微服务架构之分布式请求链路跟踪1

需积分: 0 125 浏览量
更新于2022-08-03
收藏 2.93MB PDF 举报
【Spring Cloud Sleuth 分布式请求链路跟踪详解】
在微服务架构中,Spring Cloud Sleuth 是一个关键组件,用于实现服务间调用的跟踪,它可以帮助开发者清晰地理解请求在分布式系统中的完整流程,从而有效地定位和解决性能问题。在系统日益复杂,服务之间相互调用频繁的情况下,请求链路跟踪变得至关重要。
**Sleuth 的基本概念与作用**
1. **请求链路跟踪**:在分布式系统中,一个简单的用户请求可能触发一系列服务间的调用。Sleuth 可以记录并追踪这些调用,形成一个完整的请求链路,帮助开发者理解请求的流转过程和耗时分布。
2. **抽样收集**:为了降低性能影响,Sleuth 提供了抽样功能。在配置中,`sampler.probability` 参数可以设置抽样概率,例如 `0.1` 表示只有 10% 的请求会被跟踪。
3. **Zipkin 集成**:Sleuth 默认集成了 Zipkin,一个强大的跟踪收集和分析工具。Zipkin 收集各个服务的跟踪数据,并提供 REST API 和友好的 UI,便于开发者查看和分析请求链路。
**启用 Sleuth 请求链路跟踪**
要在服务中启用 Sleuth,首先需要在 Maven 或 Gradle 的构建文件中引入 `spring-cloud-starter-zipkin` 依赖。然后,在 `application.yml` 文件中配置 Zipkin 服务器的访问地址。
```yaml
spring:
zipkin:
base-url: http://localhost:9411
```
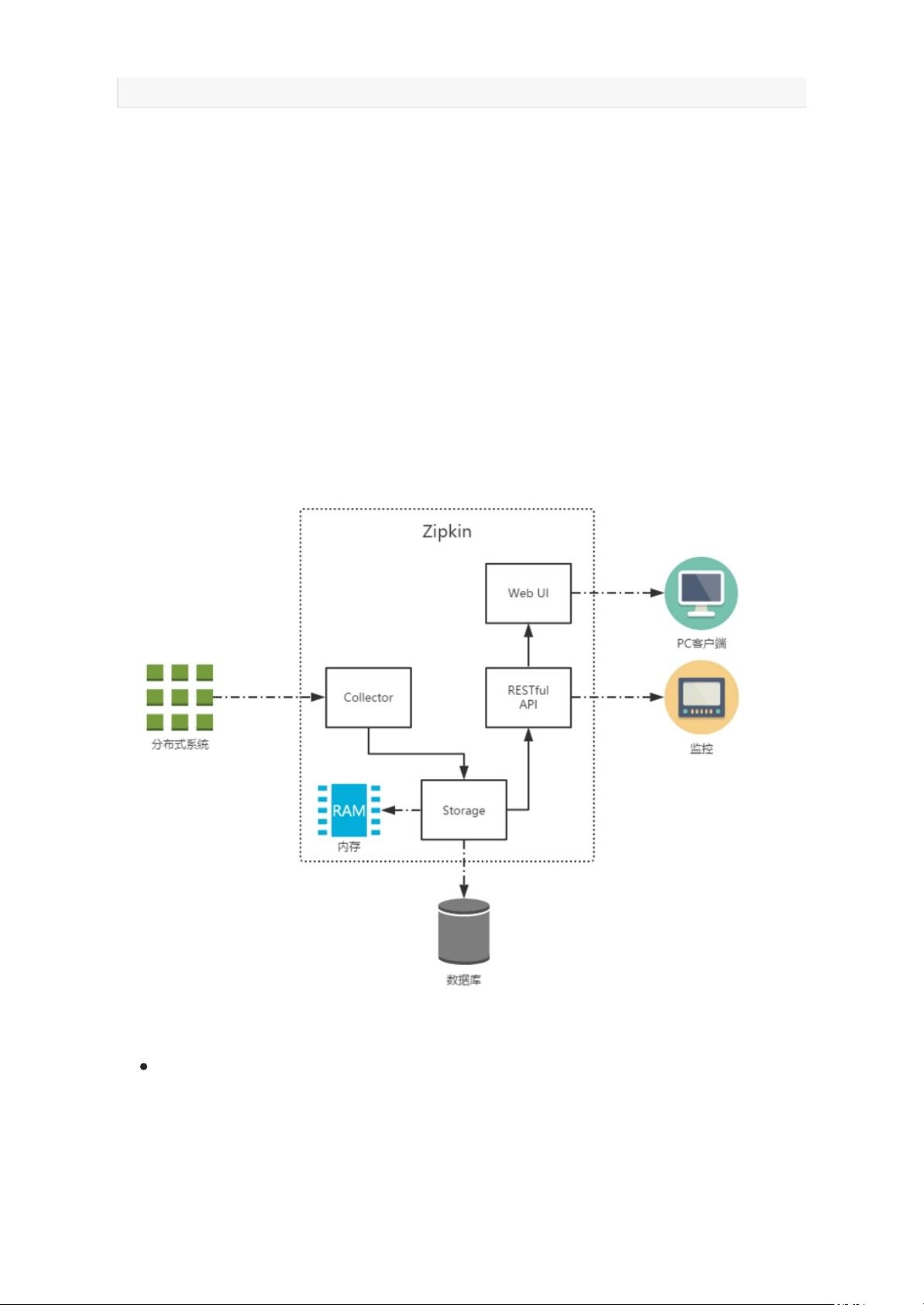
**Zipkin 的工作原理与组件**
1. **Collector**:收集器接收来自服务的跟踪数据,将其转化为 Zipkin 内部的 Span 格式,以便后续处理。
2. **Storage**:存储组件负责保存跟踪数据。默认情况下,数据存储在内存中,但可以通过配置使用 Elasticsearch 或其他持久化存储。
3. **RESTful API**:提供对外接口,允许客户端查询跟踪数据或与其他监控系统集成。
4. **Web UI**:提供直观的界面,用于搜索、分析和展示跟踪信息。
**使用 Zipkin 进行跟踪数据收集**
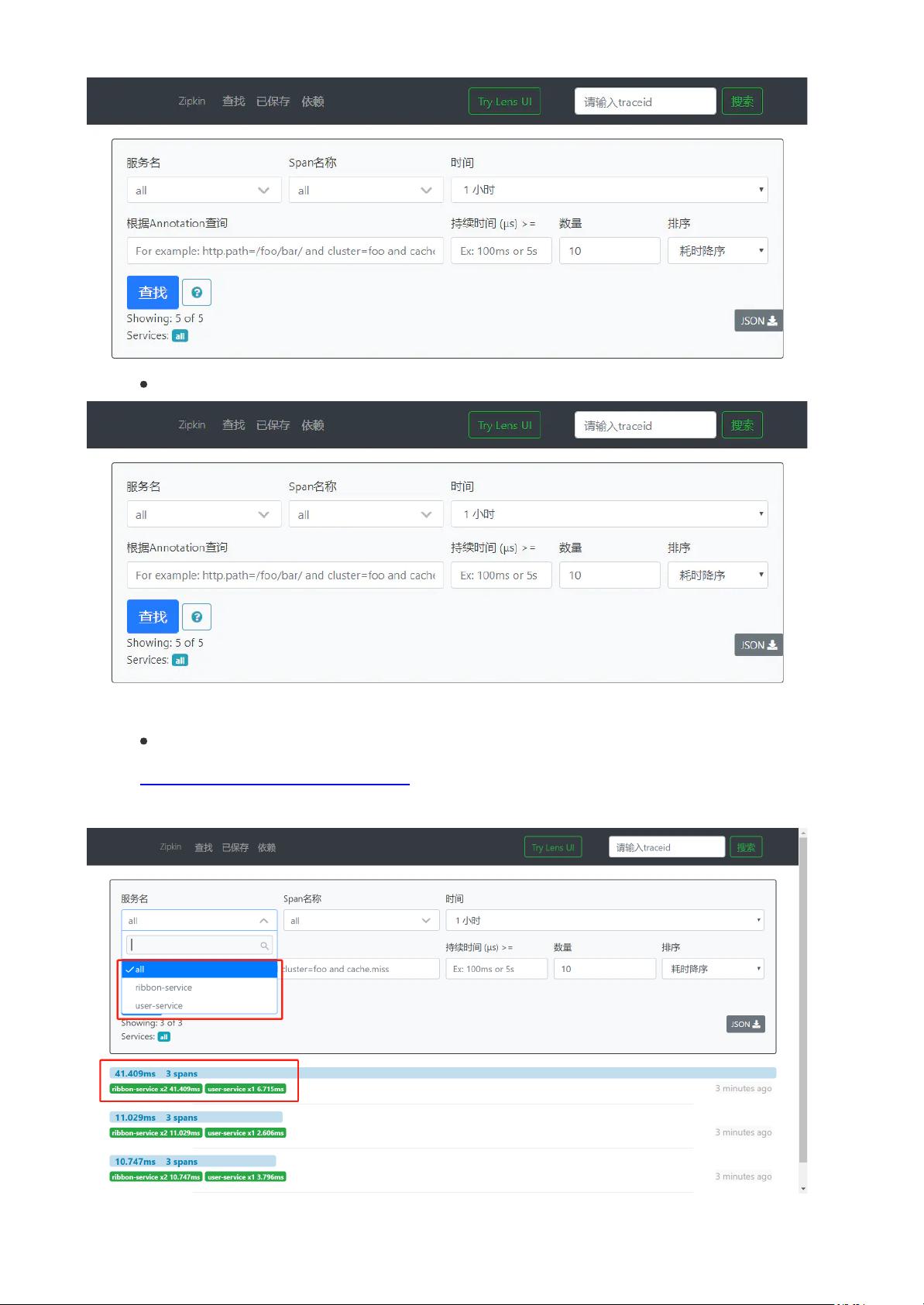
要启动 Zipkin 服务器,可以下载并运行 `zipkin-server-exec.jar` 文件。访问 `http://localhost:9411` 即可查看 Zipkin 的 Web 界面。在服务中调用接口后,跟踪信息会自动推送到 Zipkin。
**持久化跟踪信息**
如果需要将跟踪数据持久化,可以使用 Elasticsearch 作为存储后端。首先安装 Elasticsearch,然后在 Zipkin 配置中指定 Elasticsearch 地址,如:
```yaml
spring:
zipkin:
storage:
type: elasticsearch
elasticsearch:
hosts: [http://localhost:9200]
```
这样,即使重启 Zipkin 服务器,之前收集的跟踪数据也不会丢失。
**总结**
Spring Cloud Sleuth 结合 Zipkin 提供了一个强大且易于使用的分布式请求链路跟踪解决方案。通过它,开发者可以有效地监控微服务架构中的服务交互,定位性能瓶颈,优化系统性能,提升用户体验。在实际的微服务开发和运维中,理解和运用这一技术对于问题排查和系统优化具有重要意义。

SpringCloudSleuth:分布式请求链路跟踪
摘要
SpringCloudSleuth是分布式系统中跟踪服务间调用的工具,它可以直观地展示出
一次请求的调用过程,下面将对其用法进行详细介绍。
SpringCloudSleuth简介
随着我们的系统越来越庞大,各个服务间的调用关系也变得越来越复杂。当客户端发起一个
请求时,这个请求经过多个服务后,最终返回了结果,经过的每一个服务都有可能发生延迟
或错误,从而导致请求失败。这时候我们就需要请求链路跟踪工具来帮助我们,理清请求调
用的服务链路,解决问题。
给服务添加请求链路跟踪
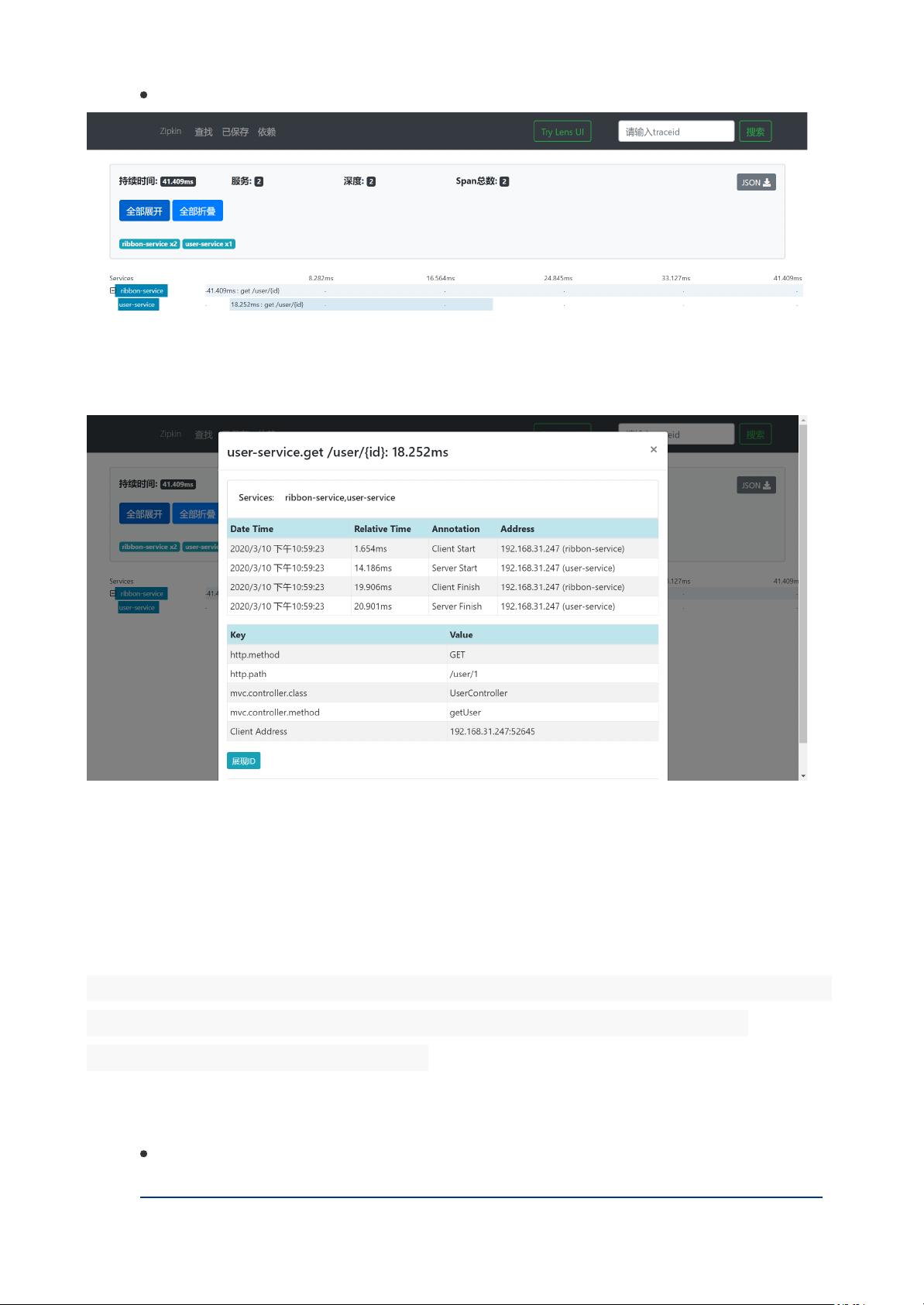
我们将通过user-service和ribbon-service之间的服务调用来演示该功能,这里我们
调用ribbon-service的接口时,ribbon-service会通过RestTemplate来调用user-
service提供的接口。
首先给user-service和ribbon-service添加请求链路跟踪功能的支持;
在user-service和ribbon-service中添加相关依赖:
1 <!‐‐使用分布式请求链路追踪时添加‐‐>
2 <dependency>
3 <groupId>org.springframework.cloud</groupId>
4 <artifactId>spring‐cloud‐starter‐zipkin</artifactId>
5 </dependency>
修改application.yml文件,配置收集日志的zipkin-server访问地址:
1 spring:
2 zipkin:
3 base‐url:http://localhost:9411
4 sleuth:
5 sampler:

剩余32页未读,继续阅读
136 浏览量
196 浏览量
164 浏览量
2018-11-06 上传
143 浏览量
2024-09-22 上传
199 浏览量
2019-02-22 上传
2024-09-02 上传
2020-08-19 上传
2020-08-26 上传
2022-08-03 上传
2020-08-27 上传
2020-08-27 上传
2024-03-27 上传
120 浏览量
141 浏览量
111 浏览量
资源评论


章满莫
- 粉丝: 35
- 资源: 316









最新资源
- 《能源转型投资展望:2025年及长远规划》.pdf
- PPTAAD DADAA
- SM2258XT-BGA144-4BGA180-6L-R1019 三星KLUCG4J1CB B0B1颗粒开盘工具 , EC, 3A, 94, 43, A4, CA 七彩虹SL300这个固件有用
- 基于Java开发的日程管理FlexTime应用设计源码
- 基于JavaScript、CSS、HTML的简易DOM版飞机游戏设计源码
- 【C++初级程序设计·配套源码】第1期-语法基础
- 基于华为消费者业务官网的仿制前端首页设计源码
- 影驰战将PS3111 东芝芯片TT18G23AIN开卡成功分享,图片里面画线的选项很重要
- 基于Java和Vue的kopsoftKANBAN车间电子看板设计源码
- 基于Go语言的SharpWxDump微信取证信息分析设计源码
- 基于C语言的USB光盘资料操作教学源码
- 基于GitHub的TypeScript文档中文翻译设计源码
- 【C++初级程序设计·配套源码】第2期-基本数据类型
- 基于Vue和SpringBoot的企业员工管理系统2.0版本设计源码
- 没用333333333333333333333333333333
- C++ STL 高级教程深入浅出版.zip
