
Python爬虫教程知识点总结爬虫教程知识点总结
一、为什么使用一、为什么使用Python进行网络爬虫?进行网络爬虫?
由于Python语言十分简洁,使用起来又非常简单、易学,通过Python 进行编写就像使用英语进行写作一样。另外Python 在使用中十分方便,并不需要IDE,而仅仅通过sublime text 就能够对大部分的中
小应用进行开发;除此之外Python 爬虫的框架功能十分强大,它的框架能够对网络数据进行爬取,还能对结构性的数据进行提取,经常用在数据的挖掘、历史数据的存储和信息的处理等程序内;Python
网络的支持库和html的解析器功能十分强大,借助网络的支持库通过较少代码的编写,就能够进行网页的下载,且通过网页的解析库就能够对网页内各标签进行解析,和正则的表达式进行结合,
十分便于进行网页内容的抓取。所以Python在网络爬虫网面有很大的优势。
二、判断网站数据是否支持爬取二、判断网站数据是否支持爬取
几乎每个网站都有一个名为 robots.txt 的文档,当然也有部分网站没有设定robots.txt。如果网站没有设定 robots.txt 就可以通过网络爬虫获取没有口令加密的数据,也就是这个网站所有页面数据都可以爬
取。当然如果网站有 robots.txt 文档,就要判断是否有禁止访客获取的数据。
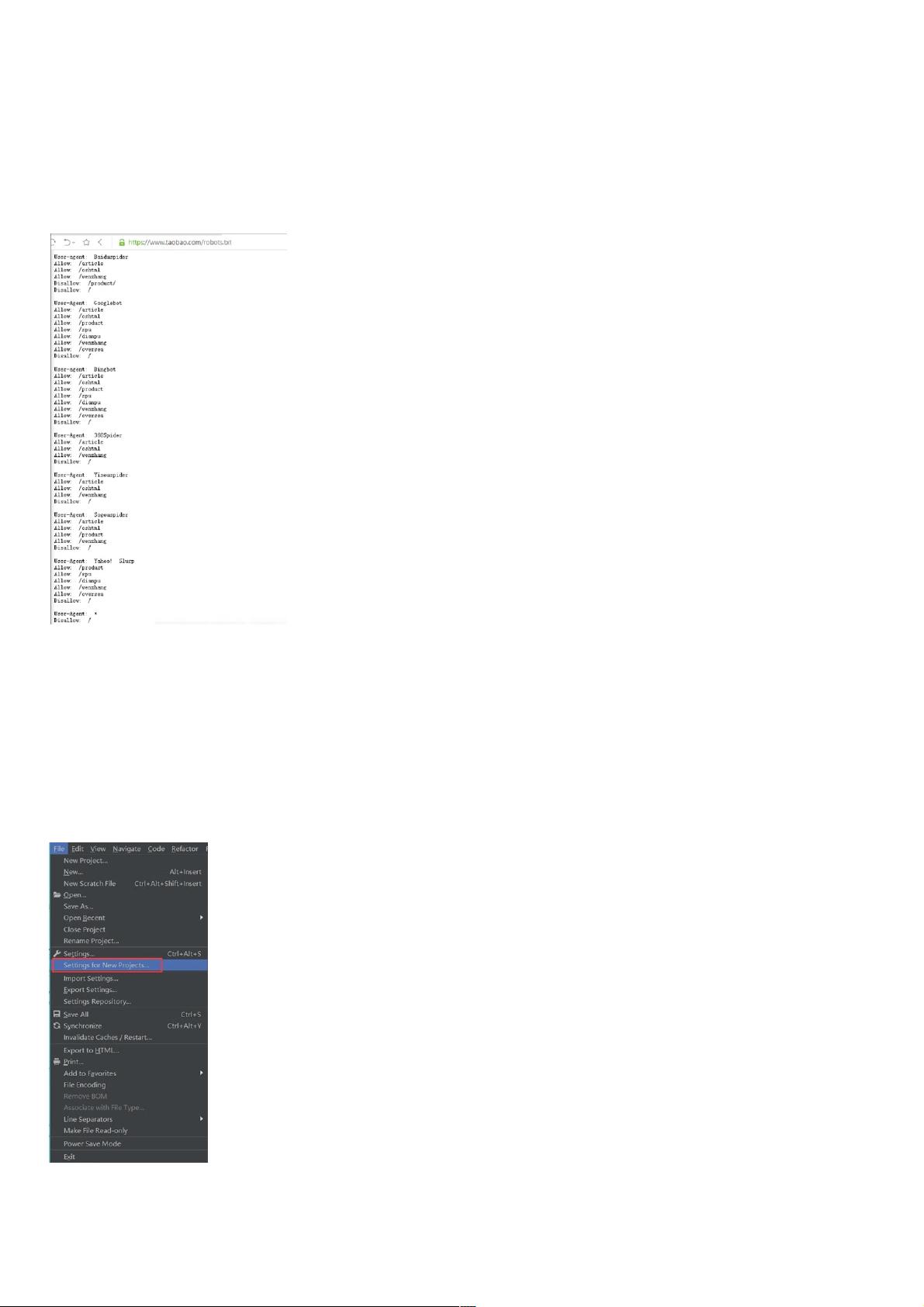
以淘宝网为例,在浏览器中访问 https://www.taobao.com/robots.txt,如图所示。
上图淘宝网的robots.txt文件内容
淘宝网允许部分爬虫访问它的部分路径,而对于没有得到允许的用户,则全部禁止爬取,代码如下:
User-Agent:*
Disallow:/
12
这一句代码的意思是除前面指定的爬虫外,不允许其他爬虫爬取任何数据。
三、三、requests 库抓取网站数据库抓取网站数据
1.如何安装 requests 库
1.首先在 PyCharm 中安装 requests 库
2.打开 PyCharm,单击“File”(文件)菜单
3.选择“Setting for New Projects…”命令
4.选择“Project Interpreter”(项目编译器)命令
5.确认当前选择的编译器,然后单击右上角的加号。













评论0