第八章_目标检测1
需积分: 0 57 浏览量
2022-08-03
18:45:34
上传
评论
收藏 11.82MB PDF 举报


第
八
章
目
标
检
测
8.1 基本概念
8.1.1 什么是目标检测?
8.1.2 目标检测要解决的核心问题?
8.1.3 目标检测算法分类?
8.1.4 目标检测有哪些应用?
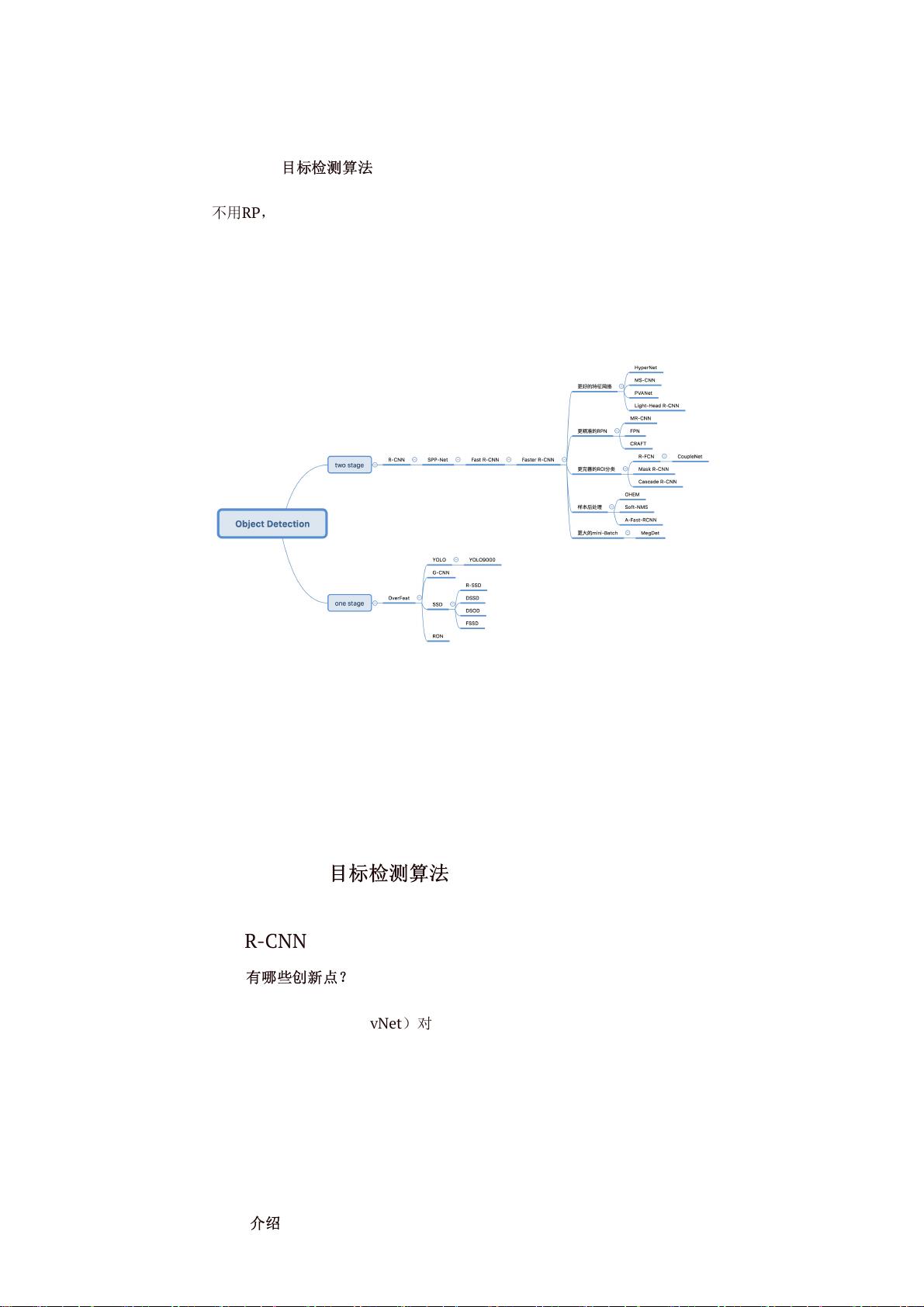
8.2 Two Stage目标检测算法
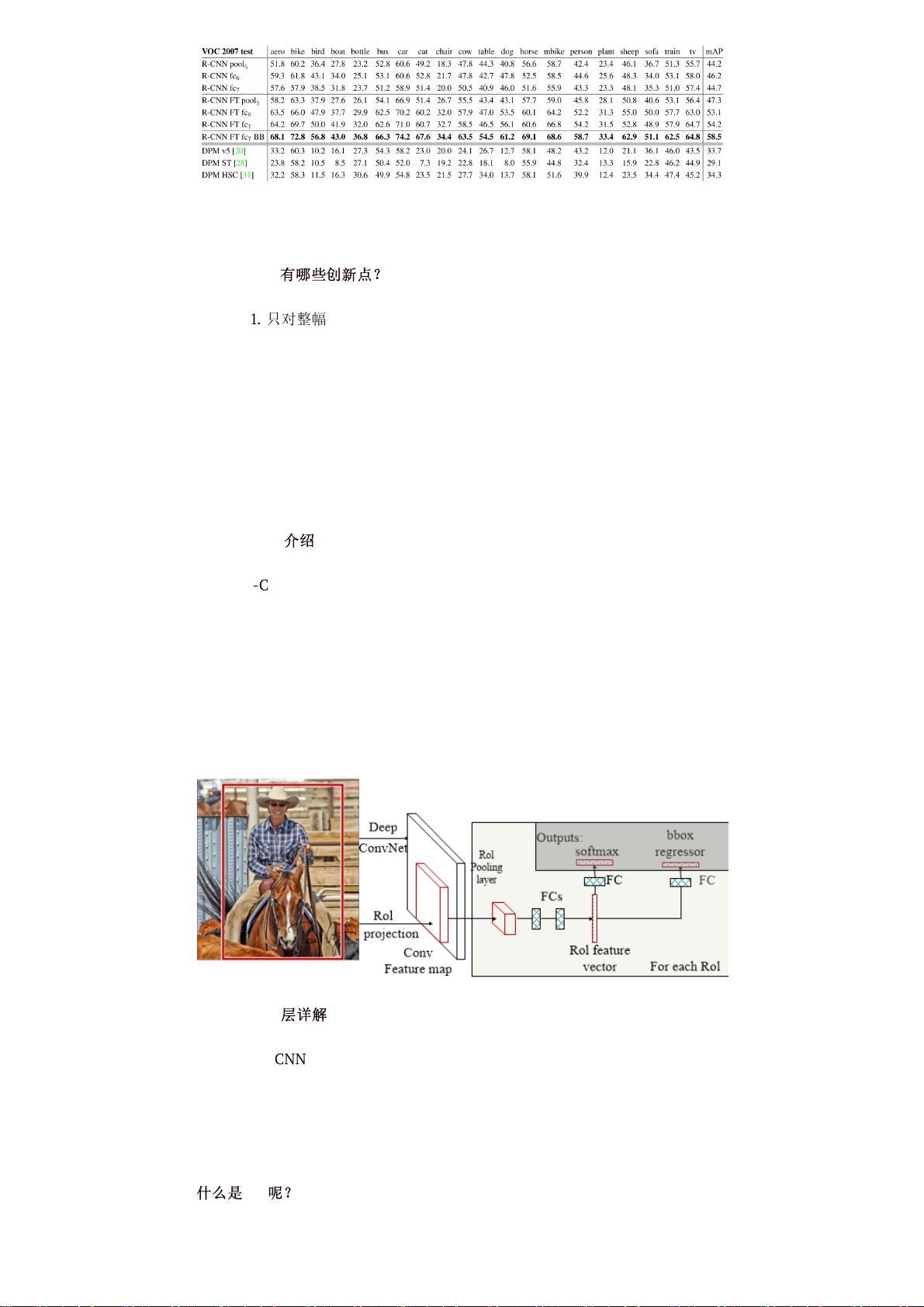
8.2.1 R-CNN
8.2.2 Fast R-CNN
8.2.3 Faster R-CNN
8.2.4 R-FCN
8.2.5 FPN
8.2.6 Mask R-CNN
8.3 One Stage目标检测算法
8.3.1 SSD
8.3.2 DSSD
8.3.3 YOLOv1
8.3.4 YOLOv2
8.3.5 YOLO9000
8.3.6 YOLOv3
8.3.7 RetinaNet
8.3.8 RFBNet
8.3.9 M2Det
8.4 人脸检测
8.4.1 目前主要有人脸检测方法分类?
8.4.2 如何检测图片中不同大小的人脸?
8.4.3 如何设定算法检测最小人脸尺寸?
8.4.4 如何定位人脸的位置?
8.4.5 如何通过一个人脸的多个框确定最终人脸框位置?
8.4.6 基于级联卷积神经网络的人脸检测(Cascade CNN)
8.4.7 基于多任务卷积神经网络的人脸检测(MTCNN)
8.4.8 Facebox
8.5 目标检测的技巧汇总
8.6 目标检测的常用数据集
8.6.1 PASCAL VOC
8.6.2 MS COCO
8.6.3 Google Open Image
8.6.4 ImageNet
8.7 目标检测常用标注工具
8.7.1 LabelImg
8.7.2 labelme
8.7.3 Labelbox
8.7.4 RectLabel
8.7.5 CVAT
8.7.6 VIA
8.7.6 其他标注工具
TODO
参考文献
第八章 目标检测


剩余53页未读,继续阅读













评论0