
机器学习机器学习—K-近邻算法近邻算法[入门入门]
k-近邻算法近邻算法(k-Nearest Neighbour algorithm),又称为KNN算法,是数据挖掘技术中原理最简单的算法。
KNN的工作原理的工作原理:给定一个已知标签类别的训练数据集,输入没有标签的新数据后,在训练数据集中找到与新数据最邻
近的k个实例,如果这k个实例的多数属于某个类别,那么新数据就属于这个类别。可以简单理解为:由那些离X最
近的k个点来投票决定X归为哪一类。
k-近邻算法步骤近邻算法步骤:
1.计算已知类别数据集中的点与当前点之间的距离
2.按照距离递增次序排序
3.选取与当前点距离最小的k个点
4.确定前k个点所在类别的出现频率
5.返回前k个点出现频率最高的类别作为当前点的预测类别
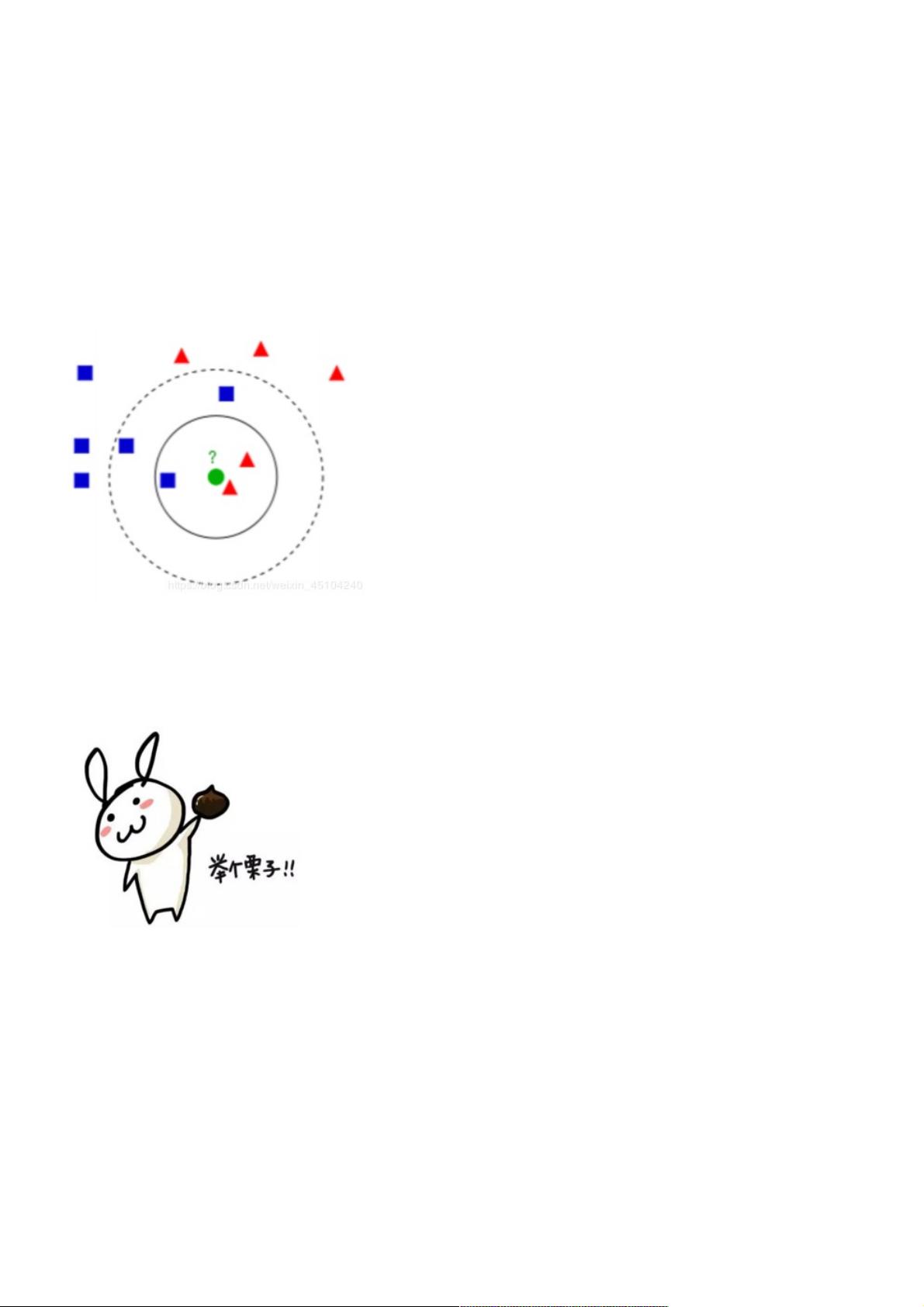
没听懂?我们借图说话。
图中有红色三角和蓝色方块两种类别,我们现在需要判断绿色圆点属于哪种类别。
当k=3时,绿色圆点属于红色三角这种类别;
当k=5时,绿色圆点属于蓝色方块这种类别(蓝色方块数量为3,大于红色三角的数量)。
是不是很简单?
我们再举个栗子我们再举个栗子
电影类型分类电影类型分类
通过电影中出现的打斗镜头和接吻镜头的数量来预测该电影的类型。
资源评论













