
[编译原理编译原理-词法分析词法分析(一一)] 输入缓冲输入缓冲 双缓冲区方案双缓冲区方案
前言前言
在实践中, 通常需要向前看一个字符.
比如, 当读到一个 非字母或数字的字符 时才能确定已经读到一个标识符的结尾. 因此, 这个字符不是id词素的一部分.
采用双缓冲区方案能够安全地处理向前看多个符号的问题. 然后, 将考虑一种改进方案, 使用"哨兵标记"来节约用于检查缓冲区末端的时间. {P72}
前情提要前情提要
一、缓冲区对
二、哨兵标记
三、实现双缓冲区
正文正文
一、缓冲区对一、缓冲区对
描述:
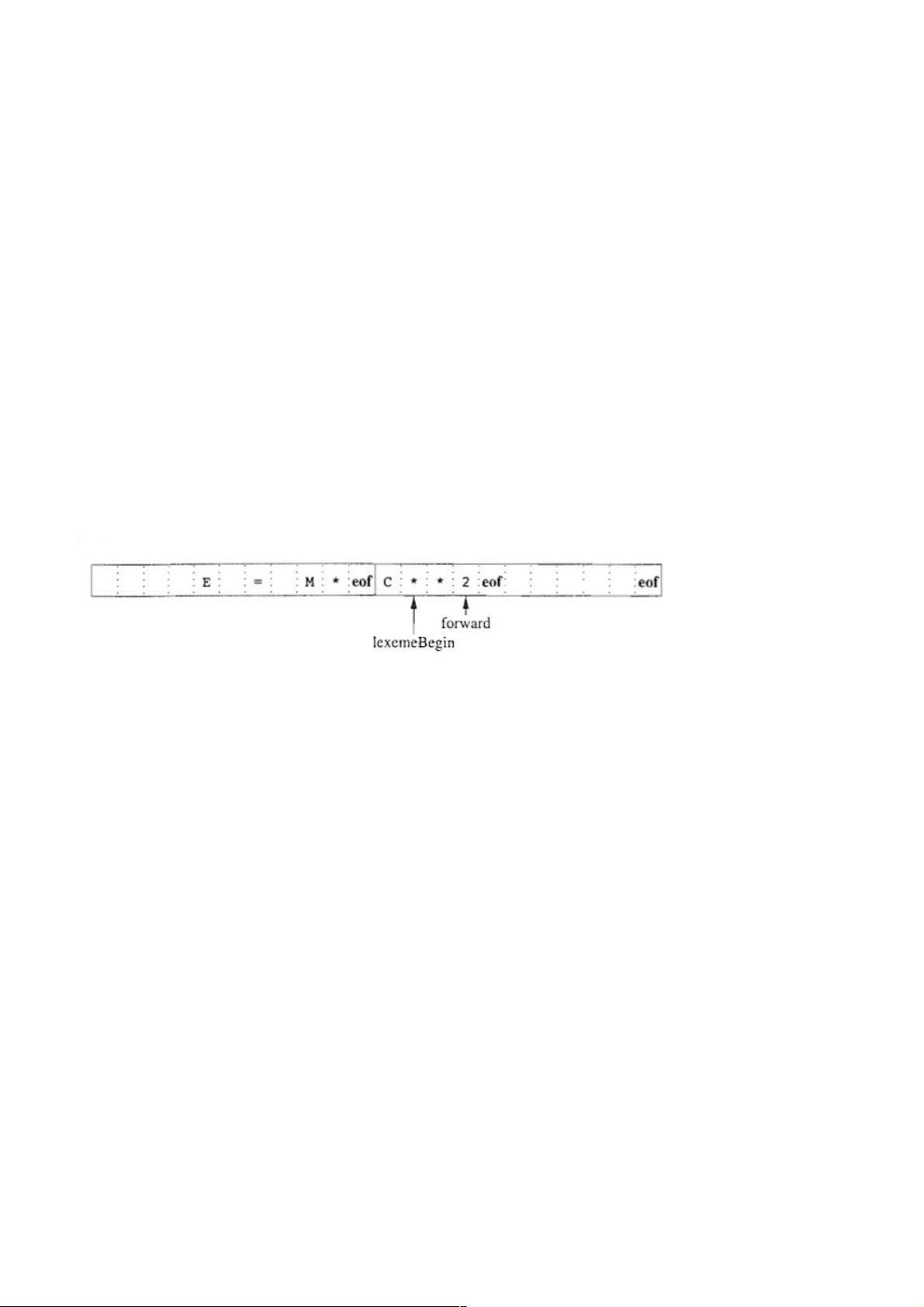
两个交替读入的缓冲区, 容量为N个字符, 使用系统命令一次性将N个字符读入到缓冲区;
如果输入字符不足N个, 则有特殊字符EOF来标记文件结尾;
程序维护两个指针lexemeBegin和forward;
lexemeBegin指向当前词素的开始处, 当前正试图确定这个词素的结尾;
forward向前扫描, 直到与某个模式匹配为止;
当确定该词素时, forward指向该词素结尾的字符;
将词素作为摸个返回给语法分析器的词法单元的属性值记录;
lexemeBegin指向该词素后的第一个字符, 然后将forward左移一个字符;
在forward不断扫描中, 检查是否扫描到EOF, 如果是则将N个新字符读入另外一个缓冲区, 且将forward指向缓冲区头部;
二、哨兵标记二、哨兵标记
当采用双缓冲区方案, 那么每次向前移动forward指针时, 都需要检查是否到缓冲区结尾, 若是则加载另外一个缓冲区.
如果扩展每个缓冲区, 使它们在末尾包含一个哨兵(sentinel)字符, 就可以把缓冲区末尾的测试和当前字符的测试结合在一起, 这个字符选择不会出现在源程
序中的 EOF标记.
三、实现双缓冲区三、实现双缓冲区
将使用 标记来自哪个文件
namespace Lexical_Analysis {
template
class Buffer {
private:
enum Tag { ONE, TWO }; // 缓冲区标号
public:
explicit Buffer(std::string _fileStr);
~Buffer() noexcept;
public:
char* lexemeBegin = nullptr;
char* forward = nullptr;
/**
* @return 返回lexemeBegin 与 forward 的字符序列
*/
std::string getString();
/**
* forward向前移动一个字符
* @return 返回当前字符
*/
char next();
/**
* @return 返回当前forward所指字符
*/
char cur();

weixin_38611459
- 粉丝: 6
- 资源: 917









最新资源
- js基础但是这个烂怂东西要求标题不能少于10个字才能上传然后我其实还没有写完之后再修订吧.md
- electron-tabs-master
- Unity3D 布朗运动算法插件 Brownian Motion
- 鼎微R16中控升级包R16-4.5.10-20170221及强制升级方法
- 鼎微R16中控升级包公版UI 2015及强制升级方法,救砖包
- 基于CSS与JavaScript的积分系统设计源码
- 生物化学作业_1_生物化学作业资料.pdf
- 基于libgdx引擎的Java开发连连看游戏设计源码
- 基于MobileNetV3的SSD目标检测算法PyTorch实现设计源码
- 基于Java JDK的全面框架设计源码学习项目
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0