
Python使用使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码爬虫框架全站爬取图片并保存本地的实现代码
主要介绍了Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码,需要的朋友可以参考下
大家可以在Github上clone全部源码。
Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu
Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
基本上按照文档的流程走一遍就基本会用了。
Step1:
在开始爬取之前,必须创建一个新的Scrapy项目。 进入打算存储代码的目录中,运行下列命令:
scrapy startproject CrawlMeiziTu
该命令将会创建包含下列内容的 tutorial 目录:
CrawlMeiziTu/
scrapy.cfg
CrawlMeiziTu/
__init__.py
items.py
pipelines.py
settings.py
middlewares.py
spiders/
__init__.py
...
cd CrawlMeiziTu
scrapy genspider Meizitu http://www.meizitu.com/a/list_1_1.html
该命令将会创建包含下列内容的 tutorial 目录:
CrawlMeiziTu/
scrapy.cfg
CrawlMeiziTu/
__init__.py
items.py
pipelines.py
settings.py
middlewares.py
spiders/
Meizitu.py
__init__.py
...
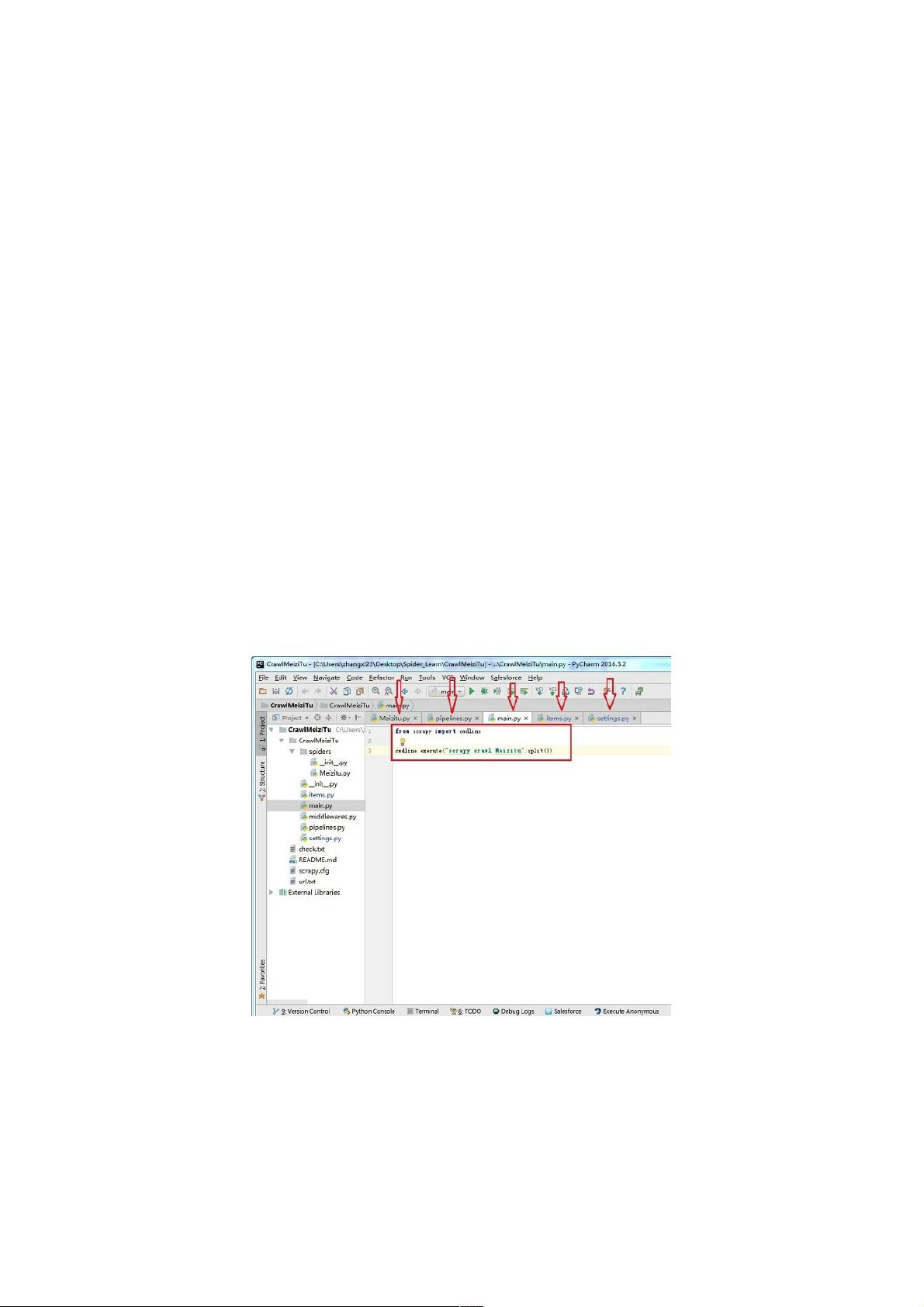
我们主要编辑的就如下图箭头所示:
main.py是后来加上的,加了两条命令,
from scrapy import cmdline
cmdline.execute("scrapy crawl Meizitu".split())
主要为了方便运行。
Step2:编辑:编辑Settings,如下图所示如下图所示
BOT_NAME = 'CrawlMeiziTu'
SPIDER_MODULES = ['CrawlMeiziTu.spiders']
NEWSPIDER_MODULE = 'CrawlMeiziTu.spiders'
ITEM_PIPELINES = {
'CrawlMeiziTu.pipelines.CrawlmeizituPipeline': 300,
}
IMAGES_STORE = 'D://pic2'
DOWNLOAD_DELAY = 0.3
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
ROBOTSTXT_OBEY = True
资源评论


weixin_38596413
- 粉丝: 6
- 资源: 956











