
单片机与单片机与DSP中的基于中的基于DSP的高速实时语音识别系统的设计的高速实时语音识别系统的设计
实时语音识别系统中,由于语音的数据量大,运算复杂,对处理器性能提出了很高的要求,适于采用高速DSP
实现。虽然DSP提供了高速和灵活的硬件设计,但是在实时处理系统中,还需结合DSP器件的结构及工作方
式,针对语音处理的特点,对软件进行反复优化,以缩短识别时间,满足实时的需求。因此如何对DSP进行优
化编程,解决算法的复杂性和硬件存储容量及速度之间的矛盾,成为实现系统性能的关键。本文基于
TMS320C6713设计并实现了高速实时语音识别系统,在固定文本的说话人辨识的应用中效果显著。 1 语音识别
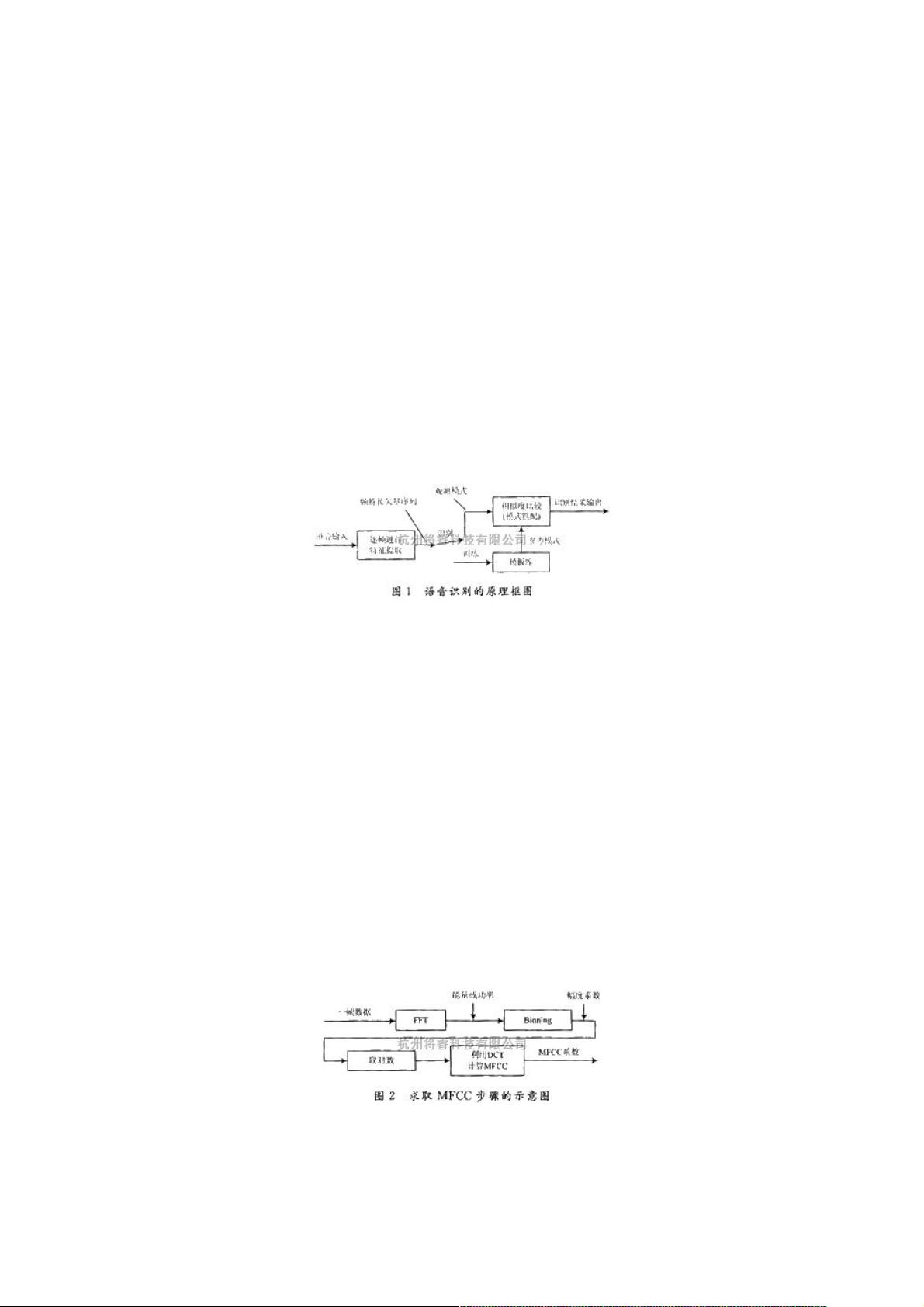
的原理 语音识别的基本原理框图如图1所示。语音信号中含有丰富的信息,从中提取对语音识别有用的信息
的过程
实时语音识别系统中,由于语音的数据量大,运算复杂,对处理器性能提出了很高的要求,适于采用高速DSP实现。虽
然DSP提供了高速和灵活的硬件设计,但是在实时处理系统中,还需结合DSP器件的结构及工作方式,针对语音处理的特
点,对软件进行反复优化,以缩短识别时间,满足实时的需求。因此如何对DSP进行优化编程,解决算法的复杂性和硬件存
储容量及速度之间的矛盾,成为实现系统性能的关键。本文基于TMS320C6713设计并实现了高速实时语音识别系统,在固定
文本的说话人辨识的应用中效果显著。
1 语音识别的原理语音识别的原理
语音识别的基本原理框图如图1所示。语音信号中含有丰富的信息,从中提取对语音识别有用的信息的过程,就是特征提
取,特征提取方法是整个语音识别系统的基础。语音识别的过程可以被看作足模式匹配的过程,模式匹配是指根据一定的准
则,使未知模式与模型库中的某一模型获得最佳匹配。
1.1 MFCC
语音识别中对特征参数的要求是:
(1) 能够有效地代表语音特征;
(2) 各阶参数之间有良好的独立性;
(3) 特征参数要计算方便,保证识别的实时实现。
系统使用目前最为常用的MFCC(Mel FrequencyCepstral Coefficient,美尔频率倒谱系数)参数。
求取MFCC的主要步骤是:
(1) 给每一帧语音加窗做FFT,取出幅度;
(2) 将幅度和滤波器组中每一个三角滤波器进行Binning运算;
(3) 求log,换算成对数率;
(4) 从对数率的滤波器组幅度,使用DCT变换求出MFCC系数。
本文中采用12阶的MFCC,同时加过零率和delta能量共14维的语音参数。
1.2 DTW
语音识别中的模式匹配和模型训练技术主要有DTW(Dynamic Time Warping,动态时间弯折)、HMM(HideMarkov
Model,隐马尔科夫模型)和ANN(Artificial Neu-ral Network,人工神经元网络)。
DTW是一种简单有效的方法。该算法基于动态规划的思想,解决了发音长短不一的模板匹配问题,是语音识别中出现较
资源评论


weixin_38632797
- 粉丝: 6
- 资源: 946









最新资源
- Redis核心数据结构解析:字符串与列表的实现及应用场景
- PyTorch模型部署与服务化:模型导出优化、容器化、服务化架构及安全措施
- 基于储能的直驱风电机组并网仿真模型 直驱风电机组,先整流后逆变,不控整流器?pwm控制逆变器,出口电压380v,蓄电池储能经dcdc变器接入直流母线,可控制充放电,直流母线接有直流负载,可做加减负载突
- Go实战全家桶之三十三: go pprof定位问题,自己埋的坑
- Go实战全家桶之三十三: go pprof定位问题,自己埋的坑
- MATLAB代码:用于平抑可再生能源功率波动的储能电站建模及评价 关键词:储能电站 功率波动 并网 平抑可再生能源 参考文档:《用于平抑可再生能源功率波动的储能电站建模及评价》仅参考 光伏发电容量可
- STM32驱动lcd1602显示adc采集电压显示程序源码 主控芯片采用stm32f103,包括程序源码和protues仿真protues版本8.8. 需要做AD转的不要错过 程序源码注释详细,非
- 三相UPS不间断电源 从工频交流电开始,完成三相桥式整流电路、升压斩波电路及三相桥式PWM逆变电路的交-直-交变整个流程 类似于一个UPS对输入电源的变过程
- sTM32 ADC采集滤波算法,卡尔曼 中位值 同步对比输出源程序,芯片采用STM32f103c8t6.算法采用卡尔曼滤波算法中位值滤波算法, 波形输出正常采集的卡尔曼 中位值三个波形输出,程序注释详
- MMC并网逆变器(滑模控制) 1.MMC工作在整流侧,子模块个数N=22, 直流侧电压Udc=11kV,交流侧电压6.6kV 2.控制器采用双闭环控制,外环控制有功功率,采用PI调节器,电流内环采用无
- 2023-04-06-项目笔记 - 第三百七十二阶段 - 4.4.2.370全局变量的作用域-370 -2025.01.08
- 西门子界面官方精美触摸屏+WINCC程序模板 西门子官方触摸屏程序模板,炫酷的扁平式动画效果,脚本动画,自动生成二维码,可仿真,堪比智能手机,有精简,精致,wincc,无线面板等包含了所有西门子人机界
- 永磁同步电机的脉振高频注入仿真,可实现零速带满载启动,转速估算精度与角度估算精度非常高
- 双 向 绑 定~~~~~~~~~~~~~~~~~~~~~~~~
- bugreport-2025-01-08-220002.zip
- 高通量计算(Pandat代算或自己操作) 高通量计算筛选材料 实例6:在 Ni-xCr-yAl (x=10-100,y=10-100)成分空间中,合金的液相线、固相线、相含量的变化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


