
代码实例讲解代码实例讲解python3的编码问题的编码问题
在本篇内容里小编给各位分享了关于python3的编码问题以及相关实例代码,有需要的朋友们参考一下。
python3的编码问题。的编码问题。
打开python开发工具IDLE,新建‘codetest.py'文件,并写代码如下:
import sys
print (sys.getdefaultencoding())
F5运行程序,打印出系统默认编码方式
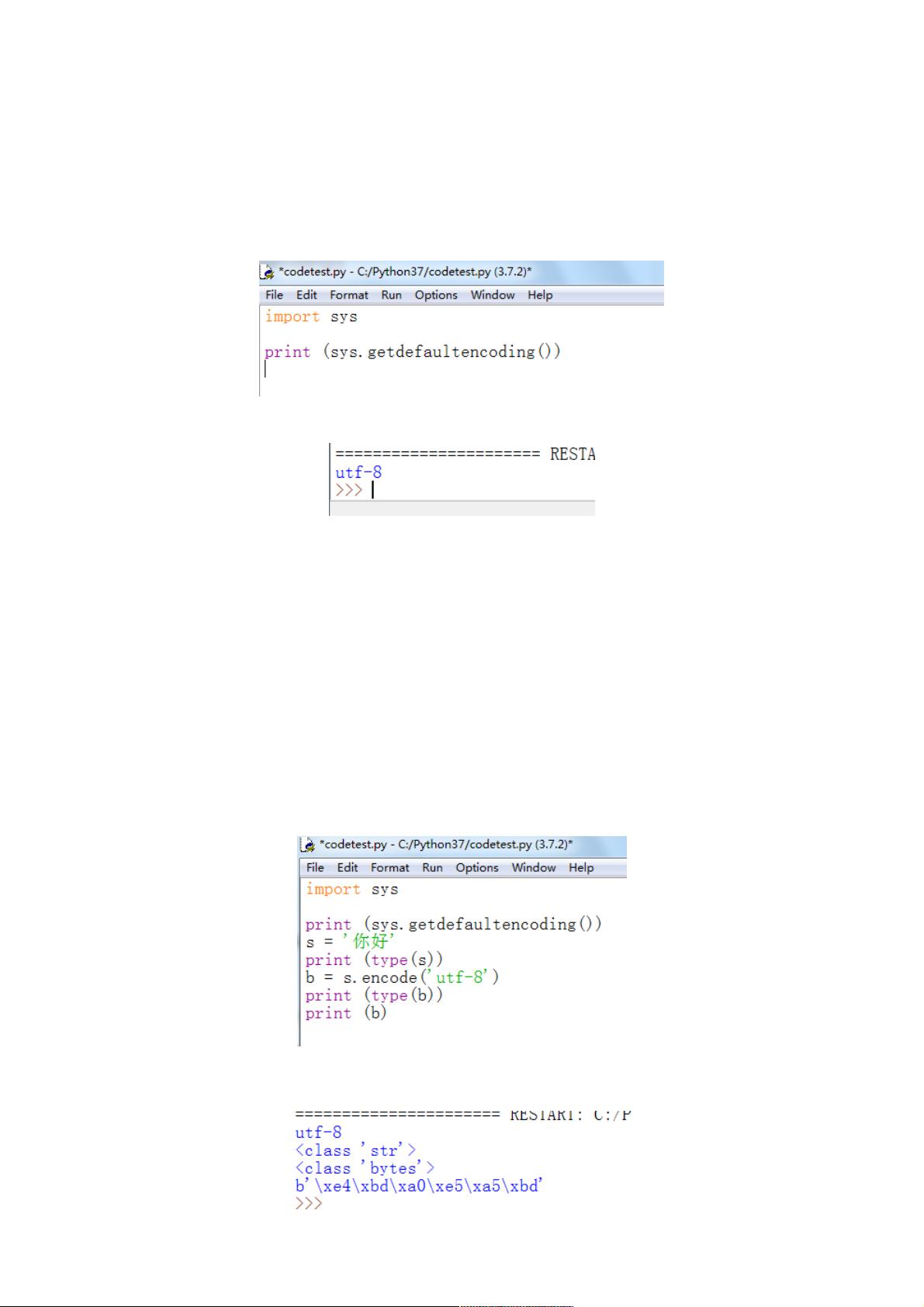
将字符串从str格式编码程bytes格式,修改代码如下:
import sys
print (sys.getdefaultencoding())
s = '你好'
print (type(s))
b = s.encode('utf-8')
print (type(b))
print (b)
其中b = s.encode('utf-8') 等同于b = s.encode() ,因为系统默认编码方式就是utf-8
F5运行程序,打印出内容如下,中文必须用utf-8编码,因为ascii码表示不了所有汉字,这里暂时不介绍gbk编码,现在用得很
少了,utf-8使用3个字节表示一个汉字,ascii使用一个字节表示一个英文字母或字符。
解码就是从bytes变回str的过程,修改代码如下:
资源评论


weixin_38654315
- 粉丝: 5
- 资源: 962









最新资源
- 基于java的摄影跟拍预定管理系统设计与实现.docx
- 基于java的协同过滤算法的体育商品推荐系统设计与实现.docx
- 基于java的私人健身与教练预约管理系统设计与实现.docx
- 基于java的校园二手书交易管理系统设计与实现.docx
- 基于java的学生成绩管理系统设计与实现.docx
- 基于java的休闲娱乐代理售票系统设计与实现.docx
- 基于java的学生信息管理系统设计与实现.docx
- 基于java的学生综合测评系统设计与实现.docx
- 基于java的饮食分享平台设计与实现.docx
- 基于java的医院信管系统设计与实现.docx
- 基于小程序的疫情核酸预约小程序源码(小程序毕业设计完整源码).zip
- 基于java的在线考试设计与实现.docx
- 基于java的智慧学生校舍系统设计与实现.docx
- 基于java的智慧党建系统设计与实现.docx
- html新年烟花代码效果
- 基于小程序的童心党史小程序源码(小程序毕业设计完整源码).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


