

基金分类——基于文本数据挖掘
1.引言
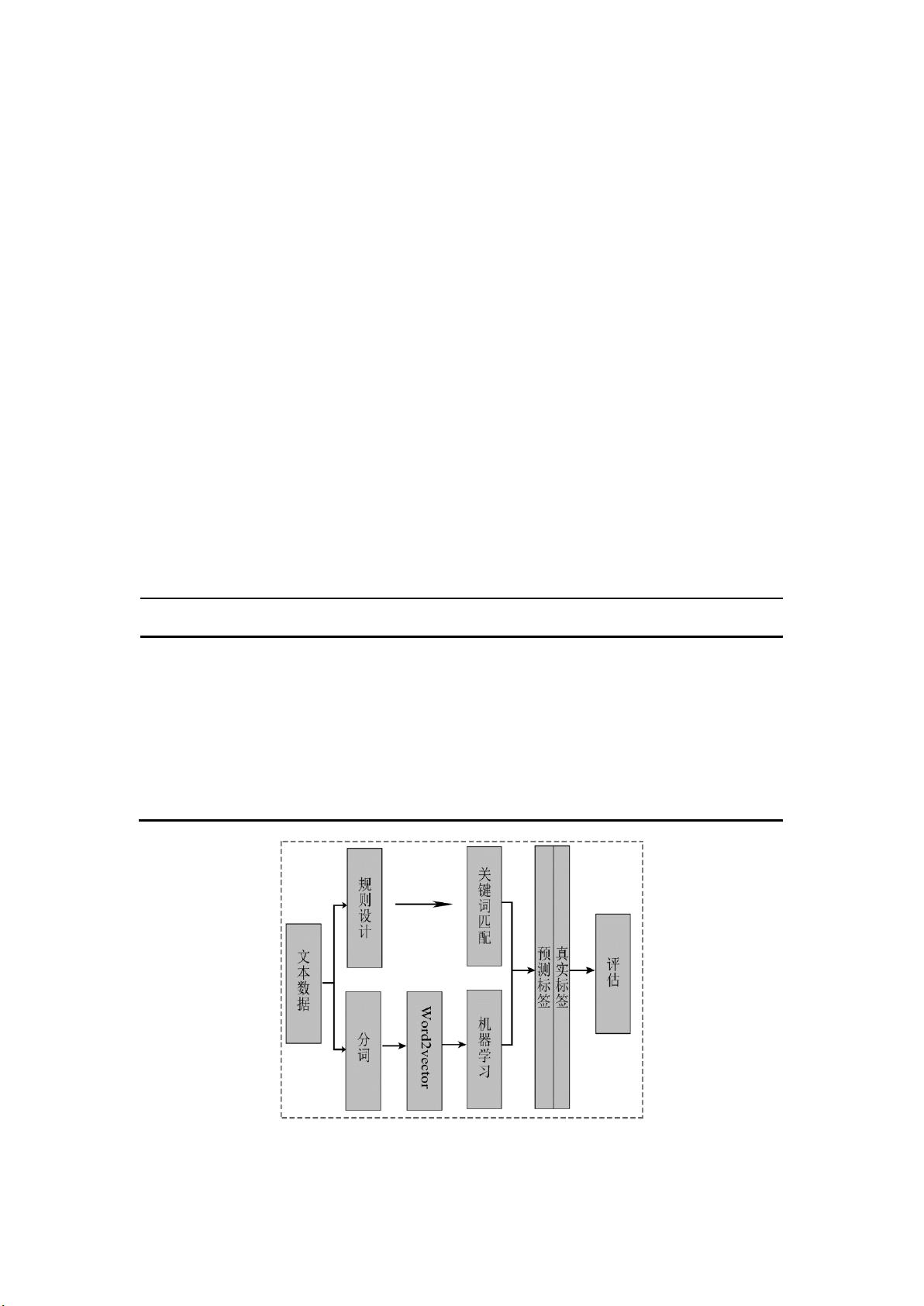
本文旨在提供一种文本数据挖掘方法以实现基金自动化分类。分类任务共 4 个,包括
投资方式维度一级、二级分类和投资标的维度一级、二级分类,详见表 1。
表 1 基金分类体系
分类维度
一级分类
二级分类
投资方式
主动型
主动型
指数型
被动指数型
指数增强型
投资标的
QDII 型
QDII 股票型
QDII 债券型
QDII 混合型
QDII 另类型
股票型
股票型
债券型
纯债型
混合债券型
理财债券型
货币型
货币型
混合型
FOF
量化对冲型
偏债混合型
偏股混合型
平衡混合型
灵活混合型
其他混合型
其他型
商品型
REITS
2.数据
2.1 数据描述
本文选取了 12672 个基金包括'fund_name', 'investment_target', 'investment_scope',
'investment_strategy', 'risk_return_character', 'comparison_criterion','tracking_benchmar
k'共 7 个特征的文本表述。相应的基金类型由人工标注,称为标签(type_name_x,stype_n
ame_x,type_nmae_y,stype_nmae_y)。
剩余9页未读,继续阅读













评论0