
机器学习代码实战机器学习代码实战——KMeans(聚类)(聚类)
文章目录文章目录1.实验目的2.导入必要模块3.用pandas处理数据4.拟合+预测5.把预测结果合并到DF6.可视化聚类效果7.比较不同的簇数的均方误差8.对数据归一化处理
1.实验目的实验目的
1.使用sklearn库中的鸢尾花数据集,并尝试使用花瓣的宽度和长度特征来形成簇簇。
2. 为简单起见,删除其他两个特征。
3. 找出是否有任何预处理(例如缩放)可以帮助解决问题,绘制肘部曲线,从中得出得出k的最佳值的最佳值
2.导入必要模块导入必要模块
from sklearn.cluster import KMeans #从sklearn导入KMeans算法
import pandas as pd
from sklearn.preprocessing import MinMaxScaler #数据预处理中的缩放模块
from matplotlib import pyplot as plt
from sklearn.datasets import load_iris #从sklearn导入iris数据
%matplotlib inline
3.用用pandas处理数据处理数据
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names) #构建df
df.drop(['sepal length (cm)','sepal width (cm)'],axis = 'columns',inplace = True) #只取两个特征,故把另外两个特征drop掉
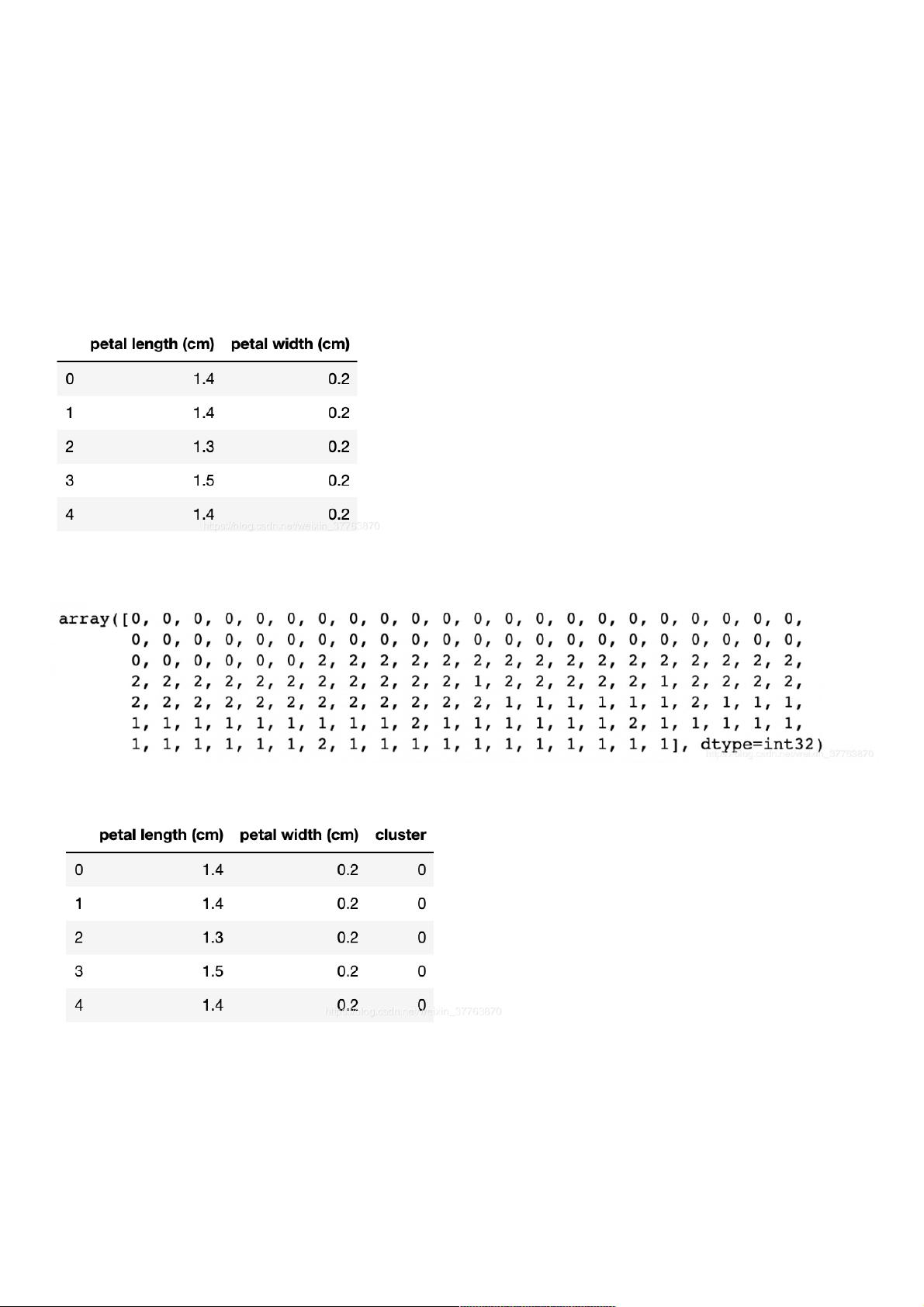
df.head() #打印前5条记录检验操作是否正确
4.拟合拟合+预测预测
km = KMeans(n_clusters=3) #设定超参数聚类数为3
y_predicted = km.fit_predict(df) #拟合+预测
y_predicted #打印聚类结果(0表示第1个簇,1表示第2个簇,2表示第3个簇)
5.把预测结果合并到把预测结果合并到DF
df['cluster'] = y_predicted
df.head()
6.可视化聚类效果可视化聚类效果
df1 = df[df.cluster==0] #过滤出簇0
df2 = df[df.cluster==1] #过滤出簇1
df3 = df[df.cluster==2] #过滤出簇2
plt.scatter(df1['petal length (cm)'],df1['petal width (cm)'],color='blue') #画簇0的散点图
plt.scatter(df2['petal length (cm)'],df2['petal width (cm)'],color='green') #画簇1的散点图
plt.scatter(df3['petal length (cm)'],df3['petal width (cm)'],color='yellow') #画簇2的散点图
plt.scatter(km.cluster_centers_[:,0],km.cluster_centers_[:,1],color='red',marker='+',label='centroid') #画每个簇的中心

weixin_38584043
- 粉丝: 4
- 资源: 946









最新资源
- 基于微信的垃圾分类小程序springboot.zip
- stm32驱动摄像头ov7670源程序
- 微信小程序评分小程序ssm.zip
- 基于微信小程序的在线学习系统springboot.zip
- 基于微信小程序的汽车销售系统的设计与实现springboot.zip
- 球馆预约系统ssm.zip
- 基于java的餐厅点餐系统微信小程序ssm.zip
- 基于微信小程序的走失人员的报备平台设计ssm.zip
- 基于微信小程序的社区门诊管理系统php.zip
- 基于微信小程序的新生报到系统的设计与实现ssm.zip
- 学生资助在线管理软件开发微信小程序ssm.zip
- 圣诞树html网页代码.zip
- unity 微信小游戏 文本内容检测
- 基于libos架构的操作系统核心库及构建工具
- springboot项目快速实现国际化 若依前后端分离版-快速国际化集成
- AigcPanel 是一个简单易用的一站式AI数字人系统,支持视频合成、声音合成、声音克隆,简化本地模型管理、一键导入和使用AI模型
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论5