连城软件工程师连城——Spark SQL 1.2的提升和新特性的提升和新特性
谈及Spark SQL 1.2的提升和新特性,连城主要总结了4个方面——External data source API(外部数据源API)、列式内存存
储加强(Enhanced in-memory columnar storage)、Parquet支持加强(Enhanced Parquet support)和Hive支持加强
(Enhanced Hive support)。
External data source API
连城表示,因为在处理很多外部数据源中出现的扩展问题,Spark在1.2版本发布了External data source API。通过External
data source API,Spark将不同的外部数据源抽象成一个关系表格,从而实现更贴近无缝的操作。
External data source API在支持了多种如JSON、Avro、CSV等简单格式的同时,还实现了Parquet、ORC等的智能支持;同
时,通过这个API,开发者还可以使用JDBC将HBase这样的外部系统对接到Spark中。
连城表示,在1.2版本之前,开发者其实已经实现了各种各样外部数据源的支持,因此,对比更原生的支持一些外部数据
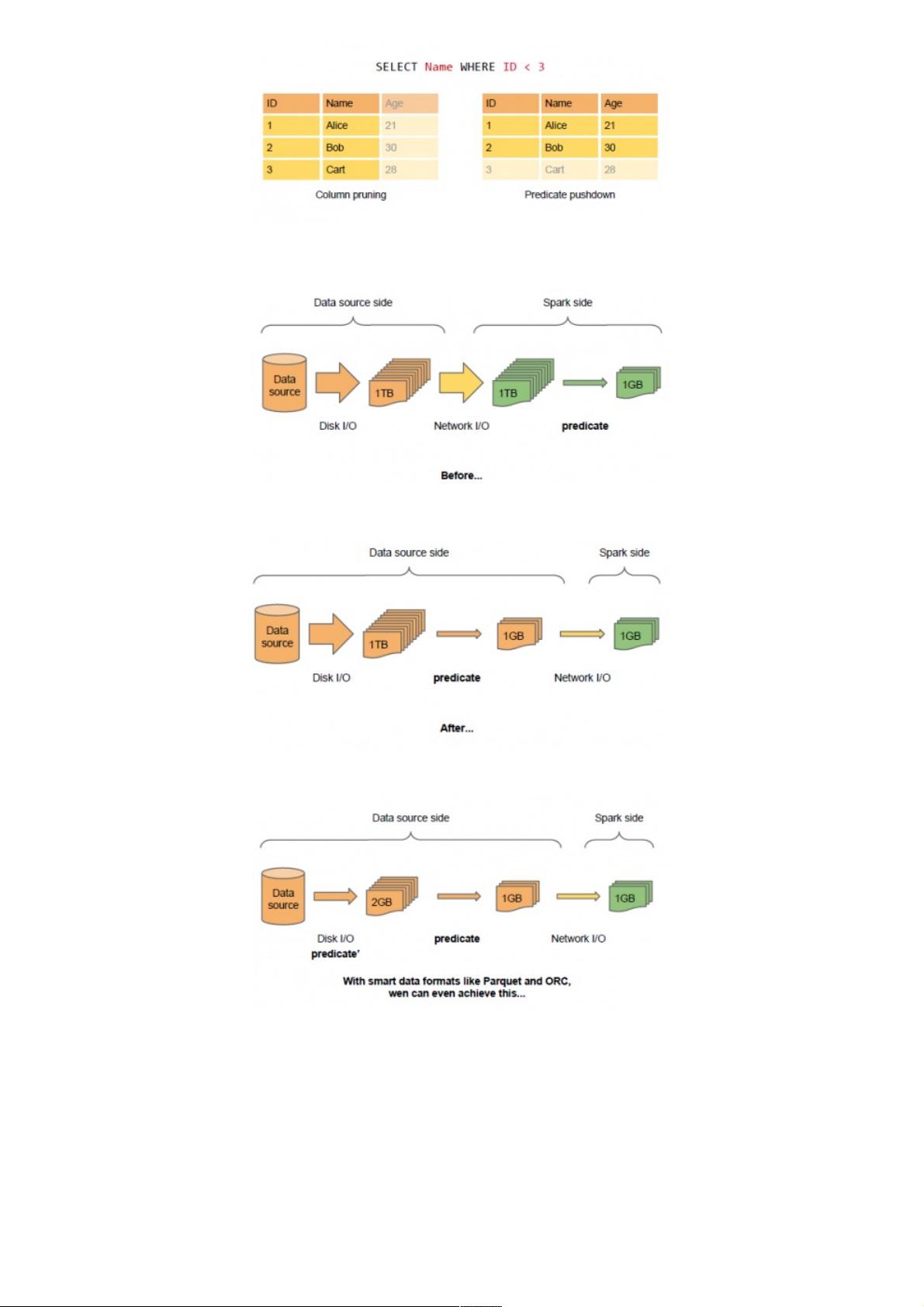
源,External data source API的意义更在于针对相应数据源进行的特殊优化,主要包括Column pruning(列剪枝)和Pushing
predicates to datasources(将predicates贴近数据源)两个方面:
Column pruning。。主要包括纵横的两种剪枝。在列剪枝中,Column pruning可以完全忽视无需处理的字段,从而显著地减少
IO。同时,在某些条件查询中,基于Parquet、ORC等智能格式写入时记录的统计信息(比如最大值、最小值等),扫描可以
跳过大段的数据,从而省略了大量的磁盘扫描负载。
剩余8页未读,继续阅读
资源评论


weixin_38672794
- 粉丝: 5
- 资源: 924









最新资源
- (dta格式)各县市区主要社会经济指标(1990-2022年)【重磅,更新】
- JiYuTrainer.rar
- 基于 Echarts.js+PyTorch+Celery+深度学习实现动力电池数据分析系统+项目源码+文档说明
- 【重磅,更新】2014-2024年全国监测站点的15个(空气质量;指标监测数据)
- 最全石头剪刀布数据集下载
- 中期检查+结项报告参考模板+教改类课题+开题报告【重磅,更新!】
- DGA(流量入侵)网络安全数据集
- 【毕业设计/课程设计】免费springbootvue阿博图书馆管理系统源码
- <项目代码>YOLOv8 手机识别<目标检测>
- 【毕业设计/课程设计】免费springboot+vue教师工作量管理系统源码
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


