
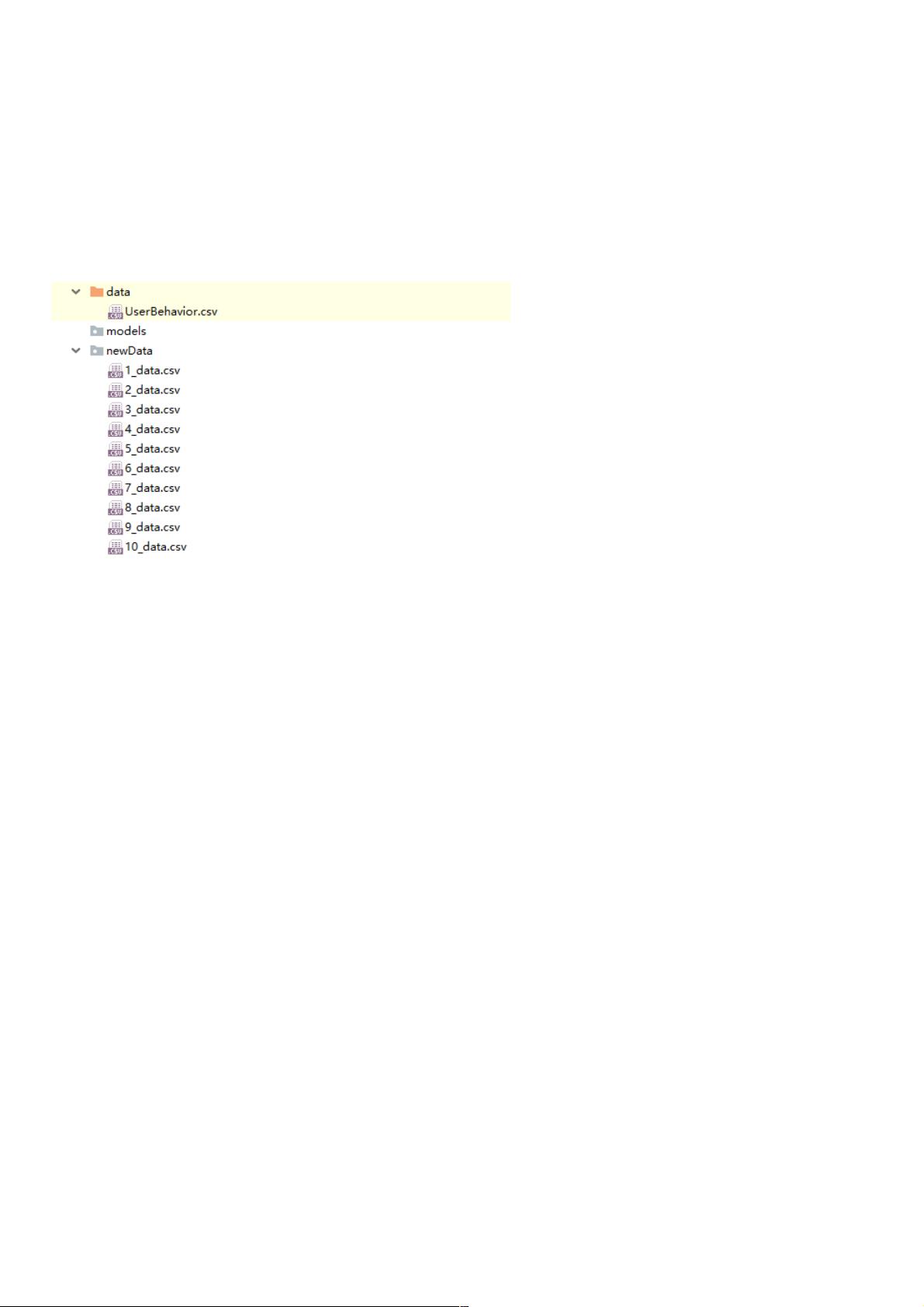
Python 等分切分数据及规则命名的实例代码等分切分数据及规则命名的实例代码
将一份一亿多条数据的csv文件等分为10份,代码如下所示:
import pandas as pd
data = pd.read_csv('C:\Users\PycharmProjects\SplitData\data\UserBehavior.csv') # 路径则根据个人存放项目文件的习惯
num = 0
for i in range(1, 11):
start = num
num = num + int(data.shape[0] / 10)
file = data.iloc[start:num,] file.to_csv("C:\Users\PycharmProjects\SplitData\newData\" + str(i) + "_data.csv", index=False) # index=False是不想切分后
的文件出现序号
注意:如果此时文件的路径包含有中文,则必须改成以下的代码:
import pandas as pd
f = open('C:\Users\PycharmProjects\数据切分\data\UserBehavior.csv')
data = pd.read_csv(f)
num = 0
for i in range(1, 11):
start = num
num = num + int(data.shape[0] / 10)
file = data.iloc[start:num,] file.to_csv("C:\Users\PycharmProjects\SplitData\newData\" + str(i) + "_data.csv", index=False)
但是使用这种方法调用文件进内存,加重了内存的负担,两次赋值相当于内存占用乘2,此方法不建议使用,还是将路径改为
英文名。
总结总结
以上所述是小编给大家介绍的Python 等分切分数据及规则命名的实例代码,希望对大家有所帮助,如果大家有任何疑问请给我
留言,小编会及时回复大家的。在此也非常感谢大家对软件开发网网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
您可能感兴趣的文章您可能感兴趣的文章:详解python校验SQL脚本命名规则和孩子一起学习python之变量命名规则深入理解Python中命名空间的
查找规则LEGBPython 变量类型及命名规则介绍
资源评论













