
RES E A R C H P A P E R Open Access
An multi-scale learning network with
depthwise separable convolutions
Gaihua Wang
1,2
, Guoliang Yuan
2*
, Tao Li
2
and Meng Lv
2
Abstract
We present a simple multi-scale learning networ k for image classification that is i nspired by the MobileNet.
The proposed method has two advantages: (1) It uses the multi-scale block with depthwise separable convolutions,
which forms multiple sub-networks by increasing the width of the network while keeping the computational resources
constant. (2) It combines the multi-scale block with residual connections and that accelerates the training of networks
significantly. The experimental results show that the proposed method has strong performance compared to other
popular models on different datasets.
Keywords: Multi-scale, MobileNet, Residual connections, Image classification
1 Introduction
Convolutional neural network (CNN) has been proposed
since the late 1970s [1], and the first successful applica-
tion is the LeNet [2]. In CNNs, weights in the network
are shared, and pooling layers are spatial or tempor al
sampling using invariant function [3, 4]. In 2012,
AlexNet [5] was proposed to use rectified linear units
(ReLU) instead of the hyperbolic tangent as activation
function while adding dropout network [6] to decrease
the effect of overfitting. In subsequent years, further pro-
gress has been made by using deeper architectures [7–10].
For multiple-scale leaning network, in 2015, He et al.
[11] proposed a ResNet architecture that consists of many
stacked “residual units.” Szegedy et al. [12]proposedan
inception module by using a combination of all filter sizes
1 × 1, 3 × 3, and 5 × 5 into a single output vector. In 2017,
Xie [13] proposed the ResNeXt network structure, which
is a multiple-scale network by using “cardinality” as an es-
sential factor. Moreover, the multiple-scale architectures
have also been successfully employed in the detection [14]
and feature selection [15]. The bigger size means a larger
number of parameters, which makes the network prone to
overfitting. In addition, larger network size can increase
computational resources. Some efficient network architec-
tures [16, 17] are proposed in order to build smaller, lower
latency models. The MobileNet [18] is built primarily by
depthwise separable convolutions for mobile and
embedded vision applications. The ShuffleNet [19]
utilizes pointwise group convolution and channel
shuffle t o greatly reduce the computation cost while
maintaining the accuracy.
Motivated by the analysis above, in this paper, we use
the multiple-scale network to construct a convolutional
module. Different sizes can become more robust to scale
the changes. Then, we use depthwise separable convolu-
tions to modify the convolutional module. In addition,
residual connections are combined into the network.
The experimental results show that the proposed
method has better performance and less parameter on
different benchmark datasets for image classification.
The remaining of this paper is organized as follows:
Section 2 reviews the related work. Section 3 details the
architecture of the proposed method. Section 4 describes
our experiment and discusses the results of our experi-
ments. Section 5 concludes the paper.
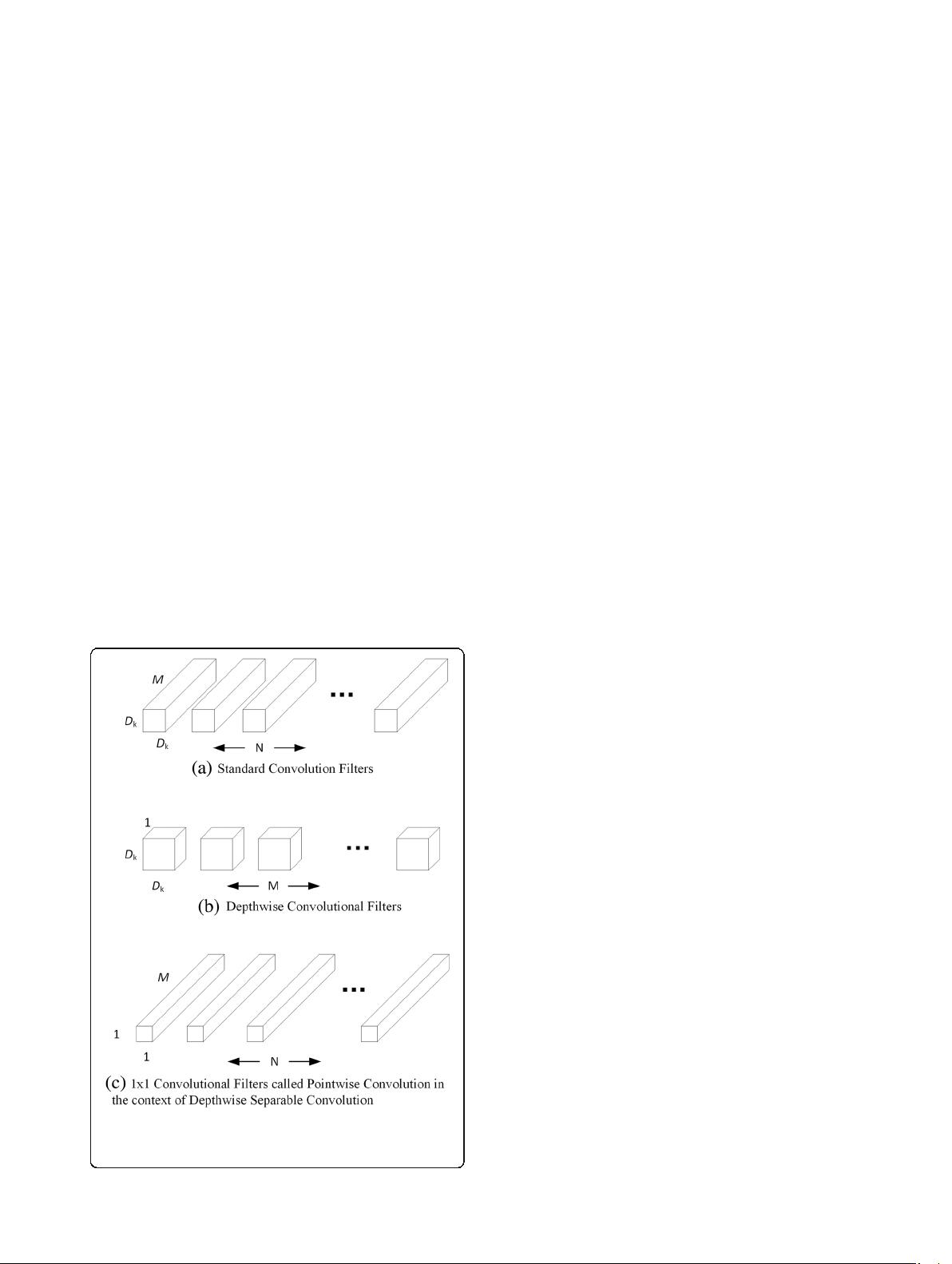
2 The depthwise separable convolutions
Depthwise separable convolutions divide standard convo-
lution into a depthwise convolution and a 1 × 1 pointwise
convolution [18]. The depthwise convolution applies a
single filter to each input channel, given the feature map
is expressed by D
F
× D
F
× M. Depthwise convolution with
one filter per input is as follows (Eq. (1)):
* Correspondence: guoliang_yuan@hotmail.com
2
School of Electrical and Electronic Engineering, Hubei University of Technology,
Wuhan 430068, China
Full list of author information is available at the end of the article
I
PSJ Transactions on Compute
r
Vision and A
pp
lication
s
© The Author(s). 2018 Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0
International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and
reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to
the Creative Commons license, and indicate if changes were made.
Wang et al. IPSJ Transactions on Computer Vision and Applications
(2018) 10:11
https://doi.org/10.1186/s41074-018-0047-6
剩余7页未读,继续阅读
资源评论













