
python实现高斯判别分析算法的例子实现高斯判别分析算法的例子
今天小编就为大家分享一篇python实现高斯判别分析算法的例子,具有很好的参考价值,希望对大家有所帮助。一起跟随
小编过来看看吧
高斯判别分析算法(高斯判别分析算法(Gaussian discriminat analysis))
高斯判别算法是一个典型的生成学习算法(关于生成学习算法可以参考我的另外一篇博客)。在这个算法中,我们假设p(x|y)p(x|y)服从多
元正态分布。
注:在判别学习算法中,我们假设p(y|x)p(y|x)服从一维正态分布,这个很好类比,因为在模型中输入数据XX通常是拥有很多维度的,所
以对于XX的条件概率建模时要取多维正态分布。
多元正态分布多元正态分布
多元正态分布也叫多元高斯分布,这个分布的两个参数分别是平均向量μ∈Rnμ∈Rn和一个协方差矩阵∑∈Rn×n∑∈Rn×n
关于协方差矩阵的定义;假设XX是由nn个标量随机变量组成的列向量,并且μkμk是第kk个元素的期望值,即μk=E(Xk)μk=E(Xk),那么协
方差矩阵被定义为
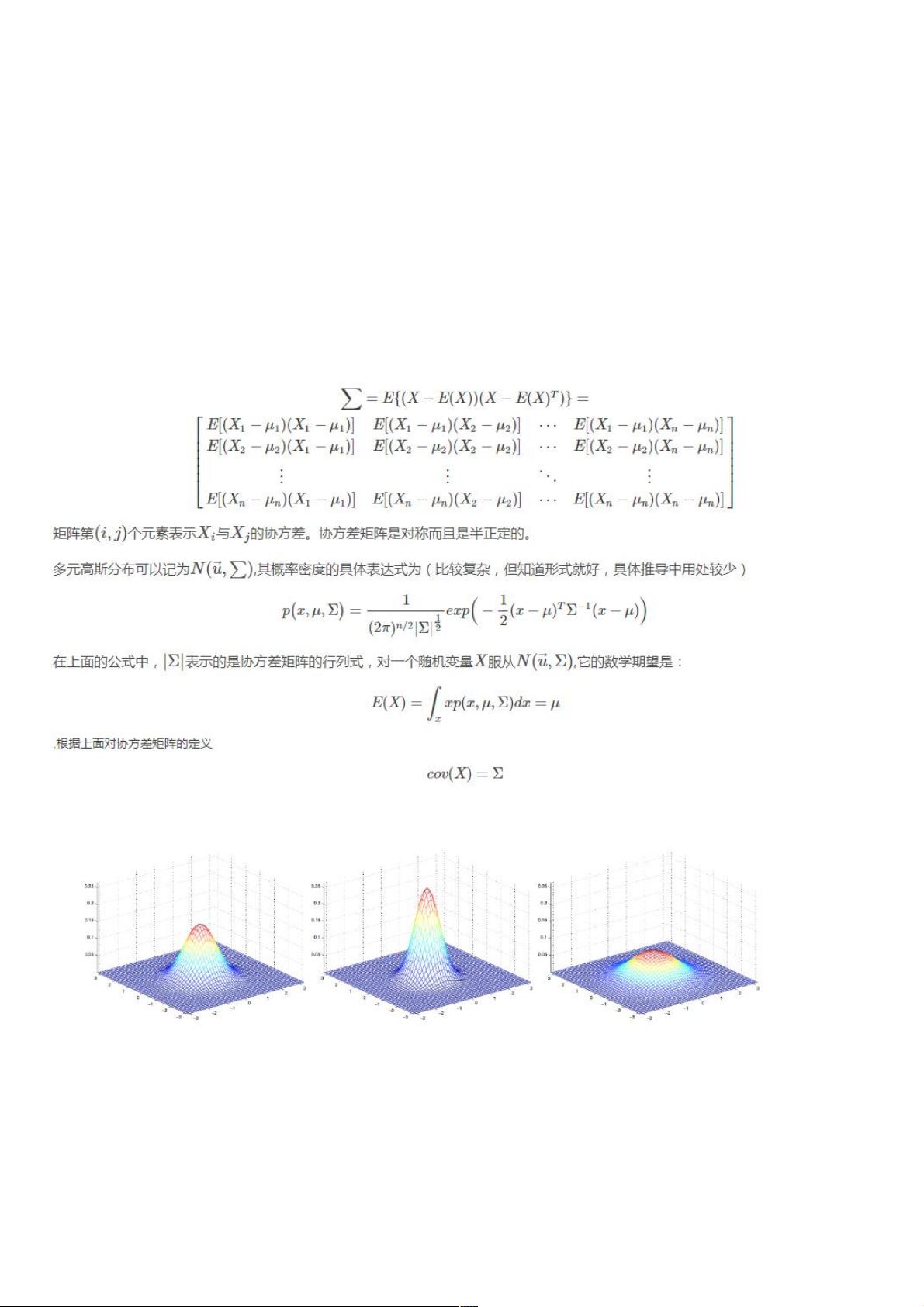
下面是一些二维高斯分布的概率密度图像:下面是一些二维高斯分布的概率密度图像:
最右边的图像展现的二维高斯分布的均值是零向量(2x1的零向量),协方差矩阵Σ=IΣ=I(2x2的单位矩阵),像这样以零向量为均值以单位
阵为协方差的多维高斯分布称为标准正态分布,中间的图像以零向量为均值,Σ=0.6IΣ=0.6I;最右边的图像中Σ=2IΣ=2I,观察发现当ΣΣ越
大时,高斯分布越“铺开”,当ΣΣ越小时,高斯分布越“收缩”。
让我们看一些其他例子对比发现规律让我们看一些其他例子对比发现规律
资源评论


weixin_38522253
- 粉丝: 2
- 资源: 877









最新资源
- 四旋翼飞行器轨迹跟踪仿真 控制 路径规划与轨迹优化MATLAB四旋翼飞行器仿真无人机simulink有公式说明文档
- STC12C5A60S2单片机做Modbus通讯,FX1N基本程序转成单片机程序,可以通过触摸屏人机界面操作,没有实物硬件
- 关键词: 拉丁超立方抽样;k-means聚类;光伏不确定性; 主题: 采用LHS进行场景生成,k-means聚类进行场景削减,假设预测服从期望为 0,方差为2的正态分布
- 优化svm分类器,优化lssvm分类器,优化Bp 分类器等等 有大量2021最新优化算法优化,群智能优化算法及其改进 深度置信网络 可做故障诊断分类,预测任务等 Matlab代码,原创最近,可
- 全桥LLC谐振变器simulink仿真 3kw,输入电压590-610V,额定输出电压100V 开环控制,包括欠谐振,准谐振和过谐振三种工作情况的仿真 电压闭环PI控制,在输入电压跳变和负载跳变时输出
- S7-200 MCGS 基于S7-200西门子PLC汽车自动清洗机控制系统
- 正在使用的纵剪分切设备程序,高速分切速度可达140米 分,分切速度快,分切效果好 收放卷取自动同步调整跟踪,分切一致性好 程序含变频控制收放频率卷取算法,可了解后用于卷取设备 用于变频控制的纵剪
- 带死区、抗积分饱和、梯形积分、变积分算法以及不完全微分算法的增量型PID控制器
- 欧姆龙CP1H CIF11与3台东元Teco N310变频器通讯实战程序 功能:原创程序,可直接用于现场程序 欧姆龙CP1H的CIF11通讯板,实现对3台东元Teco N310变频器 设定
- 台达DVP ES系列与东元Teco N310变频器通讯实战程序 器件:台达DVP ES系列的PLC,东元Teco N310系列变频器,昆仑通态 功能:实现频率设定,启停控制,实际频率读
- 台达DVP ES系列与3台东元Teco N310变频器通讯实战程序 器件:台达DVP ES系列的PLC,3台东元Teco N310系列变频器,昆仑通态 功能:实现频率设定,启停控制,实
- 三菱FX1s与3台东元N310变频器通讯实战程序 直接拿来实用了,三菱FX PLC与东元N310变频器modbus RTU通讯 采用器件:三菱FX1s 30MR PLC,1个FX1N
- 基于PLC和组态软件的智能停车场收费系统停车场电气控 带解释的梯形图程序,接线图原理图图纸,io分配,组态画面
- 电压闭环控制的全桥LLC谐振变器仿真,分别采用(自抗扰控制和pi控制)两种方式 含负载跳变,可验证闭环控制的稳定性,任选一个
- 三菱FX1s与台达MS300变频器通讯实战程序 可直接拿来实用了,三菱FX PLC与台达变频器modbus RTU通讯 采用器件:三菱FX1s 30MR PLC,1个FX1N 485B
- 三菱FX1N与3台东元Teco N310变频器通讯实战程序 可直接拿来实用了,三菱FX PLC与东元N310变频器modbus RTU通讯 采用器件:三菱FX1N 24MT PLC,1
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


