
Cassandra数据模型设计最佳实践数据模型设计最佳实践
本文是Cassandra数据模型设计第一篇(全两篇),该系列文章包含了eBay使用Cassandra数据模型设计的一些实践。其中一
些最佳实践我们是通过社区学到的,有些对我们来说也是新知识,还有一些仍然具有争议性,可能在要通过进一步的实践才能
从中获益。
本文中,我将会讲解一些基本的实践以及一个详细的例子。即使你不了解Cassandra,也应该能理解下面大多数内容。
说说Cassandra在ebay的使用情况
我们尝试使用Cassandra已经超过1年时间了。Cassandra现在正在服务一些用例,涉及到的业务从大量写操作的日志记录和
跟踪,到一些混合工作。其中一项服务是我们的“Social Signal”项目,支撑着ebay的pruduct pages里like/own/want特性。我们
开发的一些用例已经上线运行,但更多的还是处于开发阶段。
我们的Cassandra集群规模并不庞大,但正在稳步的增长中。在过去几个月里,我们共部署了几十个节点,它们分布在几个跨
机房的小型集群中。你可能会问,为什么要多个集群?我们通过的职能部门和业务来划分集群。相同职能部门的相同业务的用
例共享一个集群,但它们存在于不同的keyspaces中。
RedLaser, Hunch和其它ebay的合作伙伴也在尝试cassandra解决现实中各种问题。除了Cassandra,我们也在使用MongoDB
和Hbase,本文中我不会讨论它们,但我相信它们都有各自的优点。
我相信此时你一定有很多问题,在这篇文章里暂时不会一一说明。在即将到来的Cassandra Summit大会,我将更详细的讲解
我们每个用例场景,数据模型和多数据中心部署,以及经验教训和其它知识。
本文重点讲述我们在ebay应用的Cassandra数据模型设计最佳实践。下面让我们先看看这系列文章会用到的一些术语。
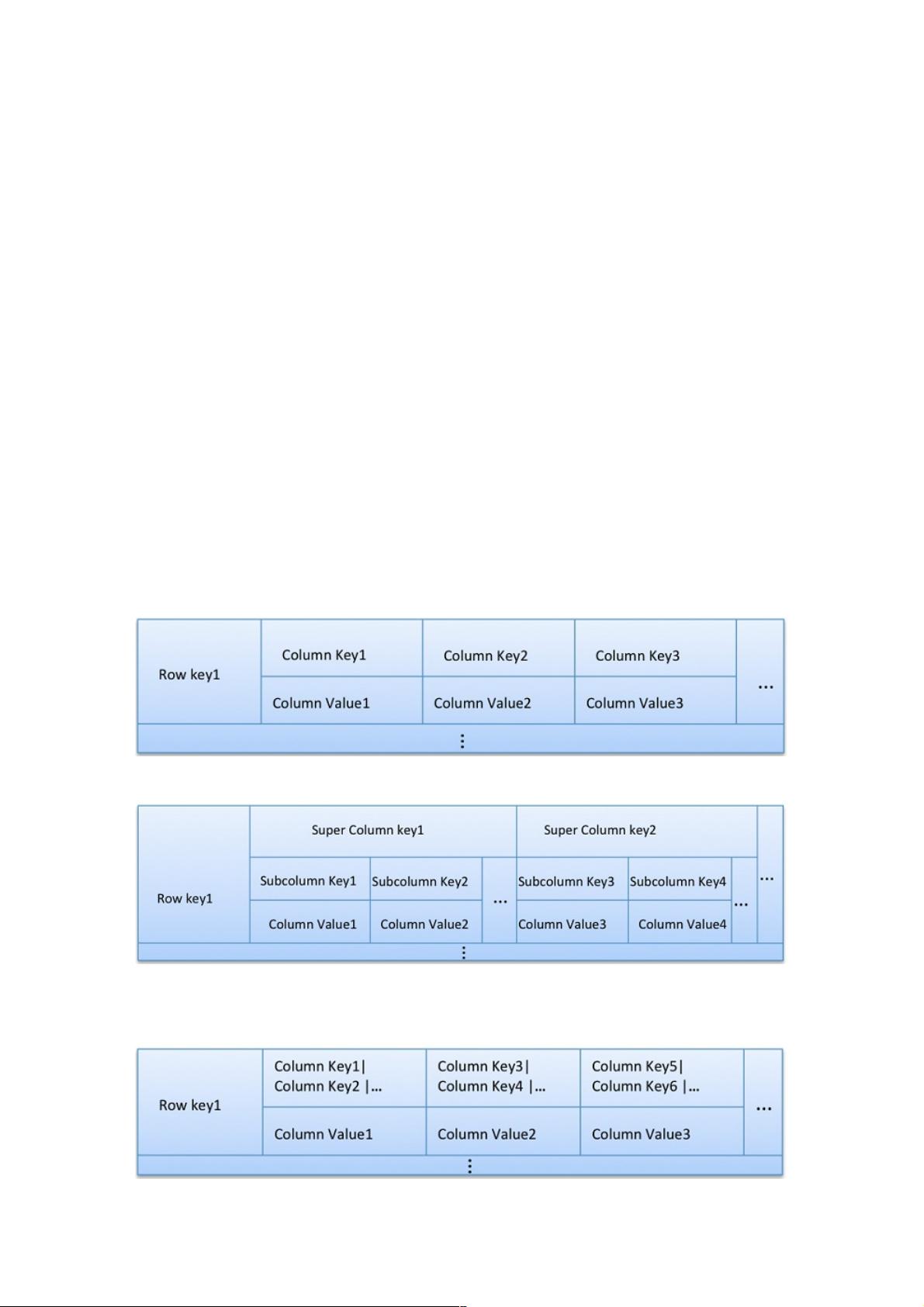
术语和约定
术语“Column Name” 和 “Column Key”被认为是一样的。同样的,“Super Column Name” 和 “Super Column Key”也认为是相
同的。
下图表示一个 Column Family (简称CF)中的一个row
下图表示一个 Super Column Family (简称SCF)中的一个row
下图表示一个Column Family中一个row,它包含Composite Columns。Composite Columns的属性通过分隔符’|’连接。请注
意,这里看到的只是数据的表现形式,Cassandra内置了Composite Column,它是一个对象,并不是使用’|’作为属性分隔符的
字符串。(顺便说下,本文不要求你掌握Super Column和Composite Column方面知识。)
基于上面的内容,让我们开始第一个实践吧!
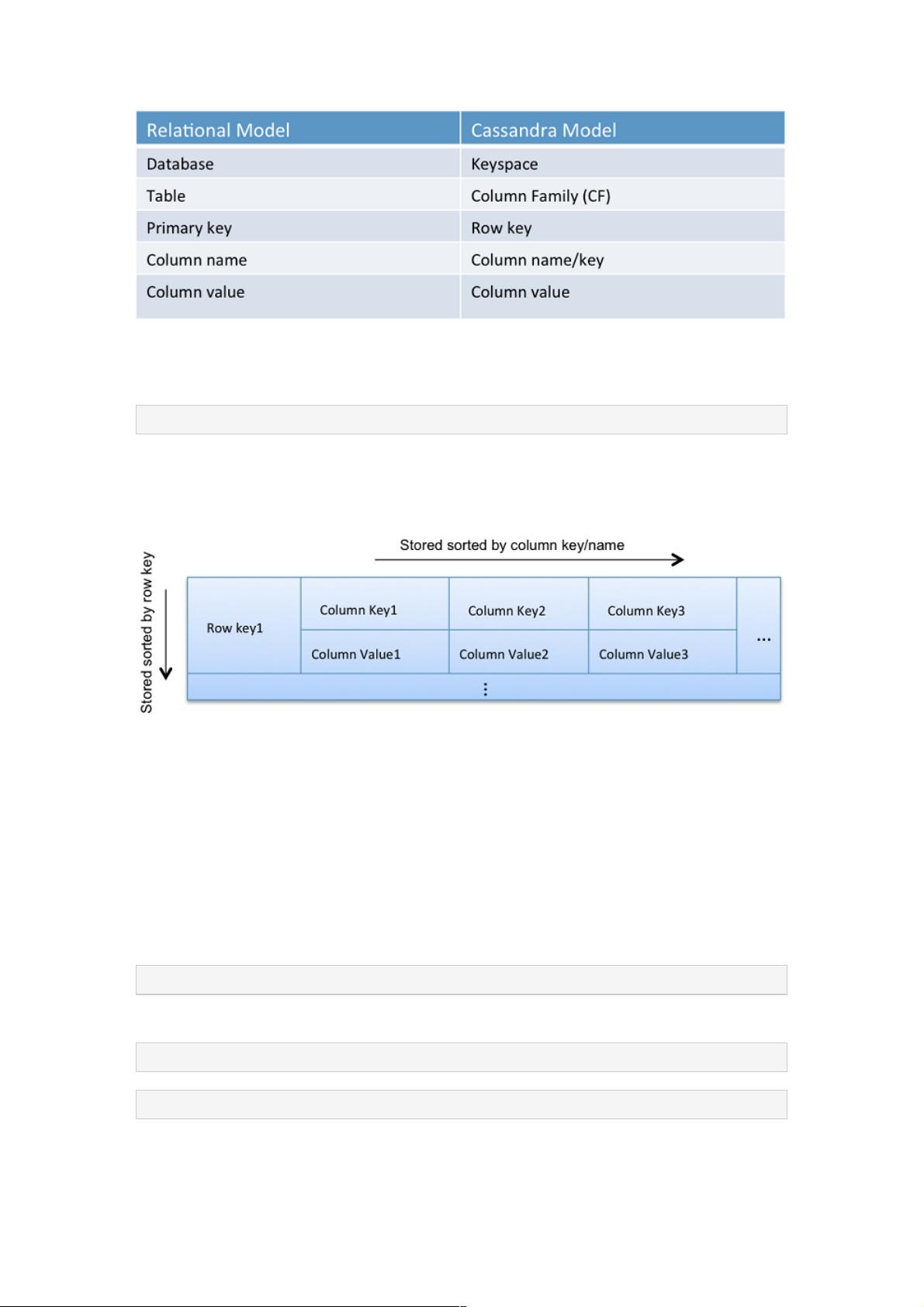
不要把Cassandra model想象成关系型数据库table
剩余10页未读,继续阅读
资源评论













