Caffe数据转换1

需积分: 0 20 浏览量
更新于2022-08-08
收藏 802KB DOCX 举报
【Caffe数据转换1】是关于使用Caffe框架处理MNIST数据集的介绍,主要涉及两种数据存储格式:LMDB和LevelDB。这两者都是键/值对数据库,用于存储和检索训练数据。
**LMDB(Lightning Memory-Mapped Database)**是一种内存映射的数据库,它的特点是速度快、内存占用相对较小,并且支持多个训练模型同时读取同一数据集。相比于LevelDB,LMDB在速度上有10%-15%的优势,这使得它成为Caffe默认的数据存储格式。LMDB的主要特性包括:
1. 内存映射技术,使得数据可以直接在内存中操作。
2. 高并发读取能力,允许多个进程同时读取数据集。
3. 数据的有序存储,基于用户定义的key比较函数。
4. 数据压缩功能,减少存储空间并提升IO效率。
**LevelDB**是一个持久化的键/值存储系统,它将大部分数据存储在磁盘上,而不是像Redis那样全内存存储。LevelDB的特点包括:
1. 数据按key排序存储,便于查找。
2. 简单的操作接口,支持写入、读取和删除记录,以及原子批量操作。
3. 数据快照功能,确保读操作一致性。
4. 支持数据压缩,提高存储效率和读写速度。
5. 性能方面,LevelDB的写操作通常比读操作快,顺序读写优于随机读写。
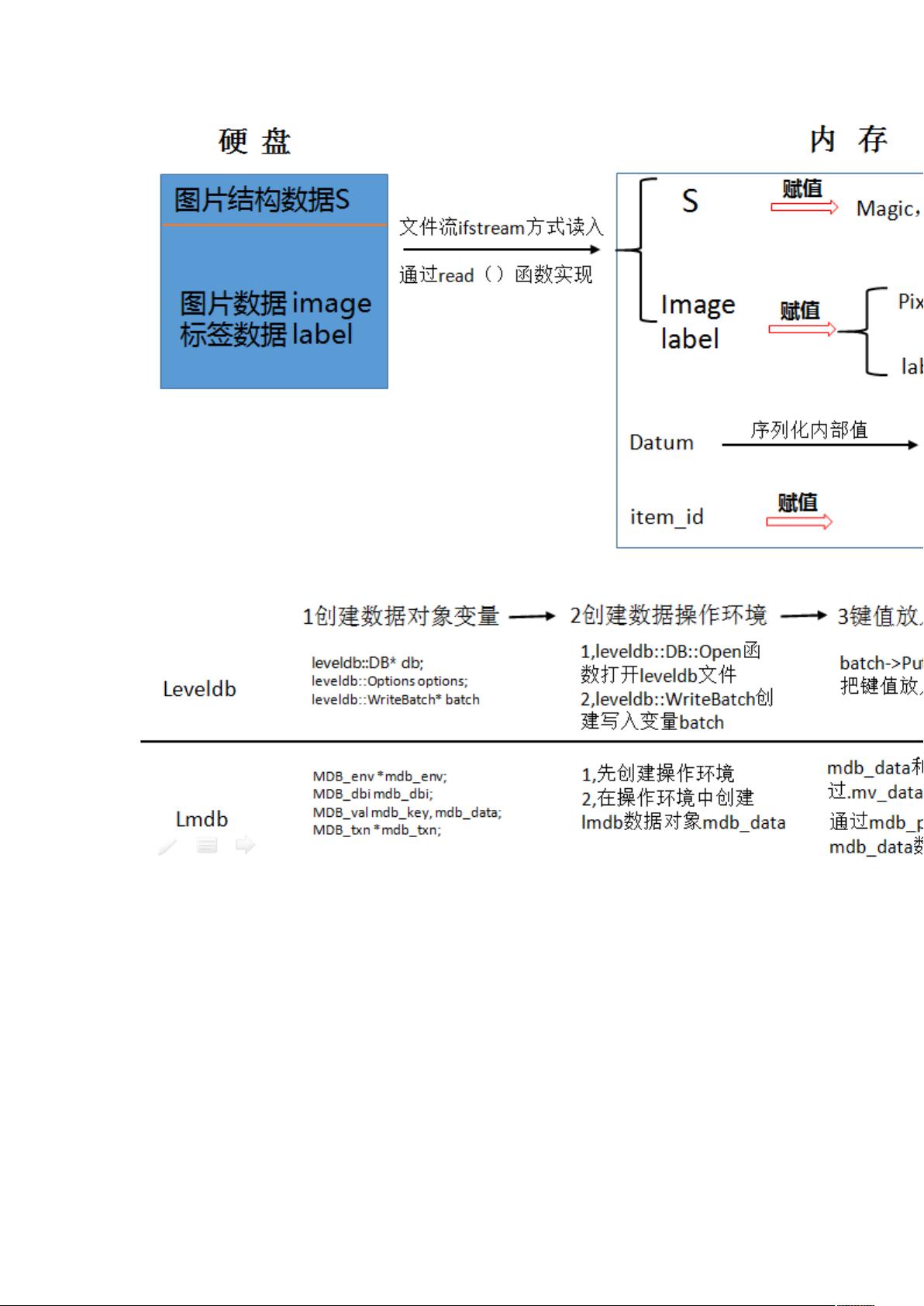
在Caffe中,数据转换过程通常通过`convert_mnist_data.cpp`程序完成。该程序负责将MNIST数据集从原始文件格式转换为LMDB或LevelDB格式。这个转换过程涉及到以下步骤:
1. 使用`convert_mnist_data.bin`执行文件,该文件由`convert_mnist_data.cpp`源代码编译生成。
2. `convert_mnist_data.bin`接受四个参数:训练数据位置、标签数据位置、转换后的LMDB或LevelDB数据存储位置,以及指定的数据库类型(LMDB或LevelDB)。
3. 转换流程涉及读取MNIST的训练和测试数据及对应的标签,然后将这些数据写入到指定类型的数据库中。
在`convert_mnist_data.cpp`中,使用了如gflags库来解析命令行参数,glog库进行日志记录,以及LevelDB和LMDB的头文件来操作数据库。程序会读取MNIST数据文件,然后通过`leveldb::DB`或`MDB_env`接口,将数据写入到数据库中,形成键/值对,键通常为图像的ID,值为图像数据和对应的标签。
Caffe数据转换是深度学习模型训练前的重要步骤,它将原始数据组织成高效访问的数据库格式,以便于模型的快速训练。对于大型数据集,如MNIST,使用LMDB或LevelDB可以显著提高数据加载速度,优化训练过程。

Caffe1——Mnist 数据集创建 lmdb 或 leveldb 类型的数据
2015-04-28 09:00 623 人阅读 评论(0) 收藏 举报
caffe 源码解析 lmdb 数据转换 leveldb 数据转换
目录(?)[+]
Leveldb 和 lmdb 简单介绍
Caffe 生成的数据分为 2 种格式:Lmdb 和 Leveldb。
它们都是键/值对(Key/Value Pair)嵌入式数据库管理系统编程库。
虽然 lmdb 的内存消耗是 leveldb 的 1.1 倍,但是 lmdb 的速度比 leveldb 快 10%至
15%,更重要的是 lmdb 允许多种训练模型同时读取同一组数据集。
因此 lmdb 取代了 leveldb 成为 Caffe 默认的数据集生成格式
(http://blog.csdn.net/ycheng_sjtu/article/details/40361947)
LevelDb 有如下一些特点:
首先,LevelDb 是一个持久化存储的 KV 系统,和 Redis 这种内存型的 KV 系统不
同,LevelDb 不会像 Redis 一样狂吃内存,而是将大部分数据存储到磁盘上。
其次,LevleDb 在存储数据时,是根据记录的 key 值有序存储的,就是说相邻的
key 值在存储文件中是依次顺序存储的,而应用可以自定义 key 大小比较函数,LevleDb
会按照用户定义的比较函数依序存储这些记录。
再次,像大多数 KV 系统一样,LevelDb 的操作接口很简单,基本操作包括写记
录,读记录以及删除记录。也支持针对多条操作的原子批量操作。
另外,LevelDb 支持数据快照(snapshot)功能,使得读取操作不受写操作影响,
可以在读操作过程中始终看到一致的数据。


剩余49页未读,继续阅读
139 浏览量
113 浏览量
2018-04-01 上传
189 浏览量
144 浏览量
2018-07-26 上传
155 浏览量
124 浏览量
2021-03-18 上传
2021-05-26 上传
121 浏览量
2021-05-18 上传
178 浏览量
2014-12-01 上传
159 浏览量
200 浏览量
2017-05-02 上传
2021-05-30 上传
2021-06-15 上传
179 浏览量
146 浏览量
177 浏览量
2018-04-21 上传
资源评论


地图帝
- 粉丝: 25
- 资源: 297









最新资源
- 工具变量-企业可持续发展能力数据集(1990-2023年).txt
- 基于接头形状分析的电子束焊接头性能研究 - .pdf
- 基于可编程序控制器闪光焊接过程的控制.pdf
- 基于轮廓法测试焊接件内部残余应力.pdf
- 基于铝合金焊接结构的振动时效工艺研究.pdf
- S7-200Smart 恒压供水程序样例+485通讯样例 + 触 摸屏样例子 1.此程序样例为一拖二恒压供水样例,采用S7-200Smart PLC和smart 700触摸屏人机与abb变频器48
- 基于ssm的电动车实名制挂牌管理系统源码(java毕业设计完整源码+LW).zip
- 一种电芯剪角机sw18可编辑全套技术资料100%好用.zip
- 基于ssm的电气与信息类书籍网上书店源码(java毕业设计完整源码+LW).zip
- 永磁同步电机无感foc位置估算源码 无刷直流电机无感foc源码,无感foc算法源码 1 速度估算位置估算的代码所使用变量全部用实际值单位,能非常直观的了解无感控制电机模型,使用简短的代码实现完整的无
- 基于Python控制台空气质量分析.py
- 基于ssm的东风锻造有限公司重大停管理系统源码(java毕业设计完整源码+LW).zip
- 金属板缺陷的二维及三维电磁无损检测与轮廓重构方法研究- 电磁无损检测中缺陷轮廓重构方法及其实现-基于探头信号的数据处理与分析
- Matlab Simulink双馈风机接入的三机九节点模型,所有参数已调好且可调,可直接运行
- 不同颜色球体和球架检测42-YOLO(v5至v11)、COCO、CreateML、Paligemma、VOC数据集合集.rar
- 基于ssm的动漫爱好者交流平台源码(java毕业设计完整源码).zip
