
Pandas之之drop_duplicates:去除重复项方法去除重复项方法
下面小编就为大家分享一篇Pandas之drop_duplicates:去除重复项方法,具有很好的参考价值,希望对大家有所
帮助。一起跟随小编过来看看吧
方法方法
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
参数参数
这个drop_duplicate方法是对DataFrame格式的数据,去除特定列下面的重复行。返回DataFrame格式的数据。
subset : column label or sequence of labels, optional
用来指定特定的列,默认所有列
keep : {‘first', ‘last', False}, default ‘first'
删除重复项并保留第一次出现的项
inplace : boolean, default False
是直接在原来数据上修改还是保留一个副本
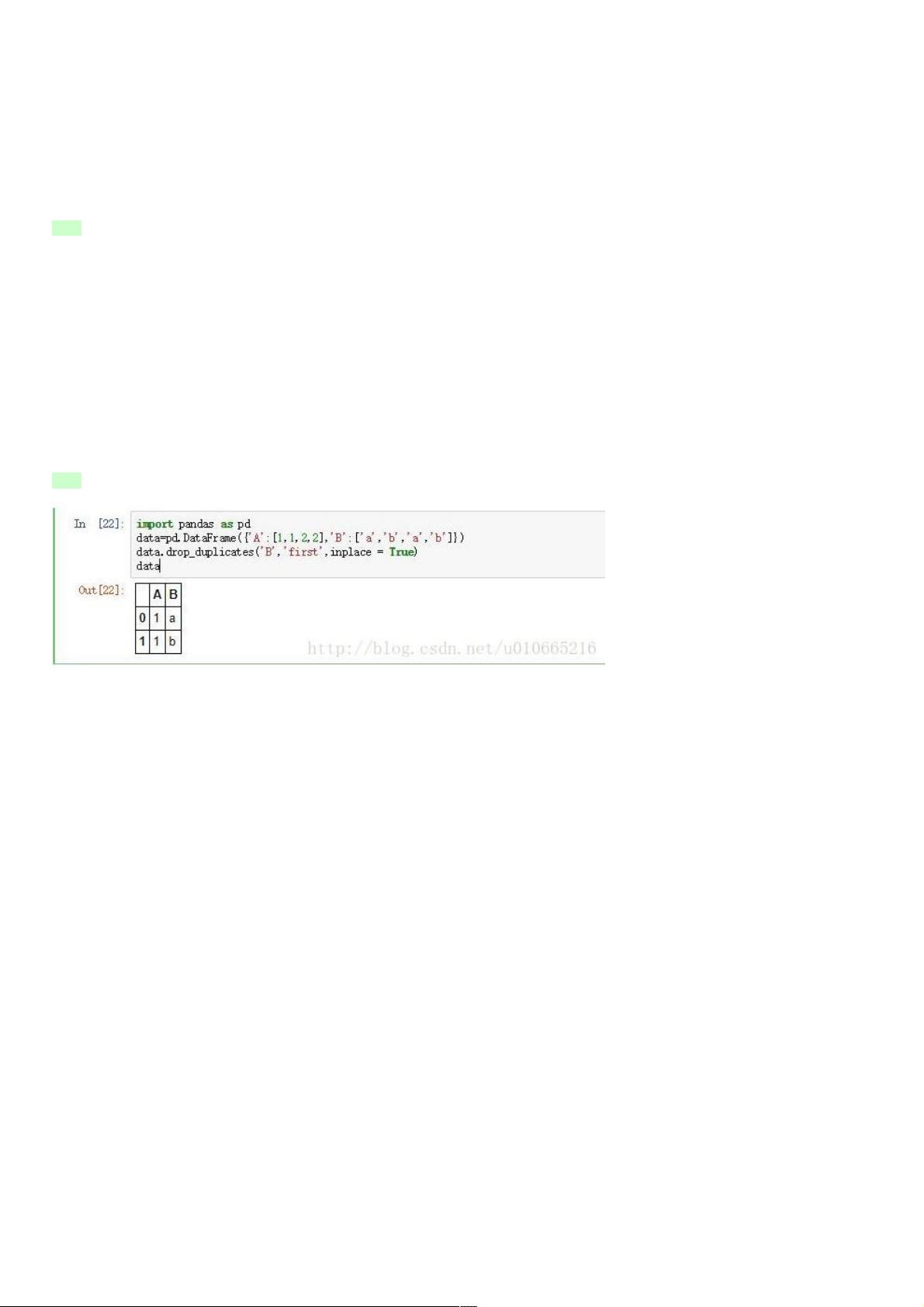
实验实验
以上这篇Pandas之drop_duplicates:去除重复项方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家
多多支持我们。

weixin_38630612
- 粉丝: 5
- 资源: 891









最新资源
- 塑料检测23-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- Python圣诞节倒计时与节日活动管理系统
- 数据结构之哈希查找方法
- 系统DLL文件修复工具
- 塑料、玻璃、金属、纸张、木材检测36-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- Python新年庆典倒计时与节日活动智能管理助手
- Nosql期末复习资料
- 数据结构排序算法:插入排序、希尔排序、冒泡排序及快速排序算法
- 2011-2024年各省数字普惠金融指数数据.zip
- 计算机程序设计员三级(选择题)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



- 1
- 2
前往页