

DeepFM代码详解及代码详解及Python实现实现
文章目录文章目录摘要一、数据预处理部分二、DeepFM部分1、FM部分的特征向量化2、Deep部分的权重设置3、网络传递部分4、
loss5、梯度正则6、完整代码三、执行结果和测试数据集
摘要摘要
DeepFM原理部分可以参看博客https://blog.csdn.net/weixin_45459911/article/details/105359982,本文就着重介绍其代码复现
部分的内容。
本文所写的代码参考自https://www.jianshu.com/p/71d819005fed,在此基础上进行了一些修改,并增加了注释。
一、数据预处理部分一、数据预处理部分
import pickle
import pandas as pd
import numpy as np
def load_data():
train_data = {}
file_path = '../data/tiny_train_input.csv'
data = pd.read_csv(file_path, header=None)
data.columns = ['c' + str(i) for i in range(data.shape[1])] # 将列名改成了c0,c1,c2...
label = data.c0.values # 第一列
label = label.reshape(len(label), 1) # 将列向量变成行向量
train_data['y_train'] = label
co_feature = pd.DataFrame()
ca_feature = pd.DataFrame()
ca_col = [] co_col = [] feat_dict = {}
cnt = 1
for i in range(1, data.shape[1]):
target = data.iloc[:, i] # iloc用于取出前i列
col = target.name # 得到是不包含列索引的Series结构
l = len(set(target)) # set() 函数创建一个无序不重复元素集
if l > 10:
target = (target - target.mean()) / target.std() # .std()函数计算标准差
co_feature = pd.concat([co_feature, target], axis=1) # 将c0_feature与target进行纵向拼接
feat_dict[col] = cnt
cnt += 1
co_col.append(col)
else:
us = target.unique() # unique()是以数组形式(numpy.ndarray)返回列的所有唯一值(特征的所有唯一值)
print(us)
feat_dict[col] = dict(zip(us, range(cnt, len(us) + cnt))) # zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一
个个元组,然后返回由这些元组组成的列表
ca_feature = pd.concat([ca_feature, target], axis=1)
cnt += len(us)
ca_col.append(col)
feat_dim = cnt
feature_value = pd.concat([co_feature, ca_feature], axis=1)
feature_index = feature_value.copy()
for i in feature_index.columns:
if i in co_col:
feature_index[i] = feat_dict[i] else:
feature_index[i] = feature_index[i].map(feat_dict[i])
feature_value[i] = 1.
train_data['xi'] = feature_index.values.tolist()
train_data['xv'] = feature_value.values.tolist()
train_data['feat_dim'] = feat_dim
return train_data
如上,重要的是做了两件事情,生成了feature_index和feature_value。
feature_index是把所有特征进行了标序,feature1,feature2…featurem,分别对应0,1,2,3,…m,但是,请注意分类变量
需要拆分!就是说如果有性别:男|女|未知,三个选项。需要构造feature男,feature女,feature未知三个变量,而连续变量就
不需要这样。
feature_value就是特征的值,连续变量按真实值填写,分类变量全部填写1。
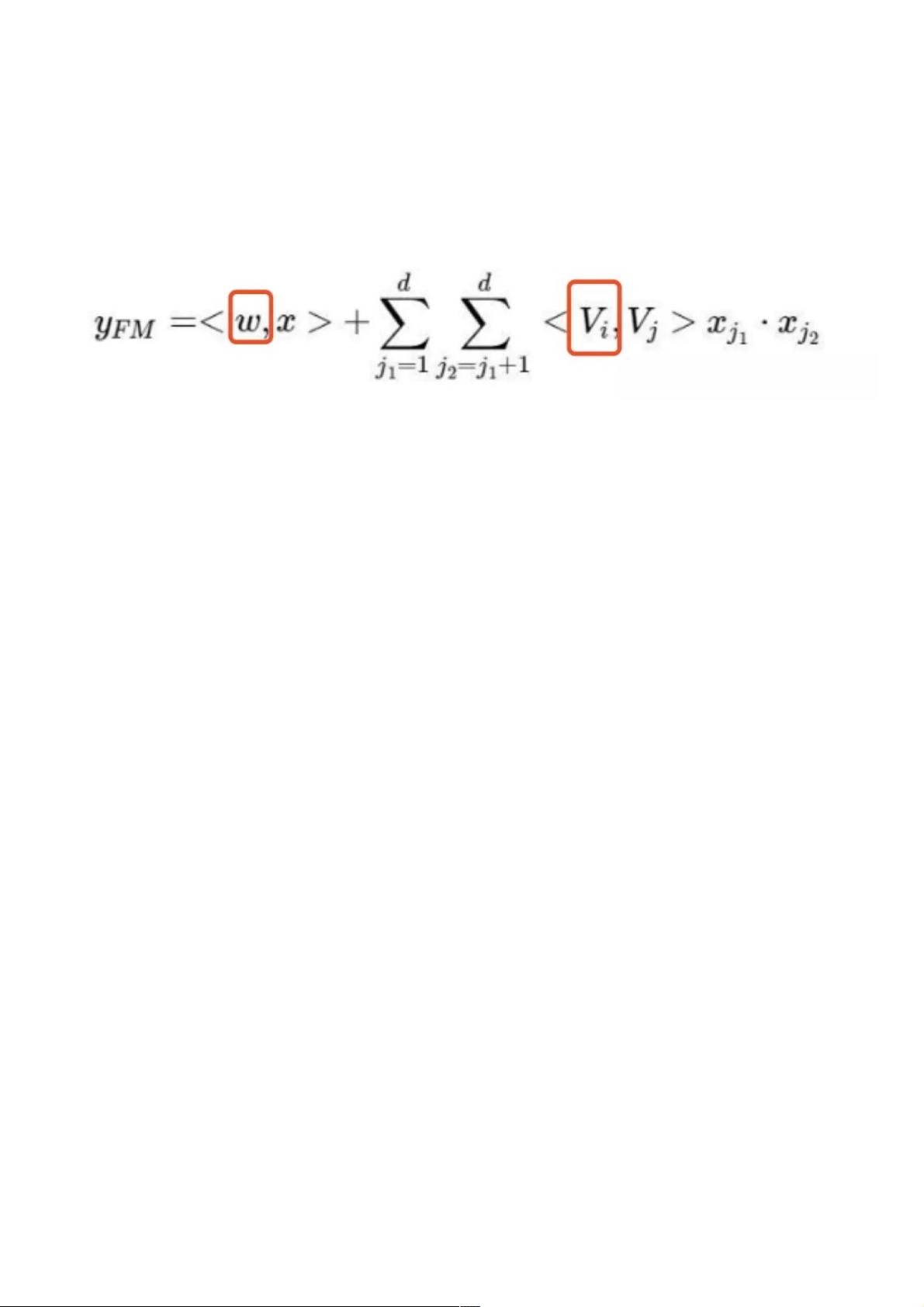
二、二、DeepFM部分部分
剩余6页未读,继续阅读













评论0