

On the Optimal Provider Selection
for Repair in Distributed Storage System
with Network Coding
Chengjin Jia
1
,JinWang
1(
B
)
,YanqinZhu
1
,
Xin Wang
2
, Kejie Lu
3,4
, Xiumin Wang
5
, and Zhengqing Wen
1
1
Department of Computer Science and Technology,
Soochow University, Suzhou 215006, China
wjin1985@suda.edu.cn
2
School of Computer Science, Fudan University, Shanghai 200433, China
3
College of Computer Science and Technology,
Shanghai University of Electronic Power, Shanghai 200444, China
4
Department of Electrical and Computer Engineering,
University of Puerto Rico at Mayag¨uez, Mayag¨uez 00681-9000, USA
5
School of Computer and Information, Hefei University of Technology,
Hefei 230000, China
Abstract. In large-scale distributed storage systems (DSS), reliabil-
ity is provided by redundancy spread over storage servers across the
Internet. Network coding (NC) has been widely studied in DSS because
it can improve the reliability with low repair time. To maintain reli-
ability, an unavailable storage server should be firstly replaced by a
new server, named new comer. Then, multiple storage servers, called
providers, should be selected from surviving servers and send their coded
data through the Internet to the new comer for regenerating the lost
data. Therefore, in a large-scale DSS, provider selection and data rout-
ing during the regeneration phase have great impact on the performance
of regeneration time. In this paper, we investigate a problem of optimal
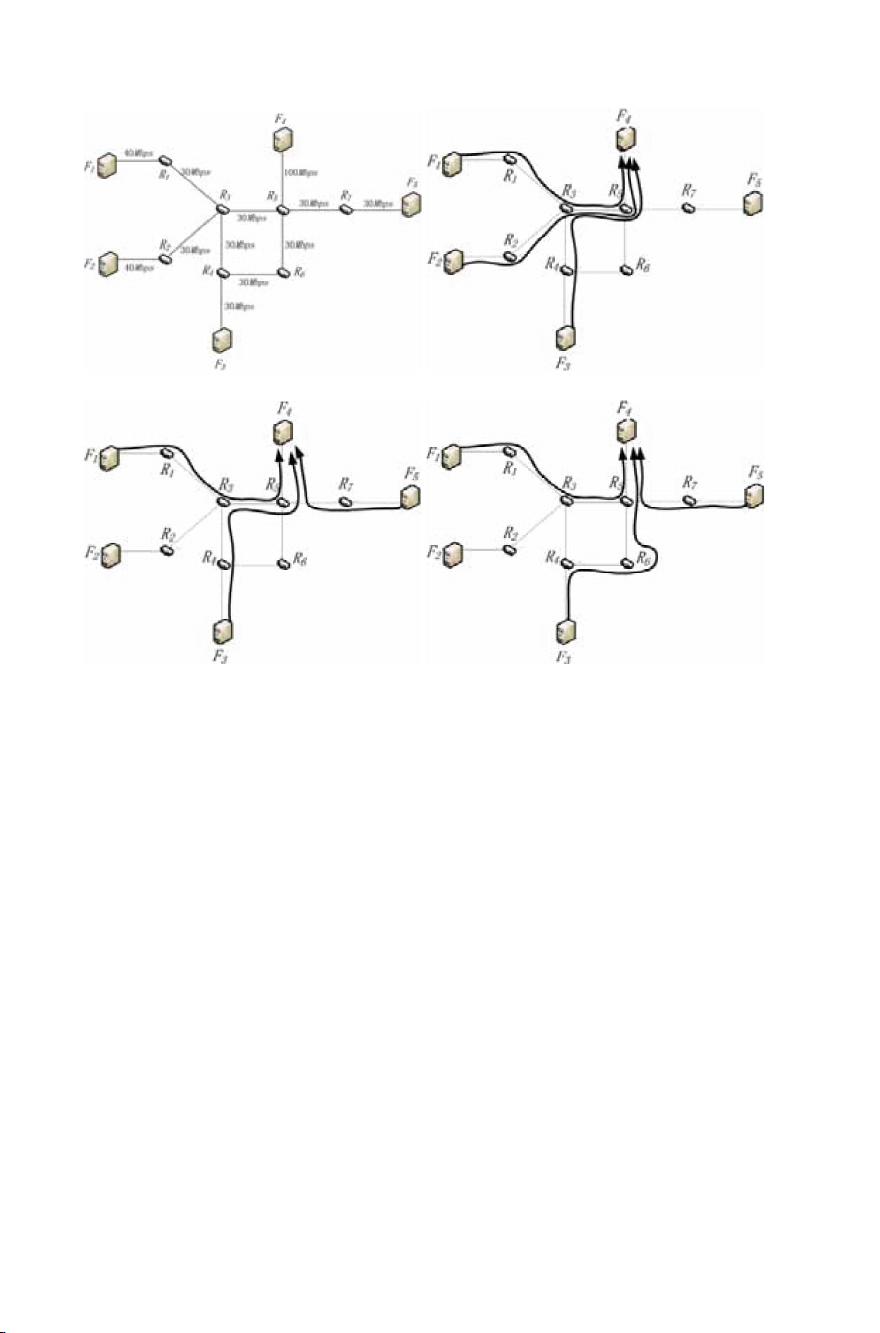
provider selection and data routing for minimizing the regeneration time
in the DSS with NC. Specifically, we first define the problem in the DSS
with NC. For the case that the providers are given, we model the problem
as a mathematical programming. Based on the mathematical program-
ming, we then formulate the optimal provider selection and data routing
problem as an integer linear programming problem and develop an effi-
cient near-optimal algorithm based on linear programming relaxation
(BLP). Finally, extensive simulation experiments have been conducted,
and the results show the effectiveness of the proposed algorithm.
Keywords: Network coding
· Distributed storage system · Provider
selection
· Routing · Linear programming · LP relaxation
1 Introduction
With the rapid development of big data, the information explosion results in
the rapid development of data storage. There are about 5 Exabytes independent
c
Springer International Publishing Switzerland 2015
G. Wang et al. (Eds.): ICA3PP 2015, Part IV, LNCS 9531, pp. 506–520, 2015.
DOI: 10.1007/978-3-319-27140-8
35

剩余14页未读,继续阅读
资源评论













