
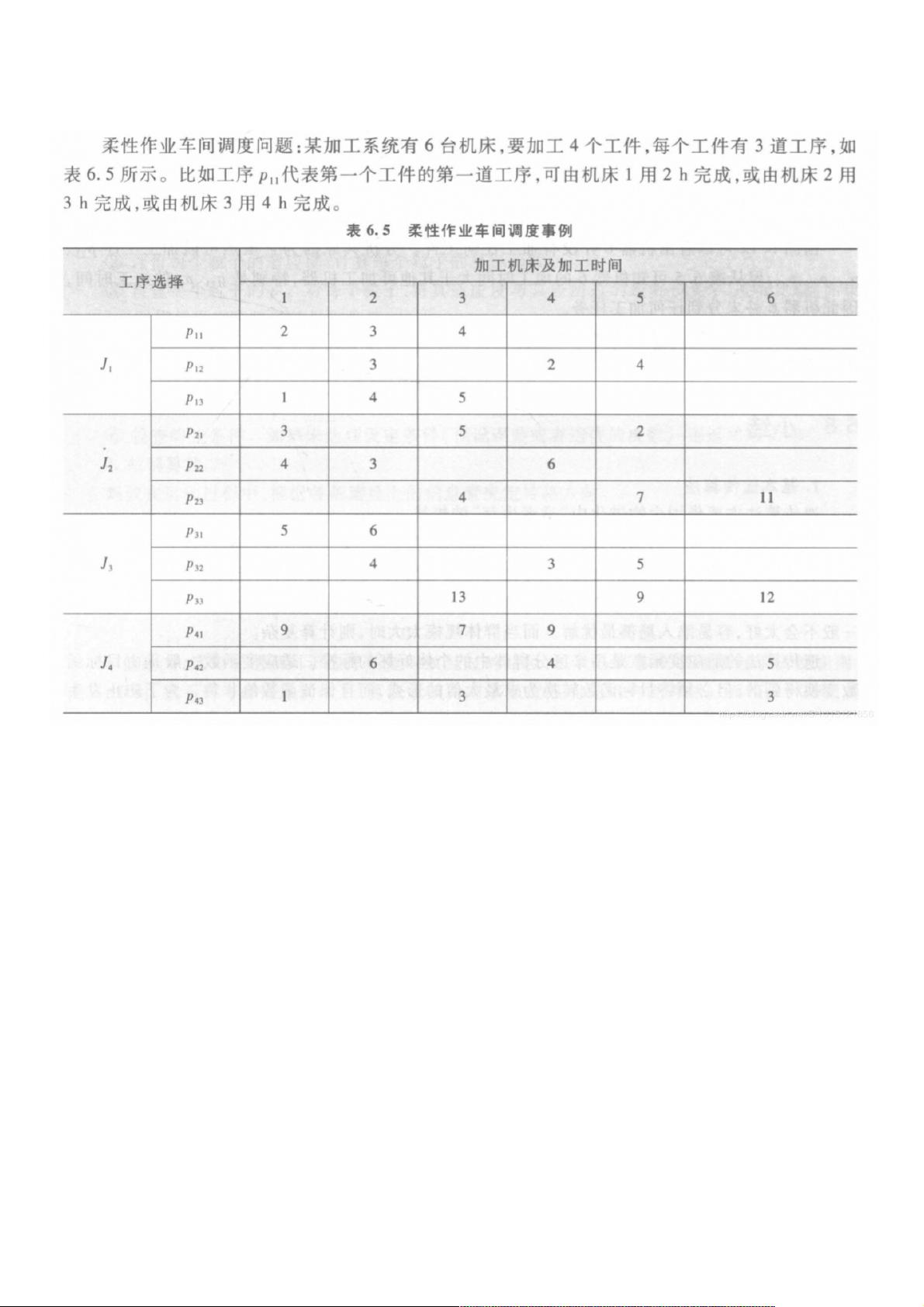
【算法学习笔记】【算法学习笔记】5:基于蚁群算法的柔性作业车间调度问题:基于蚁群算法的柔性作业车间调度问题(FJSP)快速求解快速求解
简述简述
这是《深度学习与人工智能》课程中很普通的一道作业题,但因为发现了一个更巧妙的搜索目标的形式,让求解过程快了很多,代码实现起来也简单了非常多,而且最终的搜索效果
也更好。
关于蚁群算法和柔性作业车间调度问题不再赘述。
求解策略比较求解策略比较
如果用这篇文章中的方法,求解这个问题会很困难。因为同同Job的不同工序是有先后顺序的的不同工序是有先后顺序的,如果直接在上面这张表里搜索解,也就是说搜索出的是这张表里每一行标一个机器,那
么接下来的时间计算就非常麻烦,需要从这张表去计算一个最优的调度顺序,这个过程代价很高,而且程序很难写。
在这篇文章中看到了一种搜索目标的表示形式,这篇文章虽然是讲遗传算法而不是蚁群算法,但是它对遗传算法染色体的编码方法可以借鉴(见其3.2节)。
类似于它所述的编码方式,这里把搜索目标分成两部分。
一部分是topo_jobstopo\_jobstopo_jobs,这是一个列表,表示所有工序pijp_{ij}pij一个顺序,即所有工序扔上机器的次序(暂时不用管是扔给哪个机器),这样就可以在逐步生成它的在逐步生成它的
时候确定和保证工序的次序了时候确定和保证工序的次序了。
另一部分是process2machineprocess2machineprocess2machine,这是一个二维列表,第一层是Job,第二层是工序,里面存的就是这个工序要放到哪台机器上。
使用这两个部分作为搜索目标,时间的计算就非常方便,只要想象有机器数量这么多的栈,然后依次把每个工序压到它要到的机器对应的栈里面去,同时根据这些栈当前栈顶的情况
来知道这个工序的开始时间。不过实际实现时候是不需要真的有这个栈的。
另外,因为有这两个搜索目标,所以要有两张和它们相对应的信息素浓度表要有两张和它们相对应的信息素浓度表,每轮迭代完成之后这两张表都要更新。
程序实现程序实现
为了作业方便,下面的程序中假定所有Job的工序数量都是一样多的。对于更一般的情况,只需要把process_num改成一个列表,然后对应的地方稍作修改。
"""
柔性作业车间调度问题
(Flexible Job-shop Scheduling Problem, FJSP)
"""
import numpy as np
import random
from typing import List
from matplotlib import pyplot as plt
plt.rcParams['font.family'] = ['sans-serif'] plt.rcParams['font.sans-serif'] = ['SimHei']
# 作业数,统一工序数,机器数
job_num = 4
process_num = 3
machine_num = 6
# 4个Job的3个工序在6台机器上的加工时间
times = [
[
[2, 3, 4, None, None, None],
[None, 3, None, 2, 4, None],
[1, 4, 5, None, None, None] ],

weixin_38637805
- 粉丝: 4
- 资源: 952









最新资源
- (176023044)海康NVR开发SDK,sdk开发文档
- 国土空间规划信息平台建设方案与关键技术解析
- (2782218)学生信息管理系统(基于java)
- (175218226)利用仿真实现定时器设计的门铃
- (176797002)大华平台SDK接口手册(C++版)
- 手机配件自动摆盘上料机sw17可编辑全套技术资料100%好用.zip
- (177533624)python-考试管理系统,考题管理,自动阅卷等 .zip
- (8772844)时钟芯片DS1302通讯C代码
- Arthas是阿里巴巴开源的Java诊断工具 Arthas支持JDK6+,支持Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的Tab自动补全功能,进一步方便进行问题的定位和诊断
- (173447814)springboot房产中介系统 (源码+数据库)312341
- 【锂电池剩余寿命预测】CNN-Transformer锂电池剩余寿命预测,马里兰大学锂电池数据集(Pytorch完整源码和数据)
- (179617412)永磁同步电机无位置传感器控制,采用的是龙贝格,基于模型的 定点开发,仿真效果和实际95%高度吻合,可以仿真学习,也可以直接移植到
- (179845616)智慧养老中心管理系统 JAVA毕业设计 源码+数据库+论文+启动教程(SpringBoot+Vue.JS).zip
- (179719648)智慧养老平台 SSM毕业设计 源码+数据库+论文(JAVA+SpringBoot+Vue.JS).zip
- 语音通话降噪-常用测试音频分享
- 水果分拣机15可编辑全套技术资料100%好用.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论4