nlp中的实体关系抽取方法总结
24 浏览量
2021-02-24
02:21:31
上传
评论 1
收藏 1.75MB PDF 举报

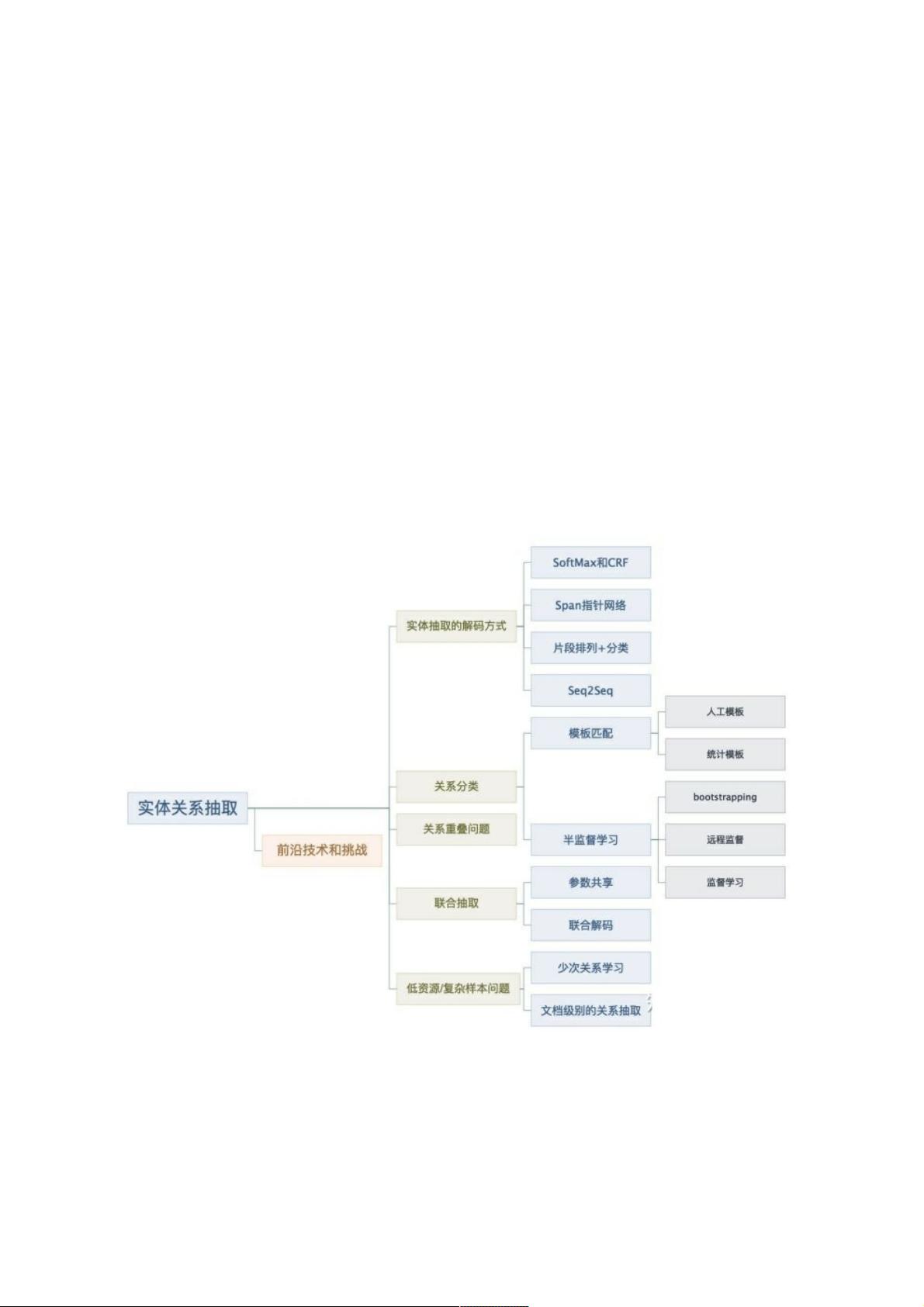
nlp中的实体关系抽取方法总结中的实体关系抽取方法总结
Question List
Q1:与联合抽取对比,Pipeline方法有哪些缺点?
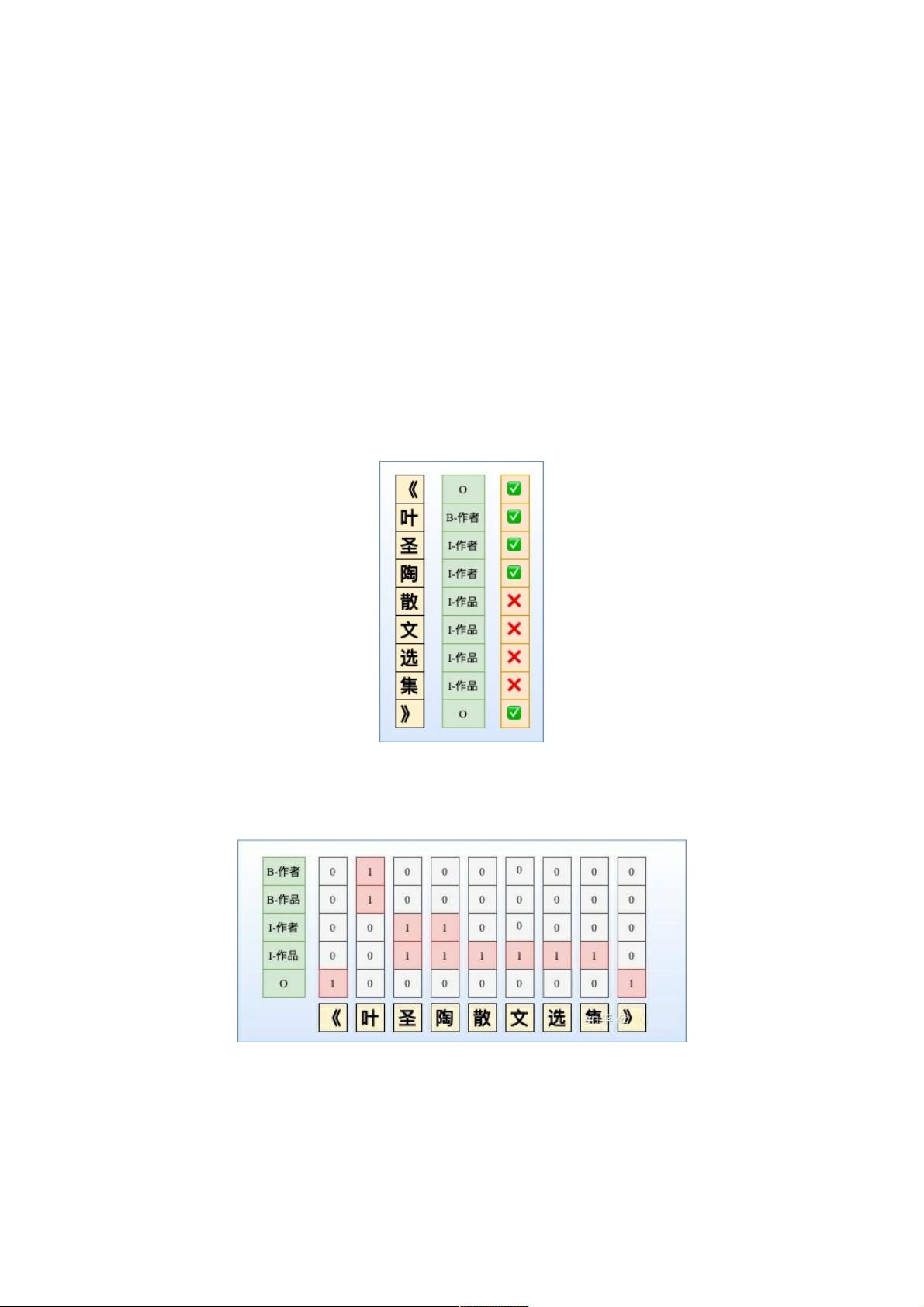
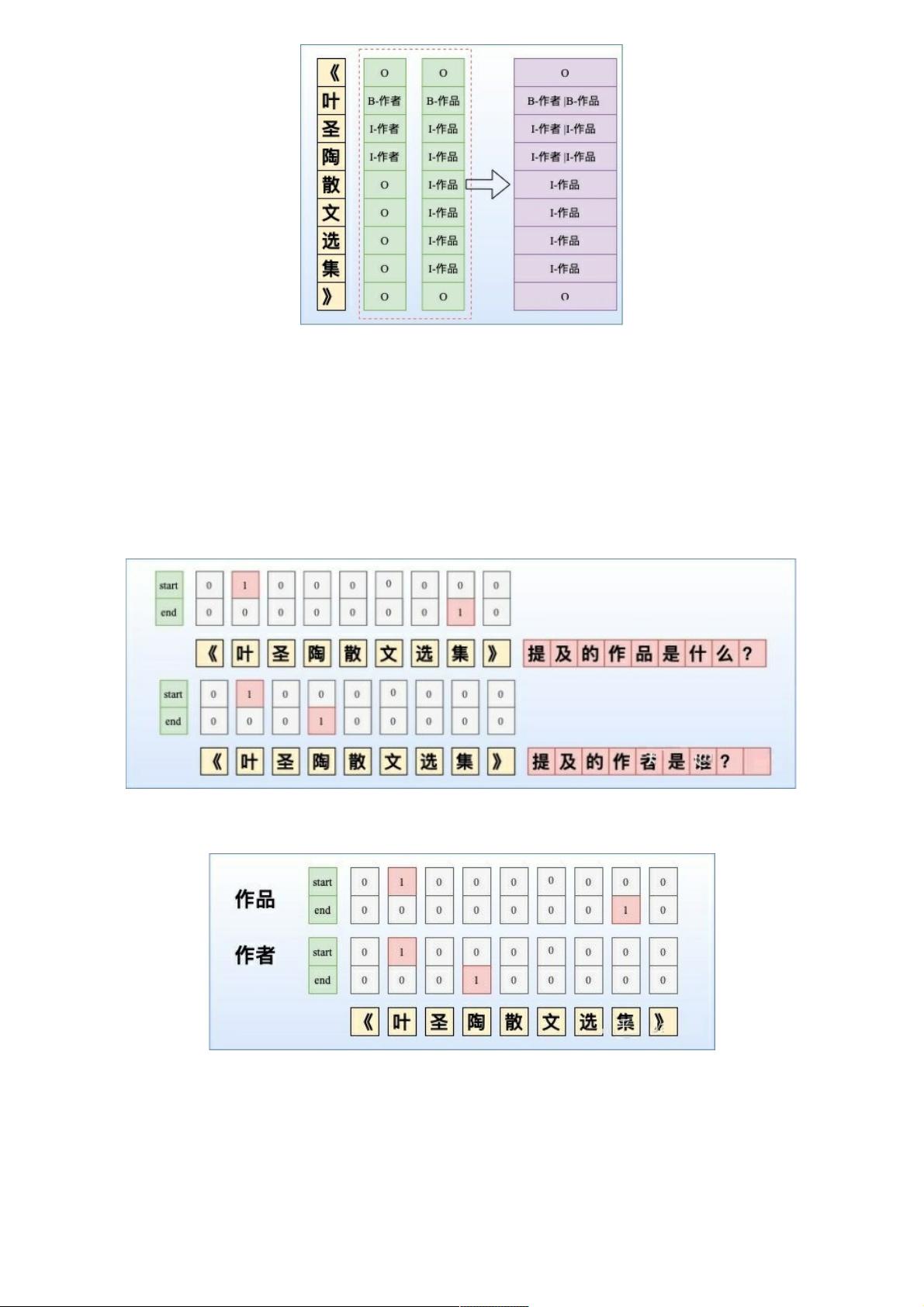
Q2:NER除了LSTM+CRF,还有哪些解码方式?如何解决嵌套实体问题?
Q3:Pipeline中的关系分类有哪些常用方法?如何应用弱监督和预训练机制?怎么解决高复杂度问题、进行one-pass关系分
类?
Q4:什么是关系重叠问题?
Q5:联合抽取难点在哪里?联合抽取总体上有哪些方法?各有哪些缺点?
Q6:介绍基于共享参数的联合抽取方法?
Q7:介绍基于联合解码的联合抽取方法?
Q8:实体关系抽取的前沿技术和挑战有哪些?如何解决低资源和复杂样本下的实体关系抽取?如何应用图神经网络?
彩蛋:百度2020关系抽取比赛的baseline可以采取哪些方法?
实体关系抽取(Entity and Relation Extraction,ERE)是信息抽取的关键任务之一。ERE是级联任务,分为两个子任务:实
体抽取和关系抽取,如何更好处理这种类似的级联任务是NLP的一个热点研究方向。
本文结构
Q1:与联合抽取对比,Pipeline方法有哪些缺点?
Pipeline方法指先抽取实体、再抽取关系。相比于传统的Pipeline方法,联合抽取能获得更好的性能。虽然Pipeline方法易于实
现,这两个抽取模型的灵活性高,实体模型和关系模型可以使用独立的数据集,并不需要同时标注实体和关系的数据集。但存
在以下缺点:
误差积累:实体抽取的错误会影响下一步关系抽取的性能。
实体冗余:由于先对抽取的实体进行两两配对,然后再进行关系分类,没有关系的候选实体对所带来的冗余信息,会提升错误
率、增加计算复杂度。

剩余17页未读,继续阅读
资源评论













