使用Python和百度语音识别生成视频字幕的实现
40 浏览量
2020-09-17
14:28:35
上传
评论 2
收藏 100KB PDF 举报

使用使用Python和百度语音识别生成视频字幕的实现和百度语音识别生成视频字幕的实现
主要介绍了使用Python和百度语音识别生成视频字幕,文中通过示例代码介绍的非常详细,对大家的学习或者工作
具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
从视频中提取音频从视频中提取音频
安装 moviepy
pip install moviepy
相关代码:
audio_file = work_path + '\out.wav'
video = VideoFileClip(video_file)
video.audio.write_audiofile(audio_file,ffmpeg_params=['-ar','16000','-ac','1'])
根据静音对音频分段根据静音对音频分段
使用音频库 pydub,安装:
pip install pydub
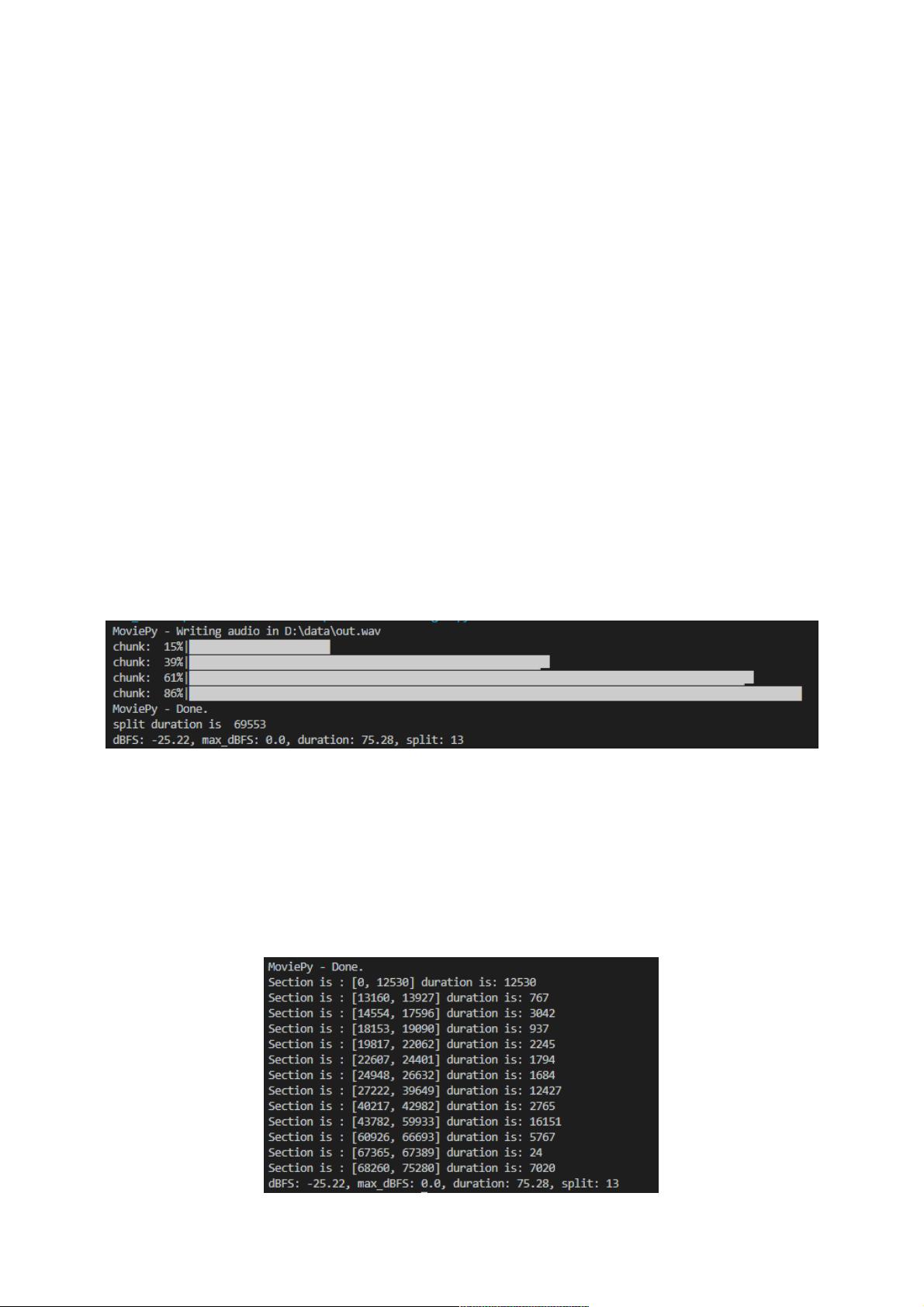
第一种方法:
# 这里silence_thresh是认定小于-70dBFS以下的为silence,发现小于 sound.dBFS * 1.3 部分超过 700毫秒,就进行拆分。这样子分割成一段一段的。
sounds = split_on_silence(sound, min_silence_len = 500, silence_thresh= sound.dBFS * 1.3)
sec = 0
for i in range(len(sounds)):
s = len(sounds[i])
sec += s
print('split duration is ', sec)
print('dBFS: {0}, max_dBFS: {1}, duration: {2}, split: {3}'.format(round(sound.dBFS,2),round(sound.max_dBFS,2),sound.duration_seconds,len(sounds)))
感觉分割的时间不对,不好定位,我们换一种方法:
# 通过搜索静音的方法将音频分段
# 参考:https://wqian.net/blog/2018/1128-python-pydub-split-mp3-index.html
timestamp_list = detect_nonsilent(sound,500,sound.dBFS*1.3,1)
for i in range(len(timestamp_list)):
d = timestamp_list[i][1] - timestamp_list[i][0]
print("Section is :", timestamp_list[i], "duration is:", d)
print('dBFS: {0}, max_dBFS: {1}, duration: {2}, split: {3}'.format(round(sound.dBFS,2),round(sound.max_dBFS,2),sound.duration_seconds,len(timestamp_list)))
输出结果如下:
感觉这样好处理一些
使用百度语音识别使用百度语音识别






评论0
最新资源