
微信小程序通过微信小程序通过websocket实时语音识别的实现代码实时语音识别的实现代码
主要介绍了微信小程序通过websocket实时语音识别,文中通过示例代码介绍的非常详细,对大家的学习或者工
作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
之前在研究百度的实时语音识别,并应用到了微信小程序中,写篇文章分享一下。
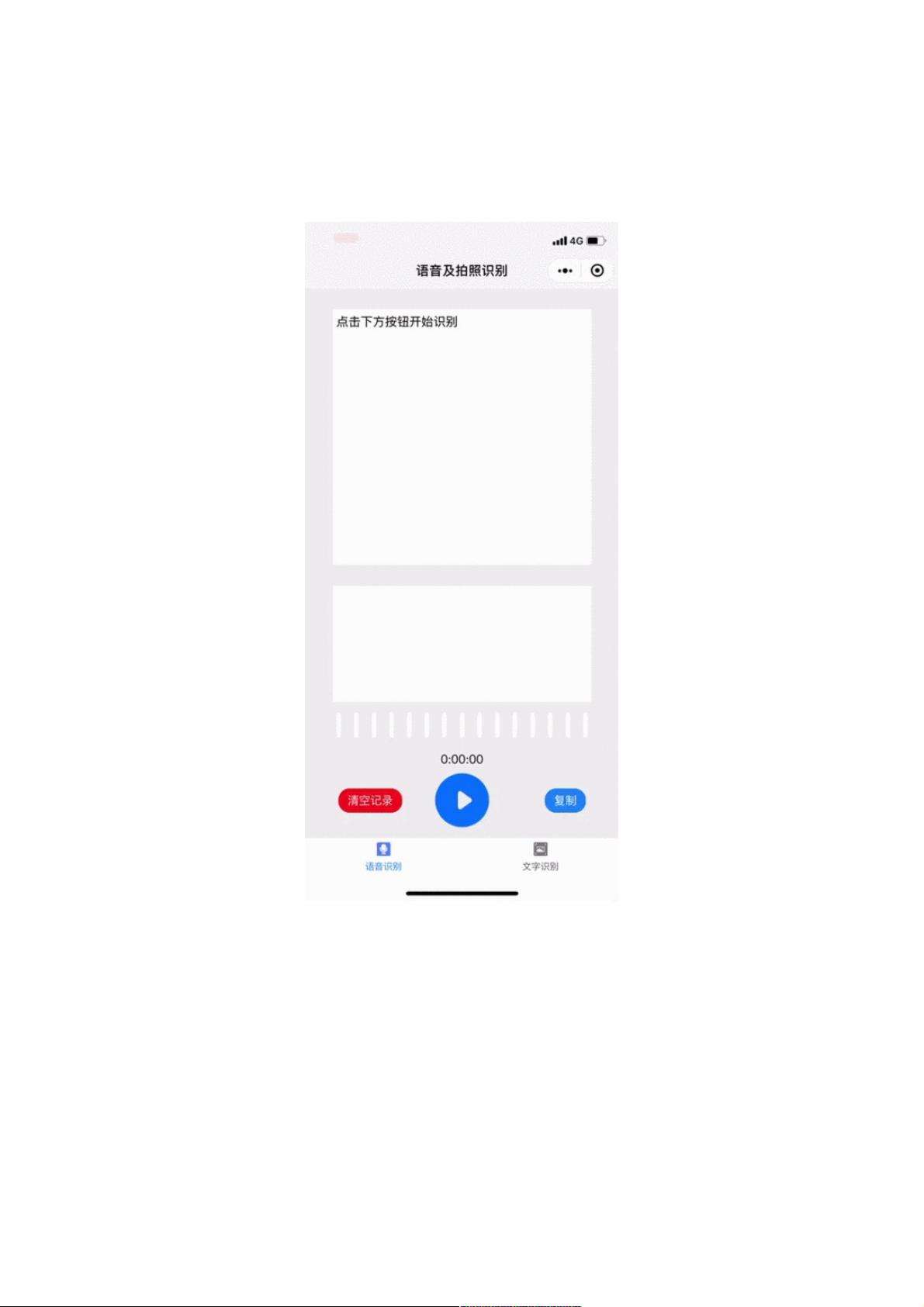
先看看完成的效果吧
前置条件前置条件
申请百度实时语音识别key 百度AI接入指南
创建小程序
设置小程序录音参数设置小程序录音参数
在index.js中输入
const recorderManager = wx.getRecorderManager()
const recorderConfig = {
duration: 600000,
frameSize: 5, //指定当录音大小达到5KB时触发onFrameRecorded
format: 'PCM',
//文档中没写这个参数也可以触发onFrameRecorded的回调,不过楼主亲测可以使用
sampleRate: 16000,
encodeBitRate: 96000,
numberOfChannels: 1
}
使用websocket连接
资源评论

 Marco-Tan2021-02-11直接抄的这个?https://segmentfault.com/a/1190000023682530
Marco-Tan2021-02-11直接抄的这个?https://segmentfault.com/a/1190000023682530












