

这年头学爬虫还就得会点这年头学爬虫还就得会点 scrapy 框架框架
Hello,我是 Alex 007,为啥是007呢?因为叫 Alex 的人太多了,再加上每天007的生活,Alex 007就诞生了。
这几天一直在练车,只能在中间休息的时候写一写博客,可怜去年报的名到现在还没有拿到小本本,当然练车只是副技能,主技能还是coding,不断学习才能不被淘汰。
最近在学爬虫的 scrapy 框架,以前虽然拿 GoLang 玩过爬虫,可惜没有太深入,这次拿 Python 好好学一学。
学习爬虫过程中的代码都放在了GitHub上:https://github.com/koking0/Spider
小生才疏学浅,如有谬误,恭请指正。
文章目录文章目录一、初探 Scrapy1.Scrapy 的安装2.第一个 scrapy 项目二、基本操作1.持久化存储(1)基于终端指令的持久化存储(2)基于管道的持久化存储2.全站数据爬取请求传参3.图
片下载
一、初探一、初探 Scrapy
先来看一下官网的定义:
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages.
Scrapy是一个快速的高级web抓取框架,用于抓取网站和从网页中提取结构化数据。
It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
它可以用于广泛的用途,从数据挖掘到监控和自动化测试。
from
2020-04-09 21:48:47 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
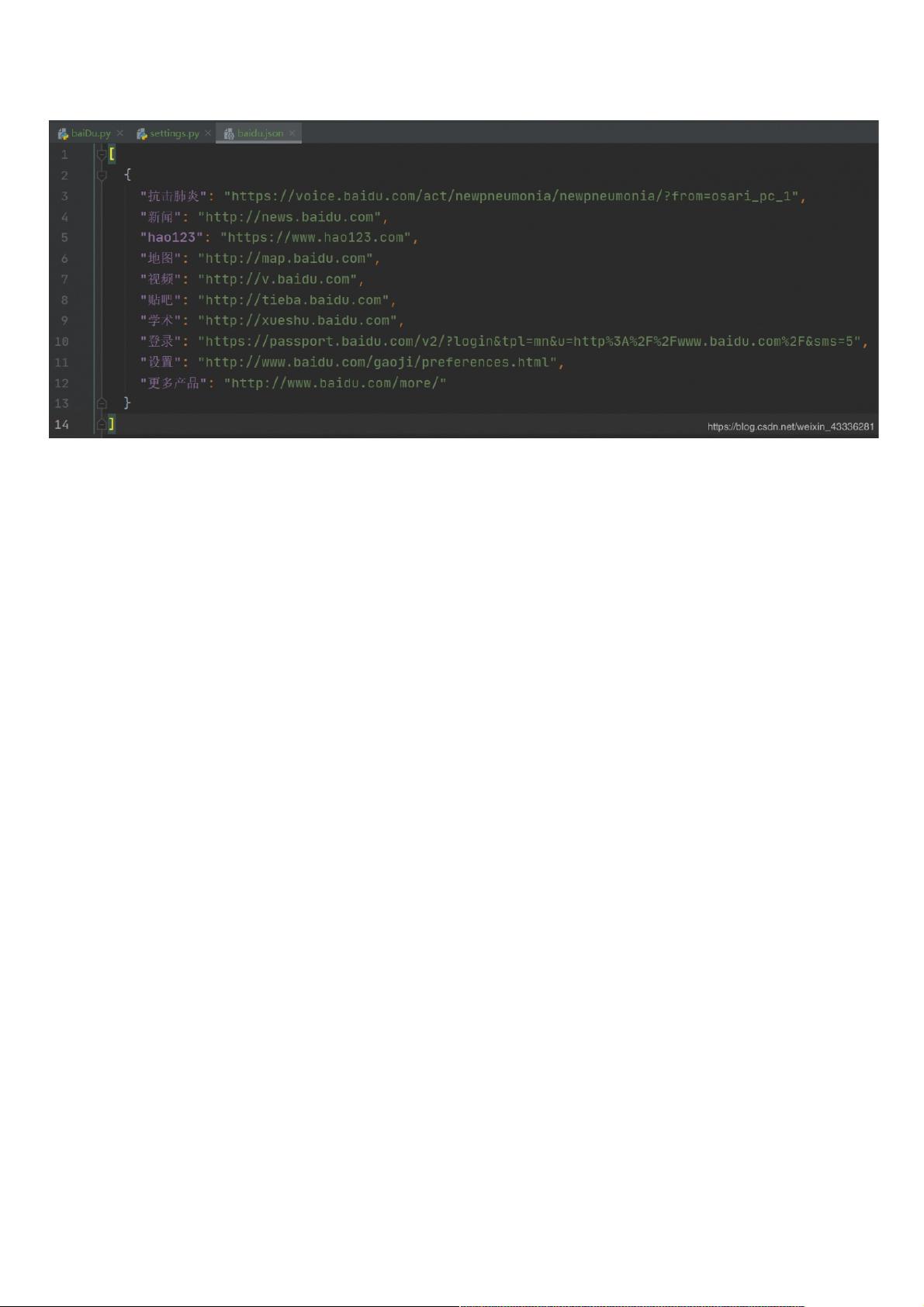
抗击肺炎 https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_pc_1
新闻 http://news.baidu.com
hao123 https://www.hao123.com
地图 http://map.baidu.com
视频 http://v.baidu.com
贴吧 http://tieba.baidu.com
学术 http://xueshu.baidu.com
登录 https://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F&sms=5
设置 http://www.baidu.com/gaoji/preferences.html
更多产品 http://www.baidu.com/more/
2020-04-09 21:48:47 [scrapy.core.engine] INFO: Closing spider (finished)
2020-04-09 21:48:47 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{‘downloader/request_bytes’: 732,
‘downloader/request_count’: 2,
‘downloader/request_method_count/GET’: 2,
‘downloader/response_bytes’: 53325,
‘downloader/response_count’: 2,
‘downloader/response_status_count/200’: 1,
‘downloader/response_status_count/302’: 1,
‘elapsed_time_seconds’: 0.491685,
‘finish_reason’: ‘finished’,
‘finish_time’: datetime.datetime(2020, 4, 9, 13, 48, 47, 901362),
‘log_count/DEBUG’: 2,
‘log_count/INFO’: 10,
‘response_received_count’: 1,
‘scheduler/dequeued’: 2,
‘scheduler/dequeued/memory’: 2,
‘scheduler/enqueued’: 2,
‘scheduler/enqueued/memory’: 2,
‘start_time’: datetime.datetime(2020, 4, 9, 13, 48, 47, 409677)}
2020-04-09 21:48:47 [scrapy.core.engine] INFO: Spider closed (finished)
scrapy 给我们输出了很多很多东西,我们的打印结果被放在了中间,其它的内容其实是日志信息,scrapy 帮我们自动生成了日志,如果你觉得碍眼的话,可以通过 settings.py 文件
中的设置只保留错误信息:
LOG_LEVEL = 'ERROR'
二、基本操作二、基本操作
接下来了解一下 scrapy 框架的一些基本操作,比如爬取数据的持久化存储啦,对网站的全站爬取啦还有图片下载等功能。
1.持久化存储持久化存储
爬取到的数据只有保存到本地的电脑上才是自己的,不然只在内存里,用完就没了。
((1)基于终端指令的持久化存储)基于终端指令的持久化存储
在前边的小试牛刀中我们可以看到控制台的输出,其实基于终端指令的持久化存储就是将终端的输出结果重定向到一个本地文件中。
使用基于终端指令的持久化存储必须保证爬虫文件中的 parse 方法中有可迭代对象返回,通常是列表或者字典。
我们把爬取百度顶部菜单栏的爬虫 parse 方法升级一下:
def parse(self, response):
# xpath 为 response 的方法,可以直接写 xpath 表达式
aList = response.xpath('//*[@id="u1"]/a')
data = {}
for item in aList:
name = item.xpath('.//text()')[0].extract()
url = item.xpath('./@href')[0].extract()
data[name] = url
return data
然后在 settings.py 文件中写一下文件编码的配置,保证使用的是 utf-8 编码方式:
剩余6页未读,继续阅读
资源评论


weixin_38571878
- 粉丝: 5
- 资源: 935









最新资源
- 手套手势检测7-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- CentOS bridge 工具包 bridge-utils-1.6-1.33.x86-64.rpm
- 手势检测7-YOLO(v5至v11)、COCO、CreateML、Paligemma、TFRecord、VOC数据集合集.rar
- 基于python flask实现某瓣数据可视化数据分析平台
- awewq1132323
- 手写流程图检测31-YOLO(v5至v8)、COCO、CreateML、Darknet、Paligemma、TFRecord数据集合集.rar
- frida拦截微信小程序云托管API
- 肝脏及其肿瘤分割的 CT 数据集,已经切片成jpg数据,约2w张数据和mask
- 基于Java的网上教务评教管理系统的设计与实现.doc
- 2024圣诞节海外消费市场趋势及营销策略分析报告
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


