
SQL Server 跨库同步数据跨库同步数据
主要为大家详细介绍了SQL Server 跨库同步数据的实现方法,具有一定的参考价值,感兴趣的小伙伴们可以参考一
下
最近有个需求是要跨库进行数据同步,两个数据库分布在两台物理计算机上,自动定期同步可以通过SQL Server代理作业来实现,
但是前提是需要编写一个存储过程来实现同步逻辑处理。这里的存储过程用的不是opendatasource,而是用的链接服务器来实现
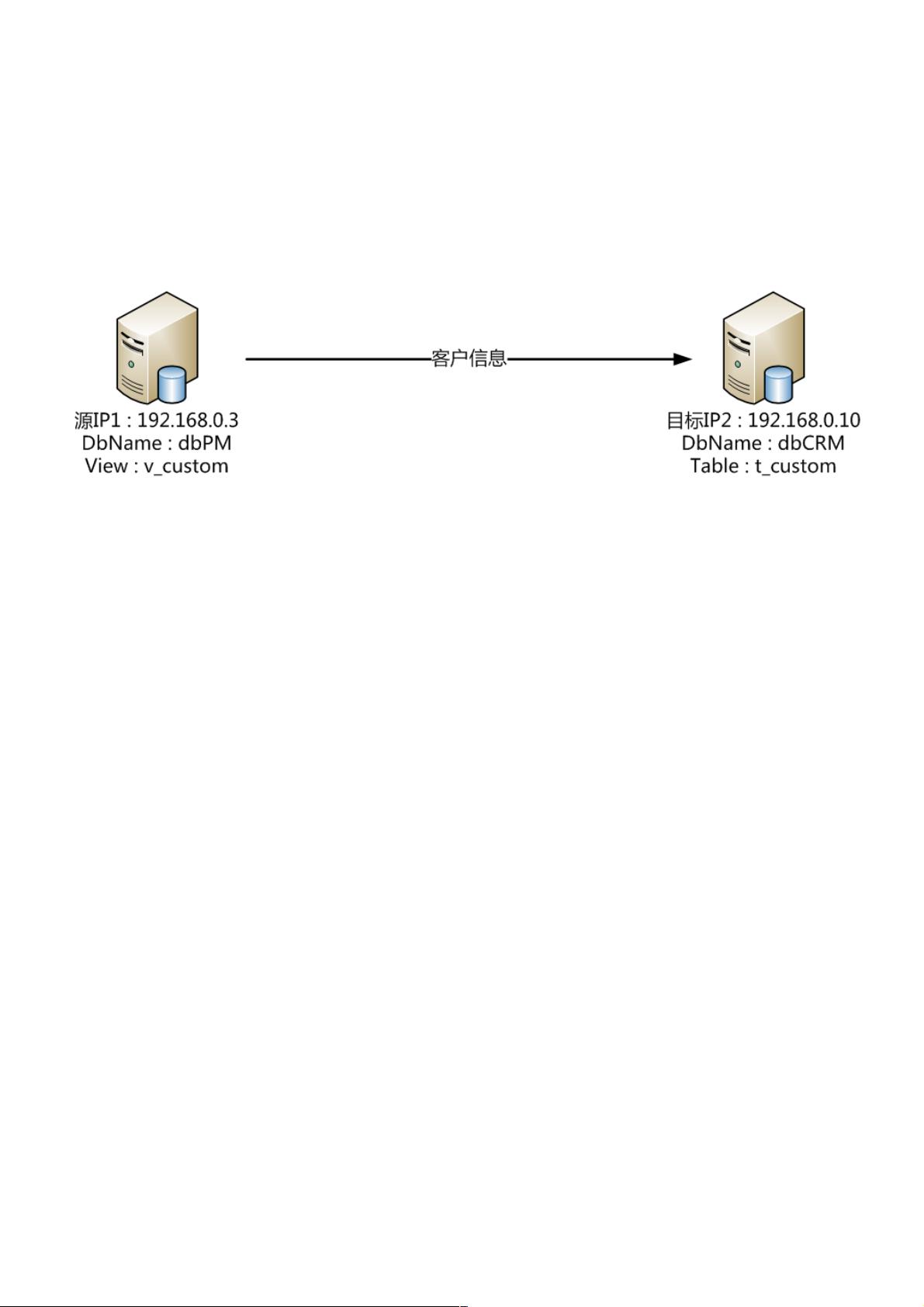
的。存储过程创建在IP1:192.168.0.3服务器上,需要将视图v_custom的客户信息同步到IP2:192.168.0.10服务器上的t_custom表
中。逻辑是如果不存在则插入,存在则更新字段。
create PROCEDURE [dbo].[p_pm_项目平台客户批量同步到报销平台](
@destserver nvarchar(50),
@sourceserver nvarchar(50)
)
AS
BEGIN
SET NOCOUNT ON;
--不存在则添加链接服务器,外部查询必须指明IP地址,例如 select * from [IP].[database].[dbo].[table]
if not exists (select * from sys.servers where server_id!=0 and data_source=@destserver)
begin
exec sp_addlinkedserver @server=@destserver
end
if not exists (select * from sys.servers where server_id!=0 and data_source=@sourceserver)
begin
exec sp_addlinkedserver @server=@sourceserver
end
begin try
set xact_abort on
begin transaction
INSERT INTO [192.168.0.10].[dbCRM].[dbo].[t_custom] (客户ID,
客户名称,
客户简称,
输入码,
查询码,
地址,
录入登录名,
录入时间,
修改登录名,
修改时间,
审批状态ID,
审批状态名称,
是否审批结束,
审批操作时间,
项目管理客商编码,
序号)
SELECT A.客户ID,A.客户名称,
A.客户简称,
dbo.fn_pm_GetPy(A.客户名称),
A.客户编号+','+A.客户名称+','+dbo.fn_pm_GetPy(A.客户名称)+','+A.客户简称+','+dbo.fn_pm_GetPy(A.客户简称),
A.地址,
'admin',
getdate(),
null,
null,
'D65F87A8-79C8-4D1C-812D-AE4591E056A8',
'已审批',
1,
A.审批操作时间,
A.项目管理客商编码,
0
资源评论













