移动图形处理器的纹理Cache设计
147 浏览量
2020-10-15
21:55:23
上传
评论
收藏 510KB PDF 举报

移动图形处理器的纹理移动图形处理器的纹理Cache设计设计
为了提高移动图形处理器中统一架构染色器的效率,减少其与片外存储器间的访问次数,提出了一种4端口纹理
高速缓存结构。该结构采用基于Mipamp算法的纹理映射和基于细化层次(Level of Detail,LOD)选择不同单
端口Cache的存储方式,提高了纹理Cache的命中率。此外为了提高数据吞吐率,采用4端口并行读取纹素。设
计了FIFO缓冲区预取数据,降低访存延迟。利用SV搭建实验平台对纹理图像进行测试,结果表明纹理Cache的
平均命中率为92.5%,数据吞吐率接近单端口Cache的4倍。
0 引言引言
随着手机、PAD等移动设备进一步普及,对3D图形绘制的需求也越来越大。桌面GPU相较于移动GPU,其渲染流程简单直
接、数据吞吐率高,进而带宽需求高,功耗大。文献[1]指出相比于集成电路按照摩尔定律的发展速度,电池供电技术发展得
缓慢得多,移动设备最基本的问题是电池供电。在移动设备中,由于图形应用于液晶显示器上,因此图形渲染时系统功耗大,
软件的优化是有限的,所以对硬件的低功耗设计是研究的重点,进而达到移动设备在低带宽功耗的条件下实现较高性能的渲染
效果。
纹理映射是纹理空间与像素空间相互映射的过程,在对纹理图形进行放大或缩小时,会出现单纹素对应多像素或多纹素对
应单像素的情况,造成纹理走样的现象。因此,行业内权威共同制定了适用于嵌入式的3D图形标准OpenGL ES
[2]
,其使用各
向同性滤波方式。该方式中的最近邻点采样滤波因没有考虑到纹理映射的范围,容易产生锯齿现象;该方式中的双线性滤波虽
然有效地减少了锯齿问题,但容易造成模糊现象;该方式中的Mipmap滤波是经典的映射方法;最后的三线性滤波是对
Mipmap滤波的优化,所以本文选择了三线性滤波。因为双线性滤波是对邻近d的一层纹理图像中相邻的四个纹素位置进行采
样,三线性滤波是对邻近d的两层纹理图像分别进行双线性滤波,并将两层的双线性滤波加权,进而双线性滤波是三线性滤波
的简化,本文以下用双线性进行说明。
纹理访存是影响像素处理器速率的关键,同样也是移动GPU整体性能的瓶颈。加上片上纹理高速缓冲存储器,建立关于纹
素的片上L1缓存,有效降低了移动GPU与外存间的数据带宽。纹理Cache与普通Cache的不同:首先,纹理Cache为只读,区
别于普通Cache的写数据和写回功能;其次,纹理Cache的吞吐率同移动GPU整体性能结合紧密,本文结合双线性滤波需要四
纹素的特点,使用4端口Cache。纹理Cache是流水线形式,本文使用FIFO控制器控制FIFO缓冲区预存块的读写,减少了移动
GPU流水线的停顿。
1 基于基于Tile-based的移动图形处理架构的移动图形处理架构
Imagnination公司PowerVR系列产品的移动GPU采用文献[3]提出的TBR(Tile Based Rendering)渲染模式,在几何运算后
将屏幕像素点划分为多个Tile,并在像素处理器中逐Tile进行渲染。相比于适用于桌面图形处理器的立即渲染模式(Immediate
Mode Rendering,IMR),TBR渲染模式在执行光栅化和图元操作时可以将每个Tile上所有的深度及颜色等信息都存在片上,
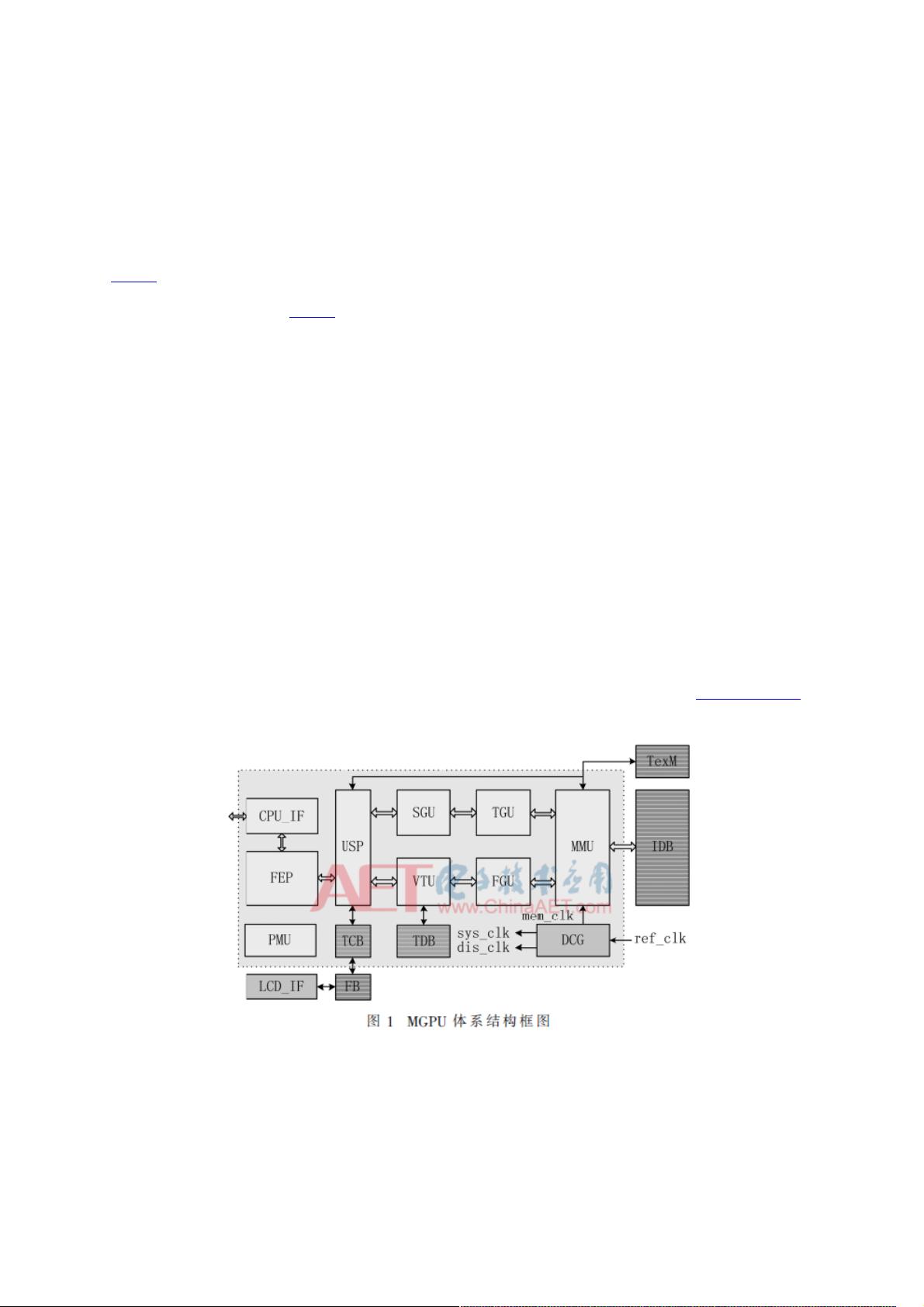
显著降低了存储带宽。文献[4]指出移动GPU主要的功耗来源于访问片外存储,所以TBR模式适用于移动图形处理器。图1为本
文移动图形处理器的体系结构。
整个移动GPU采用了统一架构,即几何变换操作、顶点坐标的光照计算和着色渲染都在统一渲染染色器(Unified Shading
Processor,USP)中完成;屏幕坐标产生单元(Screen-coordinate Generating Unit,SGU)完成几何处理后顶点的图元装
配、裁剪、背面剔除等操作,转换到屏幕空间;后续模块为覆盖率计算、中间数据缓存建立等;最终通过深度测试输出给帧缓
存。TBR渲染模式中,Tile的大小有8×8、16×16、32×32等多种划分方式,文献[5]指出当Tile大小为8×8时,纹理Cache的性
能可以达到最优,但从移动GPU整体性能方面考虑,一般应采用Antoeh
[6]
建议的32×32大小的Tile。
2 纹理滤波纹理滤波
纹理映射是将二维图像投影到屏幕的三角形上,在移动GPU中,这一过程是逆向处理的,即对每个在屏幕上的像素点,计
算其对应于二维图像中的纹理坐标。但屏幕空间对应到纹理空间时,不一定恰好对应到一个纹素,而是对应到纹理空间中某个
区域,这时就需要对该区域中的纹素进行加权计算,这就是滤波。






评论0
最新资源