
python中正则的使用指南中正则的使用指南
正则表达式(RE)是一种小型的、高度专业化的编程语言,它内嵌在Python中,并通过re模块实现。下面我们
就来详细探讨下Python中正则表达式的使用
上一次很多朋友写文字屏蔽说到要用正则表达,其实不是我不想用(我正则用得不是很多,看过我之前爬虫的都知道,我直接用
BeautifulSoup的网页标签去找内容,因为容易理解也方便,),而是正则用好用精通的很难(看过正则表的应该都知道,里
面符号对应的方法规则有很多,很灵活),对于接触编程不久的朋友们来说很可能在编程的过程上浪费很多时间,今天我把经
常会用到正则简单介绍下,如果不是很特殊基本都覆盖使用。
1.正则的简单介绍正则的简单介绍
首先你得导入正则方法 import re正则表达式是用于处理字符串的强大工具,拥有自己独立的处理机制,效率上可能不如str自
带的方法,但功能十分灵活给力。它的运行过程是先定一个匹配规则("你想要的内容+正则语法规则"),放入要匹配的字符
串,通过正则内部的机制就能检索你想要的信息。
2.findall的常用几种姿势的常用几种姿势
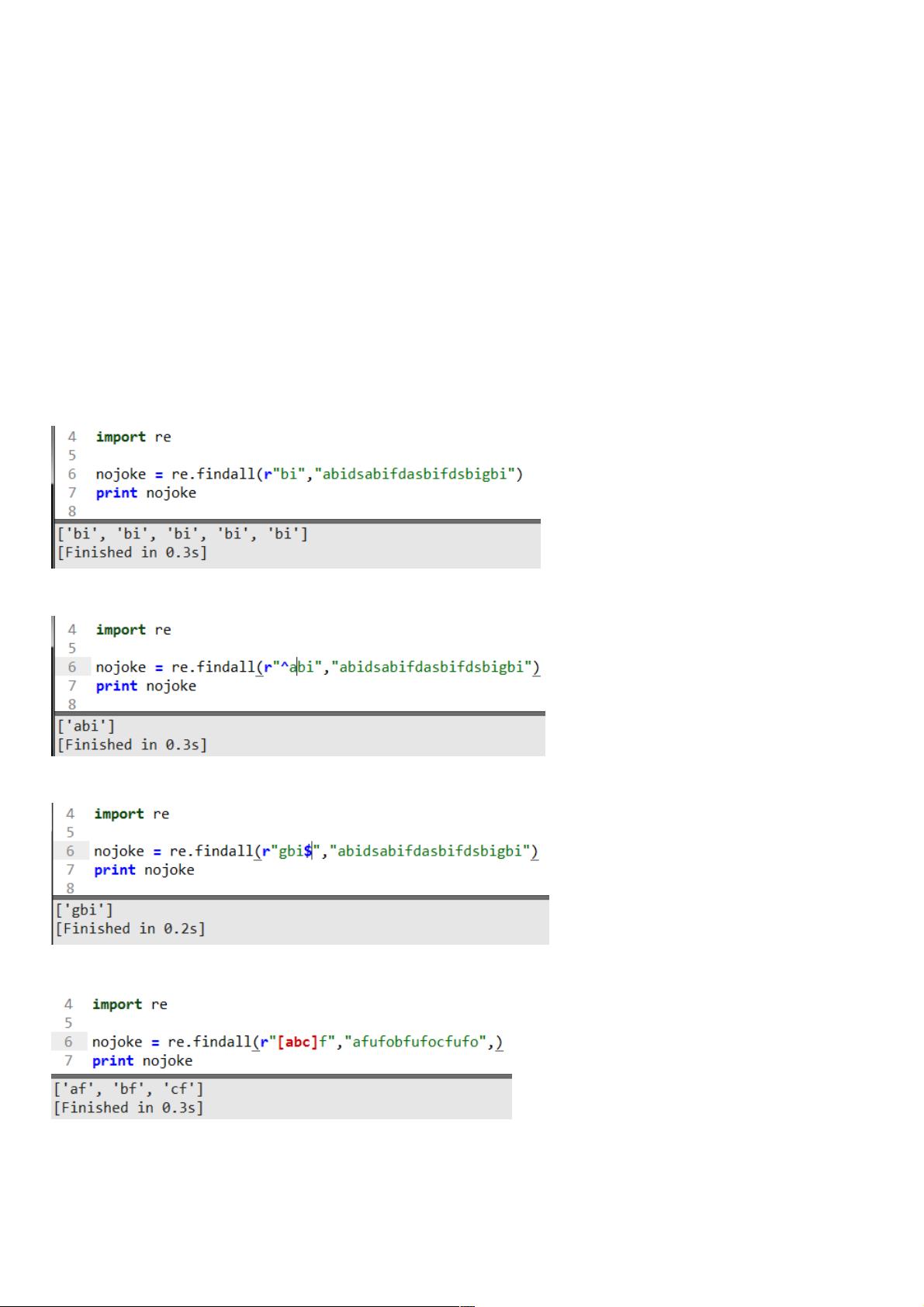
基本结构大致: nojoke = re.findall(r'匹配的规则','要检索的愿字符串') nojoke就是我们最后通过正则返回的结果,re正则findall
查找全部r标识代表后面是正则的语句(这样在代码多的时候好查阅),下面我们看看几个例子好深入了解
这段代码是找出检索字符串中所有的bi并以列表的形式返回,这个会经常用到计算统一字符出现的次数。继续看下一个
这里加了个符号^表示匹配以abi开头的的字符串返回,也可以判断字符串是否以abi开始的。
这里在的用$符号表示以gbi结尾的字符串返回,判断是否字符串结束的字符串。
这里[...]的意思匹配括号内a和f,或者b和f,或者c和f的值返回列表。
资源评论


weixin_38601215
- 粉丝: 1
- 资源: 948









最新资源
- 微信自动发送消息,微信机器人(简单),可以给一个特定的人发送一个特定的消息,后续会继续完善的.zip
- 以下是关于Python项目设计资源的详细内容.docx
- 三菱plc基于mx组件的通用访问远程api接口
- 一套基于 .NET 开发的支付SDK,它简化了API调用及通知的处理流程
- 以下是关于使用各种编程语言实现算法的详细学习资源.docx
- e刚发的如果看你的了啊好吧耳鼻喉热交换包括aelh
- kernel-5.15-ky10-x86.tar.gz
- yolov4 - tiny 900张图片训练效果2
- 基于OpenCV的简易实时人脸识别门禁控制系统
- 以下是 YOLO(You Only Look Once)学习的详细课程.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


