
.NET Core中反解中反解ObjectId
主要介绍了.NET Core中实现ObjectId反解的方法,文中讲解非常细致,代码帮助大家更好的理解和学习,感兴
趣的朋友可以了解下
前言前言
在设计数据库的时候,我们通常需要给业务数据表分配主键,很多时候,为了省事,我都是直接使用 GUID/UUID 的方式,但
是在 MonggoDB 中,其内部实现了 ObjectId(以下统称为Oid)。并且在.NETCore 的驱动中给出了源代码的实现。
经过仔细研读官方的源码后发现,其实现原理非常的简单易学,在最新的版本中,阉割了 UnPack 函数,可能是官方觉得解包
是没什么太多的使用场景的,但是我们认为,对于数据溯源来说,解包的操作实在是非常有必要,特别是在目前的微服务大流
行的背景下。
为此,在参考官方代码的基础上进行了部分改进,增加了一下自己的需求。本示例代码增加了解包的操作、对 string 的隐式转
换、提供读取解包后数据的公开属性。
ObjectId 的数据结构的数据结构
首先,我们来看 Oid 的数据结构的设计。
从上图可以看出,Oid 的数据结构主要由四个部分组成,分别是:Unix时间戳、机器名称、进程编号、自增编号。Oid 实际上
是总长度为12个字节24的字符串,易记口诀为:4323,时间4字节,机器名3字节,进程编号2字节,自增编号3字节。
1、Unix时间戳:Unix时间戳以秒为记录单位,即从1970/1/1 00:00:00 开始到当前时间的总秒数。
2、机器名称:记录当前生产Oid的设备号
3、进程编号:当前运行Oid程序的编号
4、自增编号:在当前秒内,每次调用都将自动增长(已实现线程安全)
根据算法可知,当前一秒内产生的最大 id 数量为 2^24=16777216 条记录,所以无需过多担心 id 碰撞的问题。
实现思路实现思路
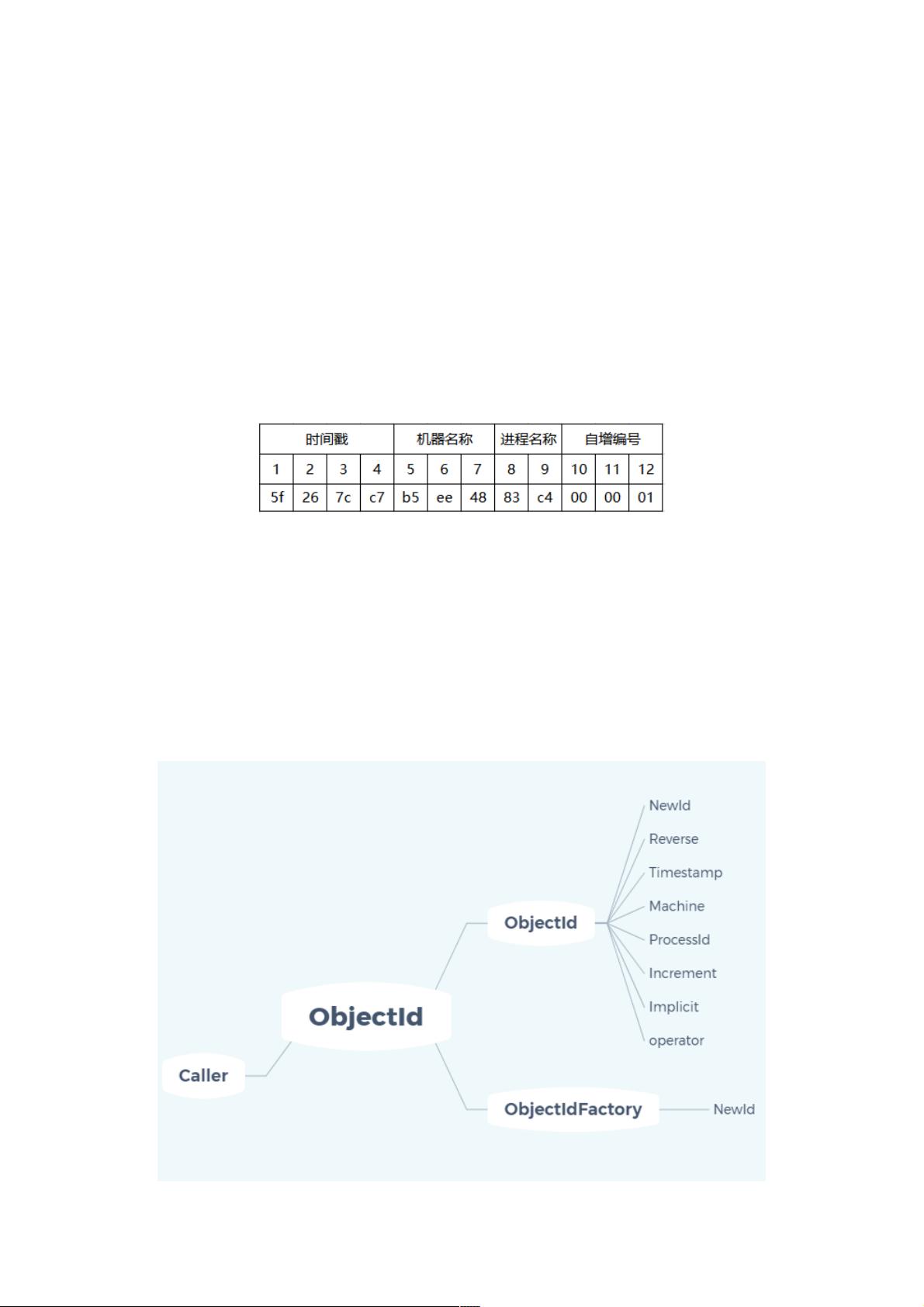
先来看一下代码实现后的类结构图。
通过上图可以发现,类图主要由两部分组成,ObjectId/ObjectIdFactory,在类 ObjectId 中,主要实现了生产、解包、计算、
转换、公开数据结构等操作,而 ObjectIdFactory 只有一个功能,就是生产 Oid。
资源评论













