
Pycharm+Scrapy安装并且初始化项目的方法安装并且初始化项目的方法
今天小编就为大家分享一篇Pycharm+Scrapy安装并且初始化项目的方法,具有很好的参考价值,希望对大家有
所帮助。一起跟随小编过来看看吧
前言前言
Scrapy是一个开源的网络爬虫框架,Python编写的。最初设计用于网页抓取,也可以用来提取数据使用API或作为一个通用的
网络爬虫。是数据采集不可必备的利器。
安装安装
pip install scrapy
如果使用上面的命令太慢。国内可以使用豆瓣源进行加速。
pip install -i https://pypi.douban.com/simple scrapy
注意要写错了,是 https://pypi.douban.com/simple 很多包都可以使用这个源进行加速,这也是pip的一个技巧,还可以使用阿
里云进行加速。
安装完成之后在命令行输入
scrapy -v
如果出现了相应的版本号就说明安装成功。
创建项目创建项目
目前还没有IDE 能够创建scrapy的项目,我们必须手动初始化项目。
1、找一个目录
输入命令
scrapy startproject SpiderObject
命令行出现这样的结果说明创建成果
You can start your first spider with:
cd SpiderObject
scrapy genspider example example.com
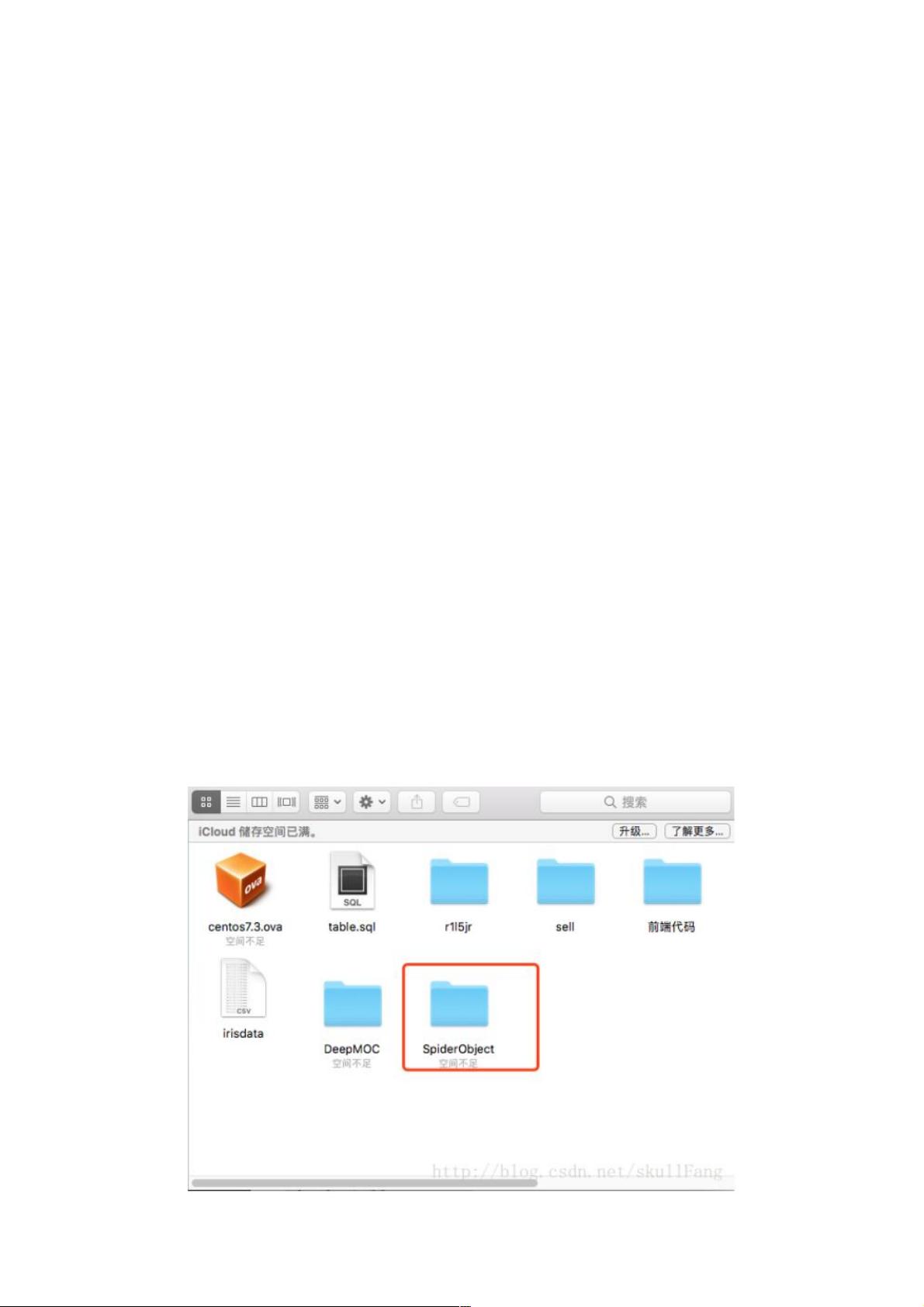
去文件夹中看看
初始化项目初始化项目
使用pycharm打开该项目
资源评论


weixin_38661939
- 粉丝: 5
- 资源: 949









最新资源
- 白色简洁风格的Zero企业网站模板.zip
- 白色简洁风格的奥迪mini跑车企业网站模板.zip
- 白色简洁风格的办公office企业网站模板下载.zip
- 白色简洁风格的办公管理后台系统源码下载.zip
- 白色简洁风格的办公室装修公司企业网站模板.zip
- 白色简洁风格的办公平台登录表源码下载.zip
- 白色简洁风格的办公室室内设计门户网站模板下载.zip
- 白色简洁风格的别墅设计装修整站网站模板.zip
- 白色简洁风格的别墅整站网站模板.zip
- 白色简洁风格的博客论坛后台系统源码下载.zip
- 白色简洁风格的餐厅菜品系列源码下载.zip
- 白色简洁风格的博客论坛后台统计源码下载.zip
- 白色简洁风格的餐厅会员登录框源码下载.zip
- 白色简洁风格的餐厅服务团队整站网站源码下载.zip
- 白色简洁风格的餐厅美味食谱整站网站源码下载.zip
- 白色简洁风格的餐饮食材食谱整站网站源码下载.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


