
深入理解深入理解ApacheFlink核心技术核心技术
Apache Flink(下简称Flink)项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越
来越多人的关注。本文将深入分析Flink的一些关键技术与特性,希望能够帮助读者对Flink有更加深入的了解,对其他大数据
系统开发者也能有所裨益。本文假设读者已对MapReduce、Spark及Storm等大数据处理框架有所了解,同时熟悉流处理与批
处理的基本概念。
Flink简介
Flink核心是一个流式的数据流执行引擎,其针对数据流的分布式计算提供了数据分布、数据通信以及容错机制等功能。基于
流执行引擎,Flink提供了诸多更高抽象层的API以便用户编写分布式任务:
DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符
对分布式数据集进行处理,支持Java、Scala和Python。
DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各
种操作,支持Java和Scala。
Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支
持Java和Scala。
此外,Flink还针对特定的应用领域提供了领域库,例如:
Flink ML,Flink的机器学习库,提供了机器学习Pipelines API并实现了多种机器学习算法。
Gelly,Flink的图计算库,提供了图计算的相关API及多种图计算算法实现。
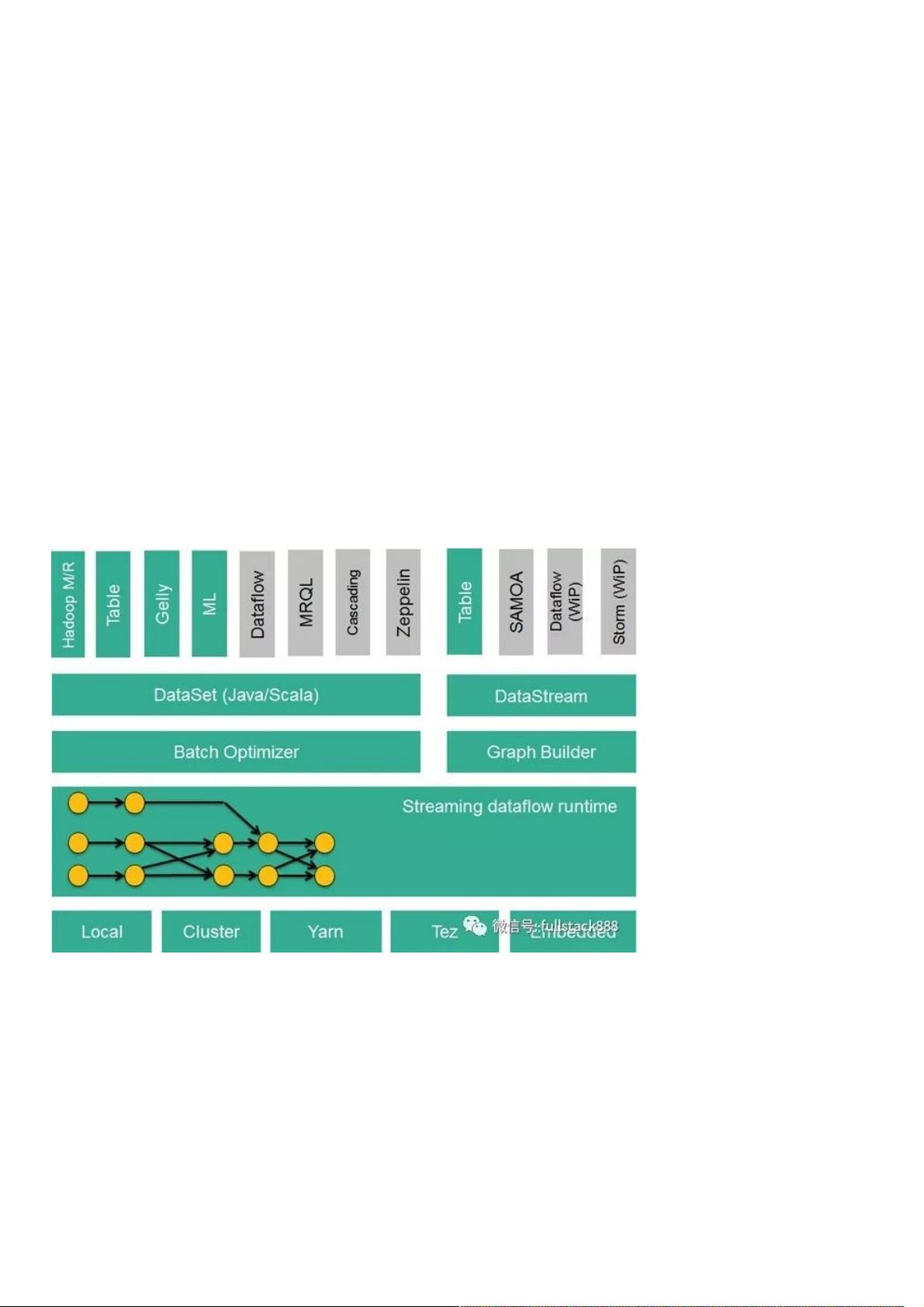
Flink的技术栈如图1所示:
图1 Flink技术栈
此外,Flink也可以方便地和Hadoop生态圈中其他项目集成,例如Flink可以读取存储在HDFS或HBase中的静态数据,以
Kafka作为流式的数据源,直接重用MapReduce或Storm代码,或是通过YARN申请集群资源等。
统一的批处理与流处理系统
在大数据处理领域,批处理任务与流处理任务一般被认为是两种不同的任务,一个大数据项目一般会被设计为只能处理其中一
种任务,例如Apache Storm、Apache Smaza只支持流处理任务,而Aapche MapReduce、Apache Tez、Apache Spark只支
持批处理任务。Spark Streaming是Apache Spark之上支持流处理任务的子系统,看似一个特例,实则不然——Spark
Streaming采用了一种micro-batch的架构,即把输入的数据流切分成细粒度的batch,并为每一个batch数据提交一个批处理的
Spark任务,所以Spark Streaming本质上还是基于Spark批处理系统对流式数据进行处理,和Apache Storm、Apache Smaza
等完全流式的数据处理方式完全不同。通过其灵活的执行引擎,Flink能够同时支持批处理任务与流处理任务。
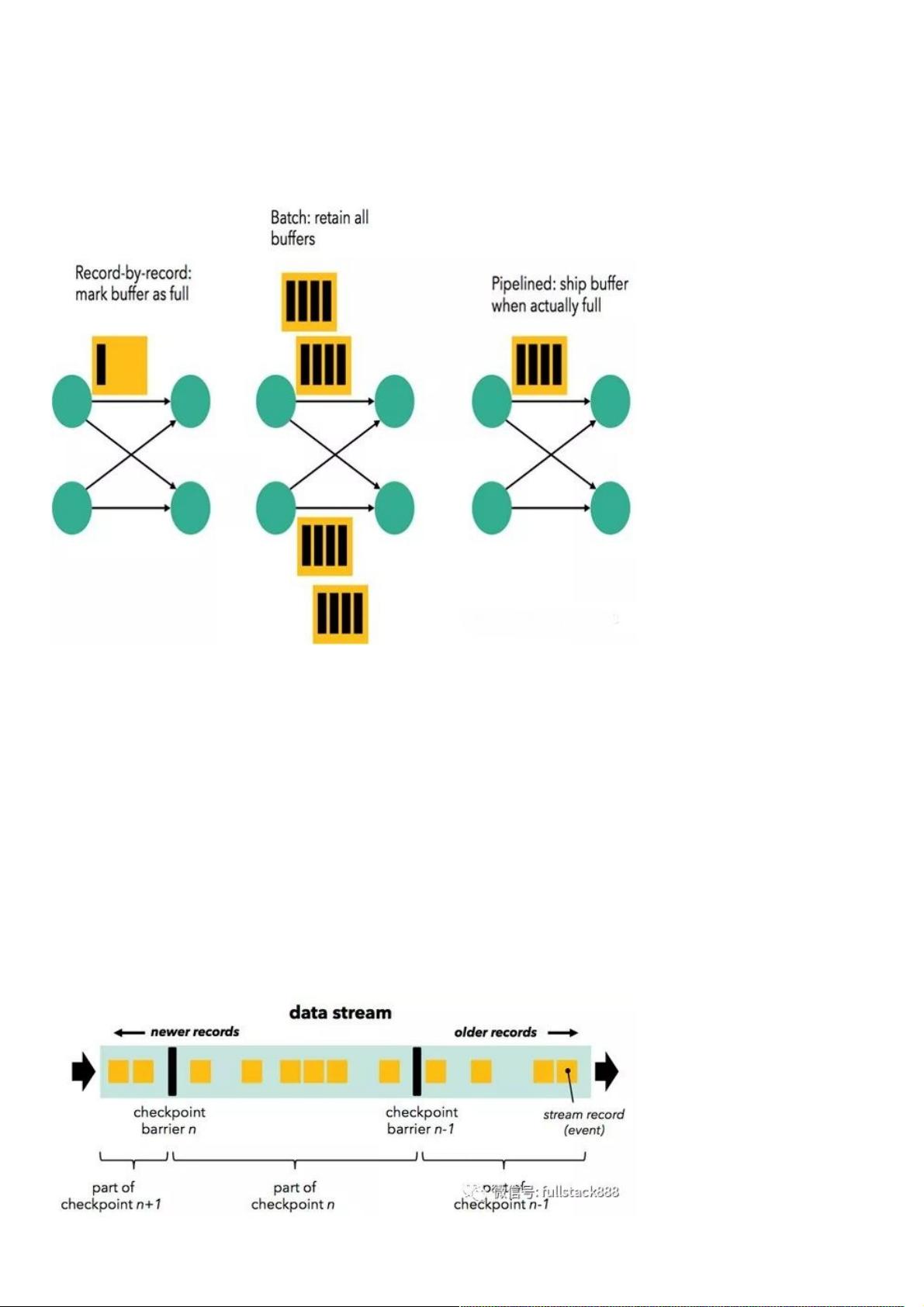
在执行引擎这一层,流处理系统与批处理系统最大不同在于节点间的数据传输方式。对于一个流处理系统,其节点间数据传输
的标准模型是:当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理。
而对于一个批处理系统,其节点间数据传输的标准模型是:当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络
剩余7页未读,继续阅读

weixin_38591291
- 粉丝: 6
- 资源: 957









最新资源
- C语言-leetcode题解之61-rotate-list.c
- C语言-leetcode题解之59-spiral-matrix-ii.c
- C语言-leetcode题解之58-length-of-last-word.c
- 计算机编程课程设计基础教程
- (源码)基于C语言的系统服务框架.zip
- (源码)基于Spring MVC和MyBatis的选课管理系统.zip
- (源码)基于ArcEngine的GIS数据处理系统.zip
- (源码)基于JavaFX和MySQL的医院挂号管理系统.zip
- (源码)基于IdentityServer4和Finbuckle.MultiTenant的多租户身份认证系统.zip
- (源码)基于Spring Boot和Vue3+ElementPlus的后台管理系统.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0