

Fast R-CNN
Ross Girshick
Microsoft Research
rbg@microsoft.com
Abstract
This paper proposes a Fast Region-based Convolutional
Network method (Fast R-CNN) for object detection. Fast
R-CNN builds on previous work to efficiently classify ob-
ject proposals using deep convolutional networks. Com-
pared to previous work, Fast R-CNN employs several in-
novations to improve training and testing speed while also
increasing detection accuracy. Fast R-CNN trains the very
deep VGG16 network 9⇥ faster than R-CNN, is 213⇥ faster
at test-time, and achieves a higher mAP on PASCAL VOC
2012. Compared to SPPnet, Fast R-CNN trains VGG16 3⇥
faster, tests 10⇥ faster, and is more accurate. Fast R-CNN
is implemented in Python and C++ (using Caffe) and is
available under the open-source MIT License at https:
//github.com/rbgirshick/fast-rcnn.
1. Introduction
Recently, deep ConvNets [14, 16] have significantly im-
proved image classification [14] and object detection [9, 19]
accuracy. Compared to image classification, object detec-
tion is a more challenging task that requires more com-
plex methods to solve. Due to this complexity, current ap-
proaches ( e.g., [9, 11, 19, 25]) train models in multi-stage
pipelines that are slow and inelegant.
Complexity arises because detection requires the ac-
curate localization of objects, creating two primary chal-
lenges. First, numerous candidate object locations (often
called “proposals”) must be processed. Second, these can-
didates provide only rough localization that must be refined
to achieve precise localization. Solutions to these problems
often compromise speed, accuracy, or simplicity.
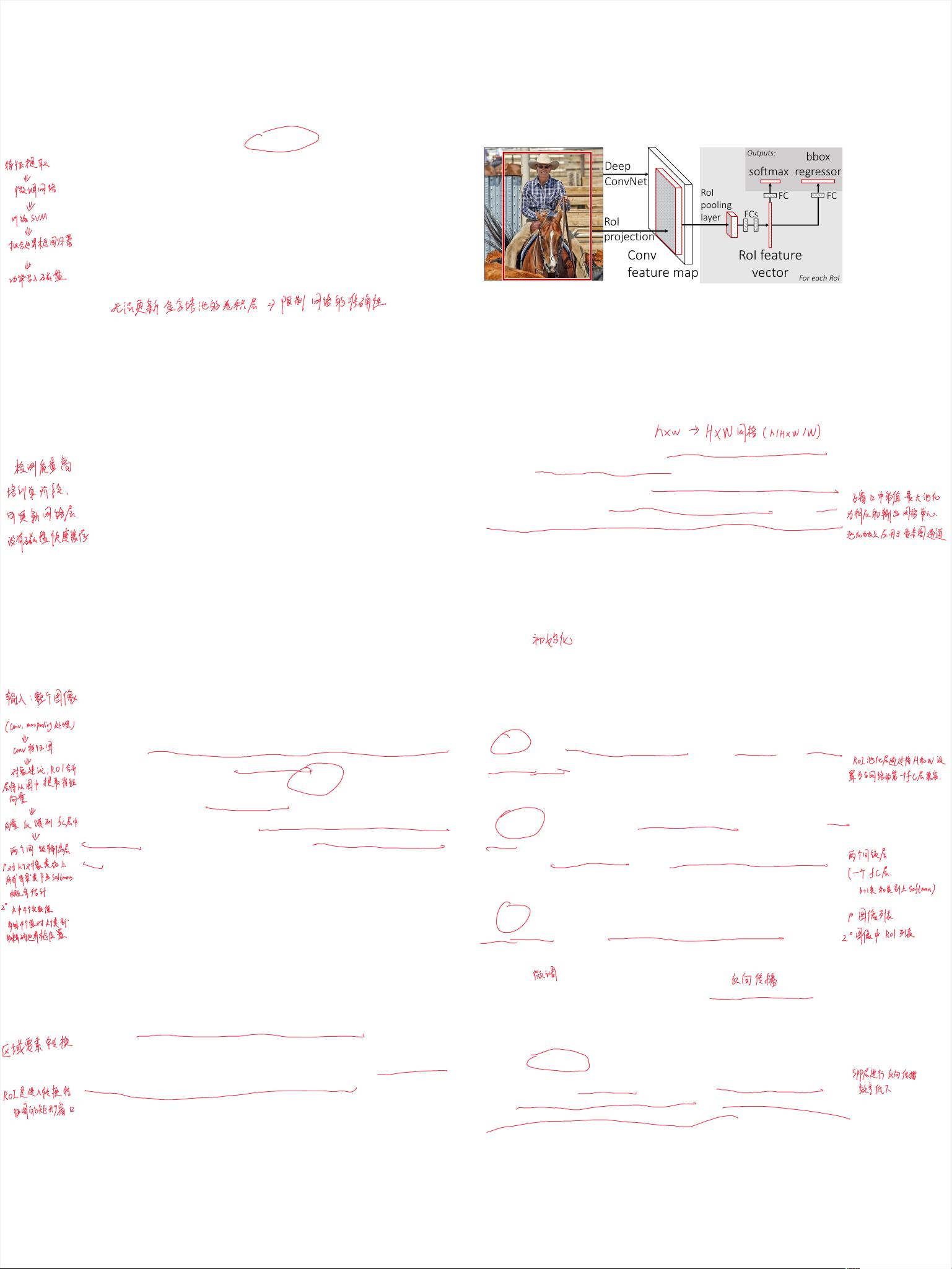
In this paper, we streamline the training process for state-
of-the-art ConvNet-based object detectors [9, 11]. We pro-
pose a single-stage training algorithm that jointly learns to
classify object proposals and refine their spatial locations.
The resulting method can train a very deep detection
network (VGG16 [20]) 9⇥ faster than R-CNN [9] and 3⇥
faster than SPPnet [11]. At runtime, the detection network
processes images in 0.3s (excluding object proposal time)
while achieving top accuracy on PASCAL VOC 2012 [7]
with a mAP of 66% (vs. 62% for R-CNN).
1
1.1. R-CNN and SPPnet
The Region-based Convolutional Network method (R-
CNN) [9] achieves excellent object detection accuracy by
using a deep ConvNet to classify object proposals. R-CNN,
however, has notable drawbacks:
1. Training is a multi-stage pipeline. R-CNN first fine-
tunes a ConvNet on object proposals using log loss.
Then, it fits SVMs to ConvNet features. These SVMs
act as object detectors, replacing the softmax classi-
fier learnt by fine-tuning. In the third training stage,
bounding-box regressors are learned.
2. Training is expensive in space and time. For SVM
and bounding-box regressor training, features are ex-
tracted from each object proposal in each image and
written to disk. With very deep networks, such as
VGG16, this process takes 2.5 GPU-days for the 5k
images of the VOC07 trainval set. These features re-
quire hundreds of gigabytes of storage.
3. Object detection is slow. At test-time, features are
extracted from each object proposal in each test image.
Detection with VGG16 takes 47s / image (on a GPU).
R-CNN is slow because it performs a ConvNet forward
pass for each object proposal, without sharing computation.
Spatial pyramid pooling networks (SPPnets) [11] were pro-
posed to speed up R-CNN by sharing computation. The
SPPnet method computes a convolutional feature map for
the entire input image and then classifies each object pro-
posal using a feature vector extracted from the shared fea-
ture map. Features are extracted for a proposal by max-
pooling the portion of the feature map inside the proposal
into a fixed-size output (e.g., 6 ⇥ 6). Multiple output sizes
are pooled and then concatenated as in spatial pyramid pool-
ing [15]. SPPnet accelerates R-CNN by 10 to 100⇥ at test
time. Training time is also reduced by 3⇥ due to faster pro-
posal feature extraction.
1
All timings use one Nvidia K40 GPU overclocked to 875 MHz.
arXiv:1504.08083v2 [cs.CV] 27 Sep 2015
剩余8页未读,继续阅读













评论0