Kaggle经典案例—信用卡诈骗检测的完整流程(学习笔记)
47 浏览量
2020-12-22
05:55:17
上传
评论 6
收藏 772KB PDF 举报

Kaggle经典案例经典案例—信用卡诈骗检测的完整流程信用卡诈骗检测的完整流程(学习笔记学习笔记)
本文此案例的完整流程和涉及知识
首先先看数据首先先看数据
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
data = pd.read_csv("creditcard.csv")
data.head()
data.shape
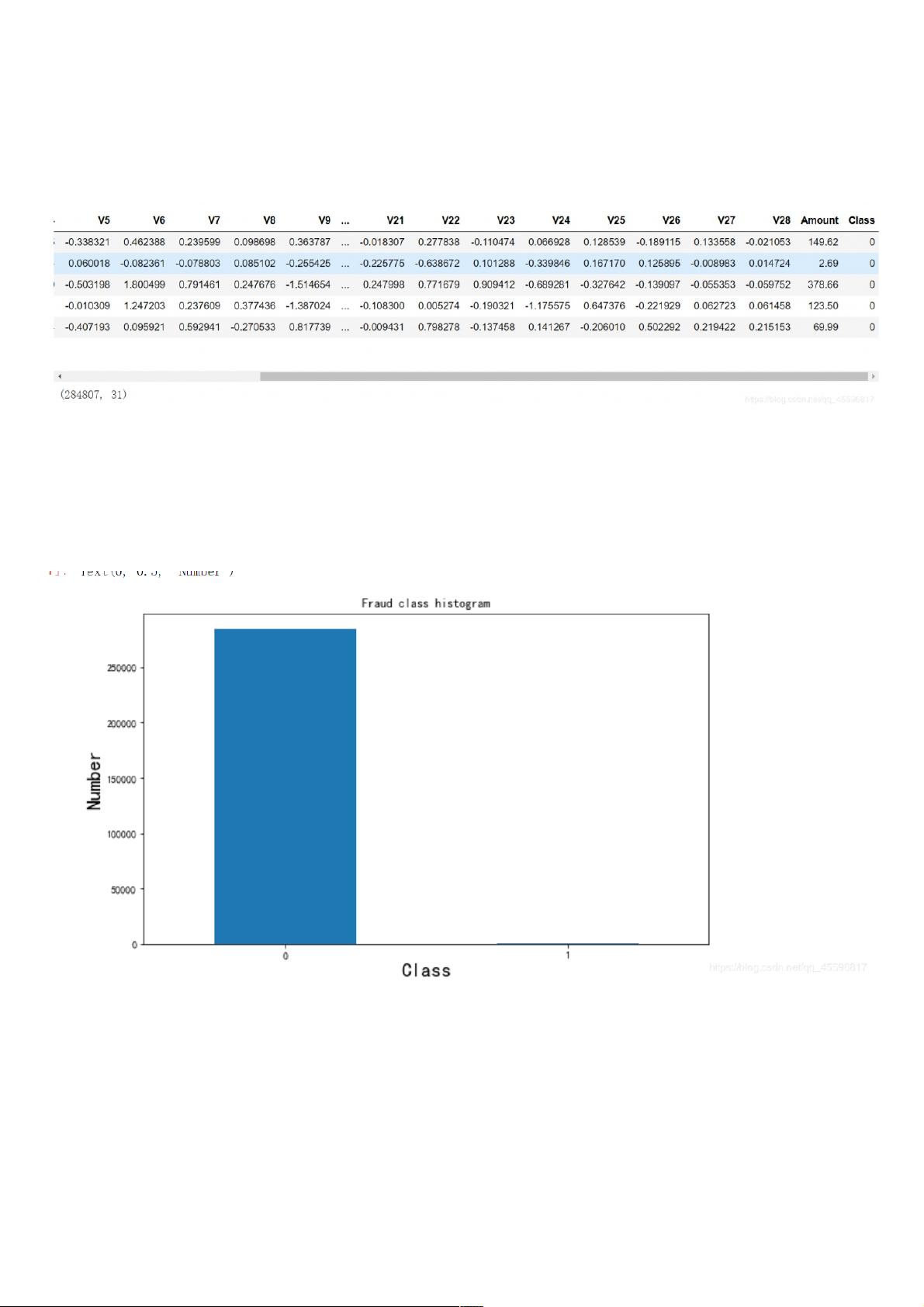
好的,它长这个样子。大致解释一下V1-V28都是一系列的指标(具体是什么不用知道),Amount是交易金额,Class=0表示是正常操作,而=1表示异常操作。
明确目标:检测是否异常,也就是说是一个二分类问题,接着想到用逻辑回归建模。明确目标:检测是否异常,也就是说是一个二分类问题,接着想到用逻辑回归建模。
1.观察数据特征观察数据特征
Class=0的我们不妨称之为负样本,的我们不妨称之为负样本,Class=1的称正样本的称正样本,看一下正负样本的数量。
count_classes = pd.value_counts(data['Class'],sort = True).sort_index()
plt.figure(figsize=(10,6))
count_classes.plot(kind='bar')
plt.title("Fraud class histogram")
plt.xlabel("Class",size=20)
plt.xticks(rotation=0)
plt.ylabel("Number",size=20)
可以看出样本数据严重不均衡,样本类别不均衡将导致样本量少的分类所包含的特征过少,并很难从中提取规律。同时你的学习结果会过度拟合这种不均的结果,通俗来说就是将你
的学习结果用到一组分布均匀的数据上,拟合度会很差。
那么怎么解决这个问题呢?有两种办法那么怎么解决这个问题呢?有两种办法
采样方式选择采样方式选择
((1)下采样)下采样
对这个问题来说,下采样采取的方法就是取正样本中的一部分,使得正样本和负样本数量大致相同。就是让样本变得一样少就是让样本变得一样少
((2)过采样)过采样
相对的,过采样的做法即再生成更多的负样本数据,使得负样本和正样本一样多。就是让样本变得一样多就是让样本变得一样多
2.归一化处理归一化处理
继续观察数据,我们可以发现Amount这一列数据的浮动差异和V1-V28数据的浮动相比差距很大。在做模型之前要保证特征之间的分布差异是差不多的,否则会对我们的模型产生误在做模型之前要保证特征之间的分布差异是差不多的,否则会对我们的模型产生误
导,所以先对导,所以先对Amount做归一化或者标准化做归一化或者标准化做法如下,使用sklearn很方便
#在这里顺便删去了Time列,因为Time列对这个问题没什么帮助
from sklearn.preprocessing import StandardScaler
data['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1))
data = data.drop(['Time','Amount'],axis=1)
data.head()













评论0