

USDA食品数据库食品数据库
USDA食品数据库食品数据库
!git clone https://github.com/wesm/pydata-book
0 导入相关库导入相关库
# 基础
import numpy as np # 处理数组
import pandas as pd # 读取数据&&DataFrame
import matplotlib.pyplot as plt # 制图
import seaborn as sns
from matplotlib import rcParams # 定义参数
from matplotlib.cm import rainbow # 配置颜色
%matplotlib inline
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
np.set_printoptions(precision=4) # 小数点后
pd.options.display.max_rows = 10 # 最大行数
1 读取文本文件读取文本文件(JSON、字典格式、字典格式)
import json
db = json.load(open('pydata-book/datasets/usda_food/database.json'))
len(db)
db[0]
db[0].keys()
db中的每个条目都是一个含有某种食物全部数据的字典
db[0]['nutrients'][0]
nutrients字段是一个字典 列表,其中的每个字典对应一种营养成分
2 数据预处理数据预处理
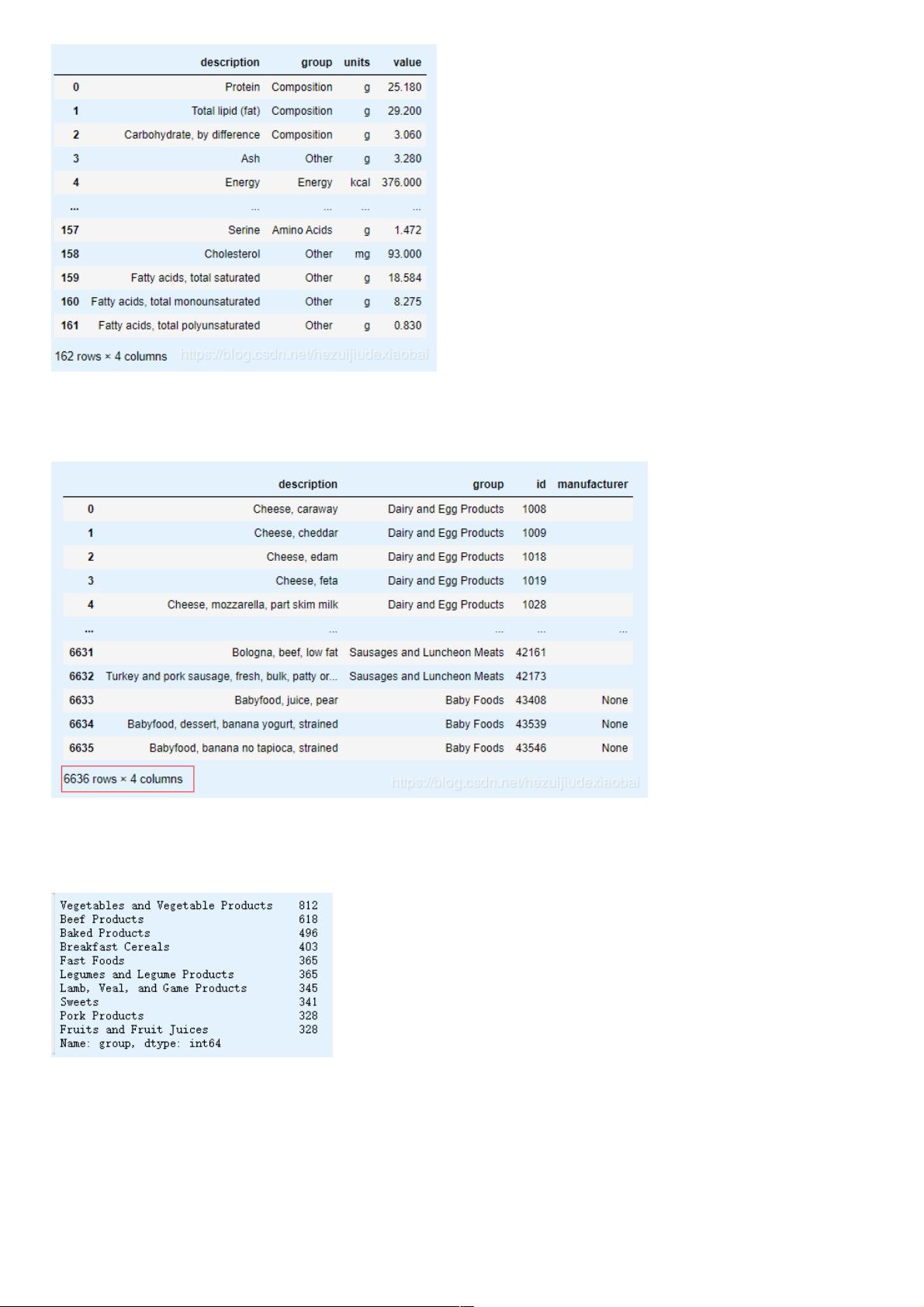
nutrients = pd.DataFrame(db[0]['nutrients'])
nutrients
剩余7页未读,继续阅读

weixin_38654220
- 粉丝: 10
- 资源: 931









最新资源
- 压装活塞及安装矩形圈设备sw16可编辑全套技术资料100%好用.zip.zip
- 基于Java、JavaScript、HTML、CSS的四方保险项目二设计源码
- 基于JavaScript的retire.js设计源码,用于检测JS库版本中的已知漏洞
- 基于Vue2全家桶的Springboot城市流动人口管理系统设计源码
- 电子学习资料设计作品全资料新型消防车的研究
- 基于工作与兴趣积累的JavaScript前端插件库设计源码
- 基于Vue框架的天津大学TJU软件工程elm外卖平台设计源码
- 电子学习资料设计作品全资料遥控系统的设计资料
- 基于Lua语言的【流云阁】中二国战在【新月杀】平台的设计与实现源码
- 基于Python语言的手机租借平台后端设计源码
- 基于Java、Lua、HTML混合技术的电影项目后端设计源码
- 电子学习资料设计作品全资料音频信号分析仪资料
- 基于Unity3D引擎的3D空间与地面A*寻路算法设计源码
- 基于TypeScript的Vue前端脚手架设计源码
- 基于深度学习的电影评论情感分析系统源代码(python毕业设计完整源码+LW).zip
- 新款开箱机(proe5.0+cad)全套技术资料100%好用.zip.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0