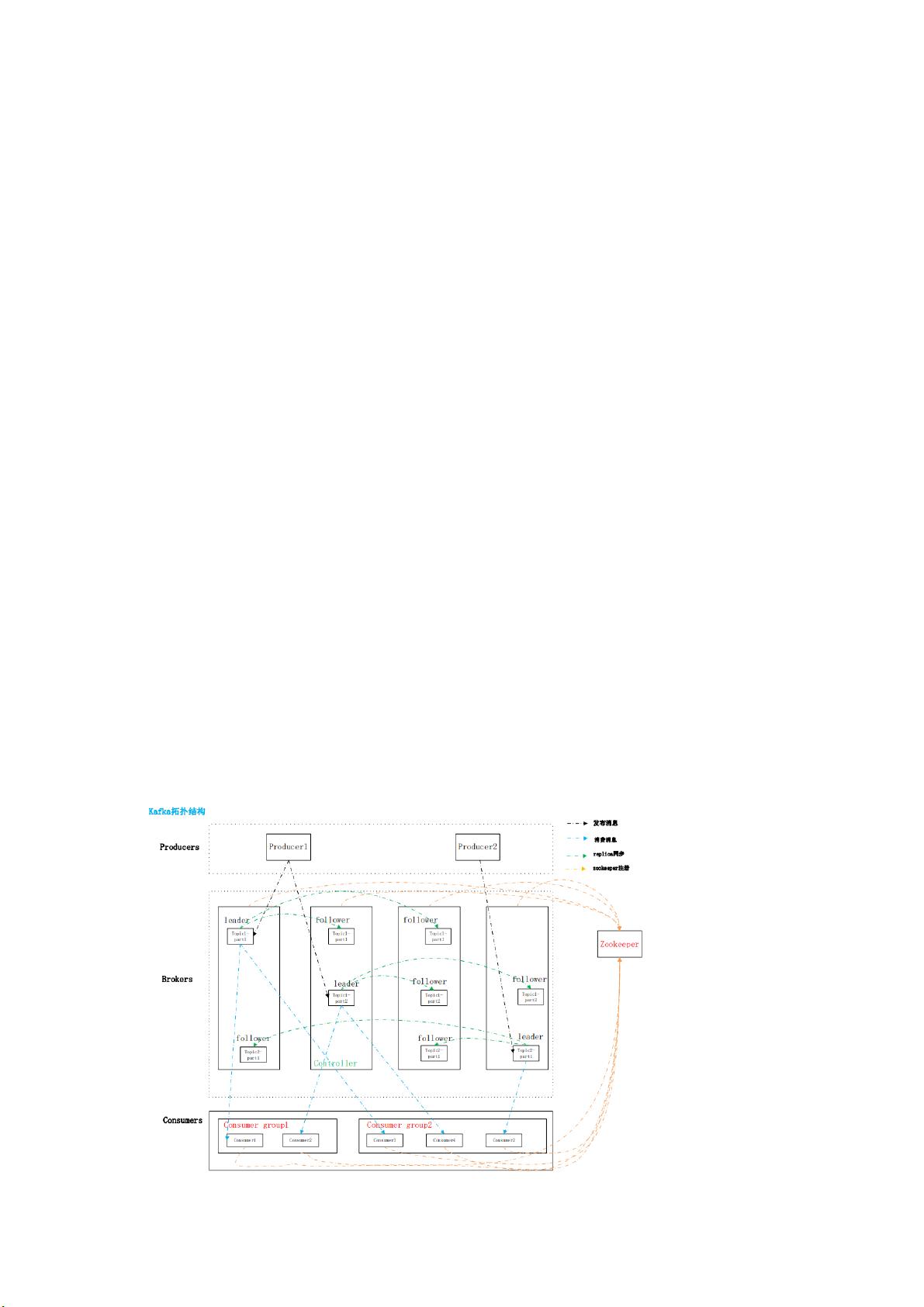
➢ producer:消息生产者,就是向 kafka broker 发消息的客户端
➢ consumer:消息消费者,向 kafka broker 取消息的客户端。
➢ consumer group:单个或者多个 consumer 可以组成一个 consumer group;这是 kafka
用来实现消息的广播(发个所有的 consumer)和单播(发送给任意一个 consumer)的
手段。一个 topic 可以有多个 consumer group。
➢ topic:数据的逻辑分类,地位等同于数据库中“表”的概念;
➢ partition:topic 中数据的具体管理单元,可以理解为 hbase 中的“region”概念;一个
topic 可以划分为多个 partition,分别到多个 broker 上管理,每个 partition 由
一个 kafka broker 服务器管理;
partition 中的每个消息都会被分配一个递增的 id(offset);每个 partition 是一个有序的
队列,kafka 只保证按一个 partition 中的消息的顺序,不保证一个 topic 的整体(多个
partition 间)的顺序。
➢ broker:一台 kafka 服务器就是一个 broker。一台 kafka 集群由对勾 broker 组成。一个
broker 可以容纳多个 topic 组成的多个 partition。
➢ offset:消息在底层中索引的位置,kafka 底层的存储文件就是以文件中第一条消息的
offset 来命名的,通过 offset 可以快速定位到消息的具体存储位置。
➢ leader:partition replica 中的一个角色,producer 和 consumer 只跟 leader 交互(负责
读写)。
➢ 副本 replica:partition 的副本,保障 partition 的高可用(replica 副本数目不能大于 kafka
broker 节点的数目,否则报错)
每个 partition 的所有副本中,必包括一个 leader 副本,其他的就是 follower 副本。
➢ follower:partition replica 中一个角色,从 leader 中拉取复制数据(只负责备份)。
如果 leader 节点宕机,follower 会从中选出新的 leader。
➢ 偏移量 offset:每一条数据都有一个 offset,是数据在该 partition 中的唯一标识(其实
就是消息的索引号)。各个 consumer 会保存其消费到的 offset 位置,这样下次可以从
该 offset 位置开始继续消费;consumer 的消费 offset 会保存在一个专门的 topic
(__consumer_offsets)中;(0.10.x 版本一起是保存在 zk 中)