

1 / 70
第6章:Hive性能优化及Hive3新特性
1. 课程学习目标
掌握Hive中分区表及分桶表的设计及优化实现
了解Hive中索引的设计及应用场景
掌握Hive中文件格式与数据压缩的优化
掌握Hive中的存储优化
掌握Explain解析命令的使用
掌握MapReduce的属性优化
掌握Join方案的优化
掌握CBO优化器与Analyze的的使用
了解谓词下推PPD的基本规则
掌握数据倾斜的问题处理方案
了解Hive与Tez的集成实现
了解Hive与Ranger的集成实现权限管理
了解Hive3中的LLAP、Metastore独立模式等新特性
2. Hive表设计优化
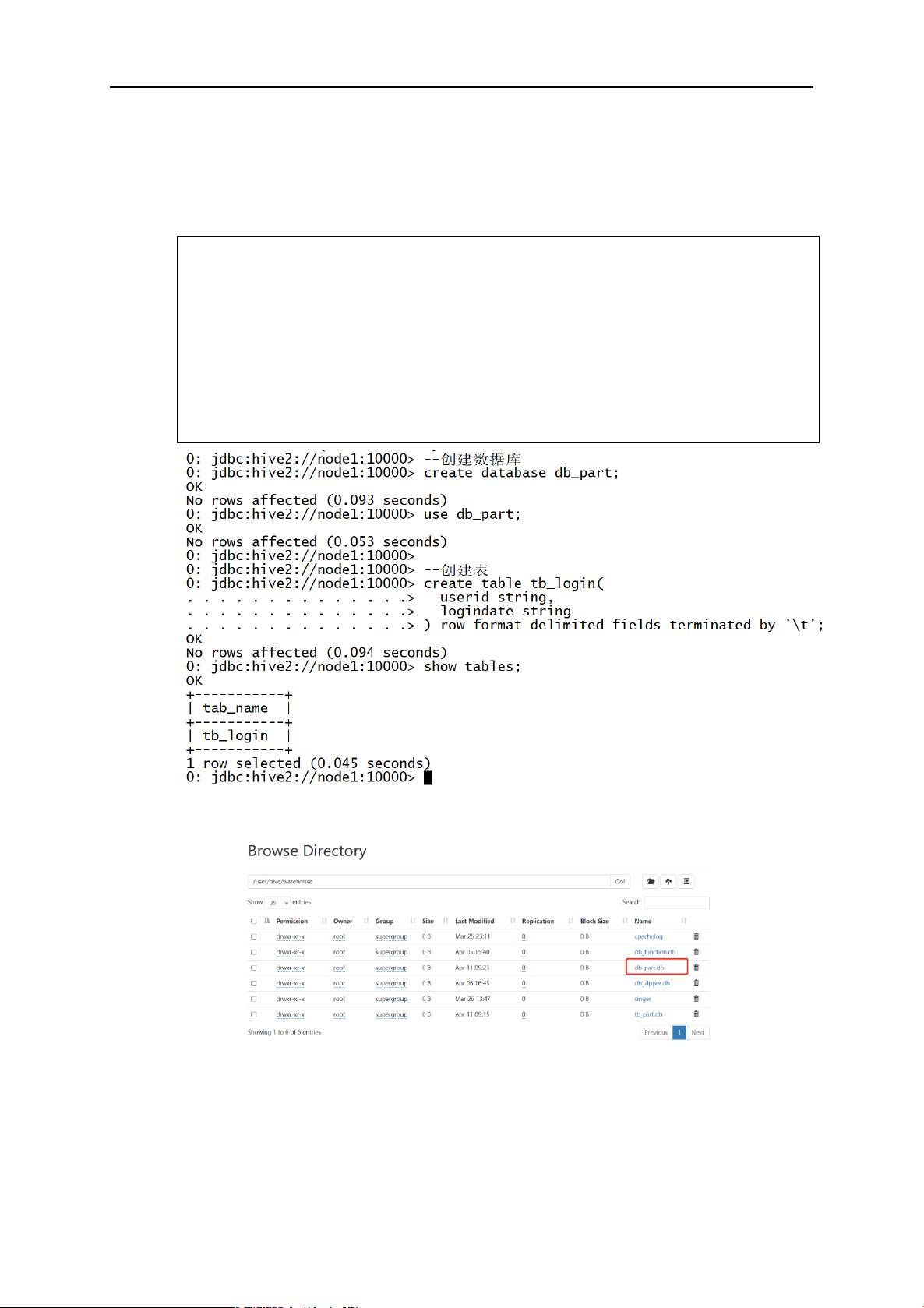
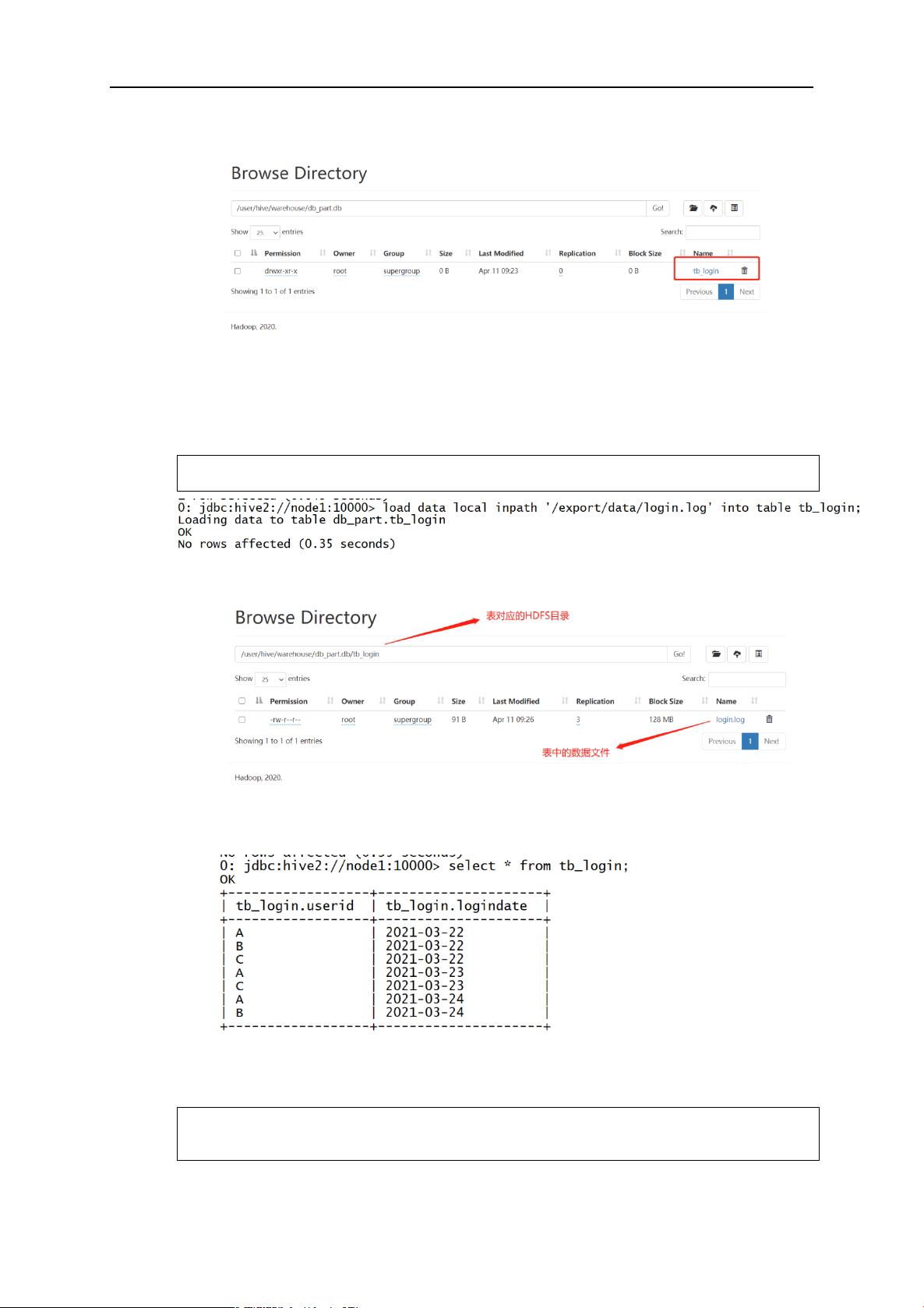
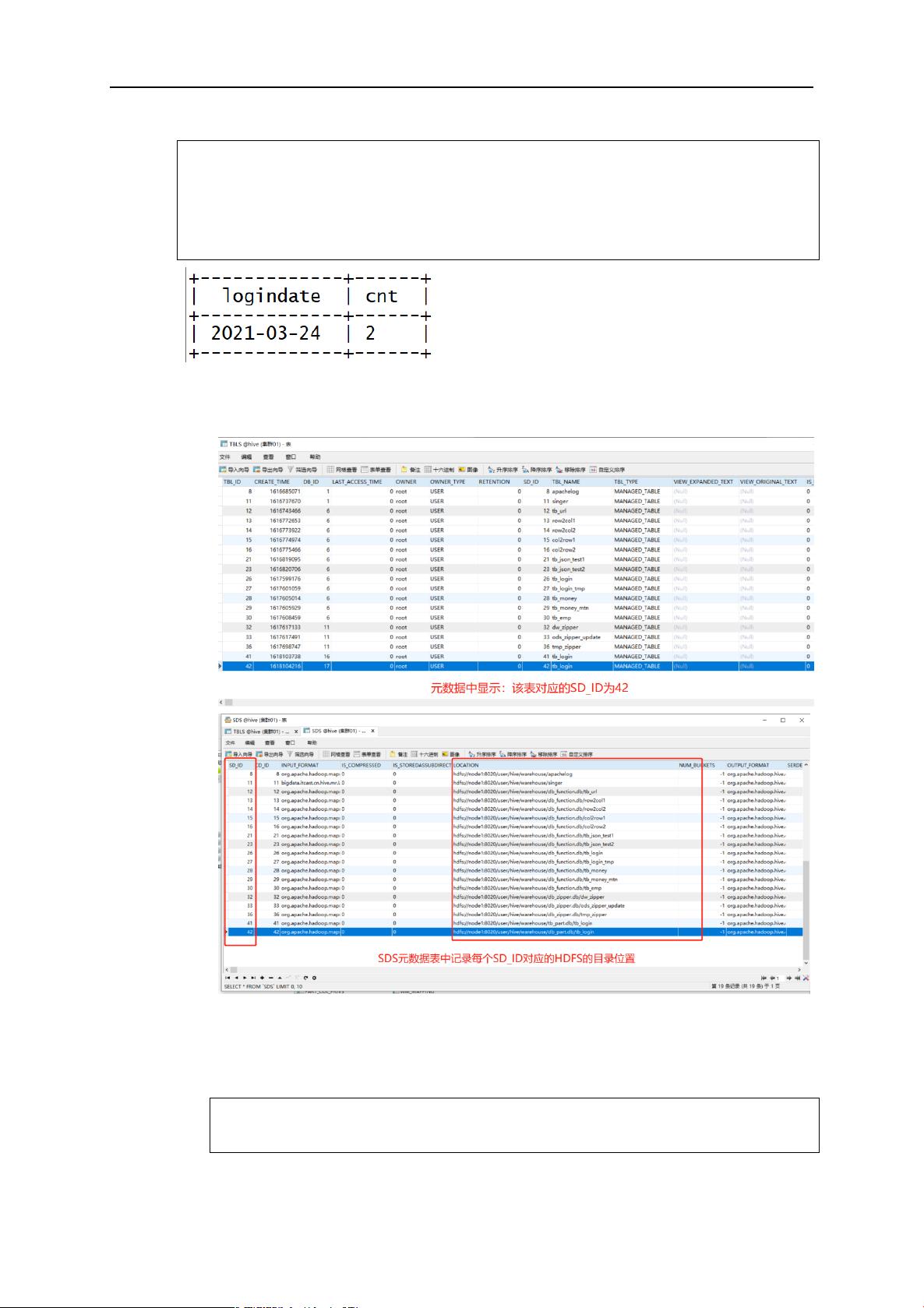
2.1 分区表
2.1.1 Hive查询基本原理
Hive的设计思想是通过元数据将HDFS上的文件映射成表,基本的查询原理是当用户通过HQL
语句对Hive中的表进行复杂数据处理和计算时,默认将其转换为分布式计算MapReduce程序对
HDFS中的数据进行读取处理的过程。

剩余69页未读,继续阅读






评论0
最新资源