

异步并行批处理框架设计的一些思考异步并行批处理框架设计的一些思考
随着互联网信息技术日新月异的发展,一个海量数据爆炸的时代已经到来。如何有效地处理、分析这些海量的数据
资源,成为各大技术厂商争在激烈的竞争中脱颖而出的一个利器。可以说,如果不能很好的快速处理分析这些海量的
数据资源,将很快被市场无情地所淘汰。当然,处理分析这些海量数据目前可以借鉴的方案有很多:首先,在分布式
计算方面有Hadoop里面的MapReduce并行计算框架,它主要针对的是离线的数据挖掘分析。此外还有针对实时在线
流式数据处理方面的,同样也是分布式的计算框架Storm,也能很好的满足数据实时性分析、处理的要求。最后还有
Spring Batch,这个完全面向批处理的框架,可以大规模的应用于企业级的海量数据处理。
在这里,我就不具体展开说明这些框架如何部署、以及如何开发使用的详细教程说明。我想在此基础上更进一
步:我们能否借鉴这些开源框架背后的技术背景,为服务的企业或者公司,量身定制一套符合自身数据处理要求的批
处理框架。
首先我先描述一下,目前我所服务的公司所面临的一个用户数据存储处理的一个现状背景。目前移动公司一个省
内在网用户数据规模达到几千万的规模数量级,而且每个省已经根据地市区域对用户数据进行划分,我们把这批数据
存储在传统的关系型数据库上面(基于Oracle,地市是分区)。移动公司的计费结算系统会根据用户手机话费的余额
情况,实时的通知业务处理系统,给手机用户进行停机、复机的操作。业务处理系统收到计费结算系统的请求,会把
要处理的用户数据往具体的交换机网元上派发不同的交换机指令,这里简单的可以称为Hlr停复机指令(下面开始本文
都简称Hlr指令)。目前面临的现状是,在日常情况下,传统的C++多进程的后台处理程序还能勉强的“准实时”地处理这
些数据请求,但是,如果一旦到了每个月的月初几天,要处理的数据量往往会暴增,而C++后台程序处理的效率并不
高。这时问题来了,往往会有用户投诉,自己缴费了,为什么没有复机?或者某些用户明明已经欠费了,但是还没有
及时停机。这样的结果会直接降低客户对移动运营商支撑的满意度,于此同时,移动运营商本身也可能流失这些客户
资源。
自己认真评估了一下,造成上述问题的几个瓶颈所在。
1.一个省所有的用户数据都放在数据库的一个实体表中,数据库服务器,满打满算达到顶级小型机配置,也可能无法
满足月初处理量激增的性能要求,可以说频繁的在一台服务器上读写IO开销非常巨大,整个服务器处理的性能低下。
2.处理这些数据的时候,会同步地往交换机物理设备上发送Hlr指令,在交换机没有处理成功这个请求指令的时候,只
能阻塞等待,进一步造成后续待处理数据的积压。
针对上述的问题,本人想到了几个优化方案。
1.数据库中的实体表,能不能根据用户的归属地市进行表实体的拆分。即把一台或者几台服务器的压力,进行水平拆
分。一台数据库服务器就重点处理某一个或者几个地市的数据请求?降低IO开销。
2.由于交换机处理Hlr指令的时候,存在阻塞操作,我们能不能改成:通过异步返回处理的方式,把处理任务队列中的
任务先下达通知给交换机,然后交换机通过异步回调机制,反向通知处理模块,汇报任务的执行情况。这样处理模块
就从主动的任务轮询等待,变成等待交换机执行结果的异步通知,这样它就可以专注地进行处理数据的派发,不会受
到某几个任务处理时长的限制,从而影响到后面整批次的数据处理。
数据库的实体表由于进行水平拆解,能不能做到并行加载?这样就会大大节约串行数据加载的处理时长。
3.并行加载出来的待处理数据最好能放到一个批处理框架里面,批处理框架能很好地根据要处理数据的情况,进行配
置参数调整,从而很好地满足实时性的要求。比如月初期间,可以加大处理参数的值,提高处理效率。平常的时候,
可以适当降低处理参数的取值,降低系统的CPU/IO开销。
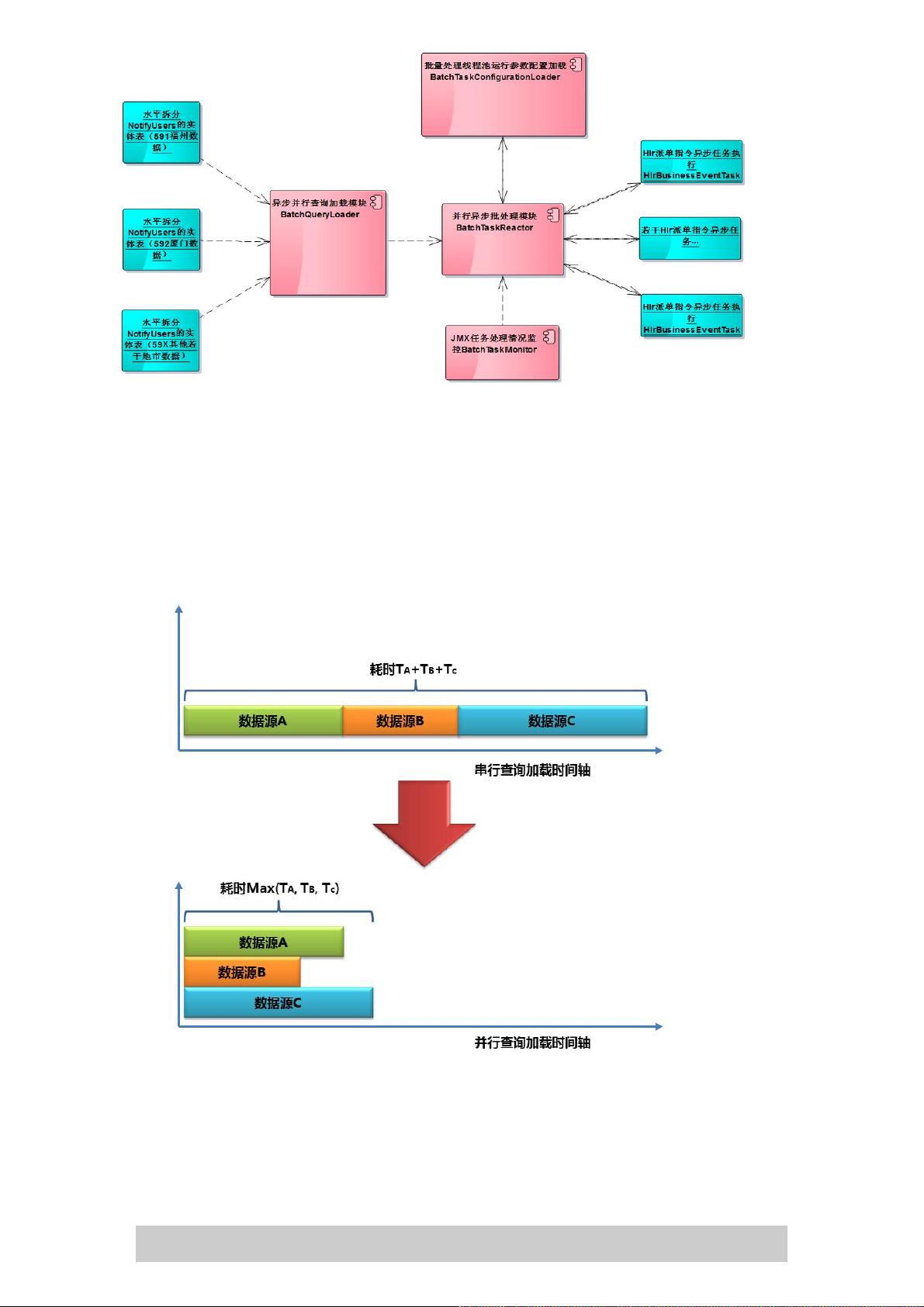
基于以上几点考虑,得出如下图所示的设计方案的组件图:


剩余48页未读,继续阅读
资源评论













