7.2 优化算法 2019 年 4 月 10 日 167
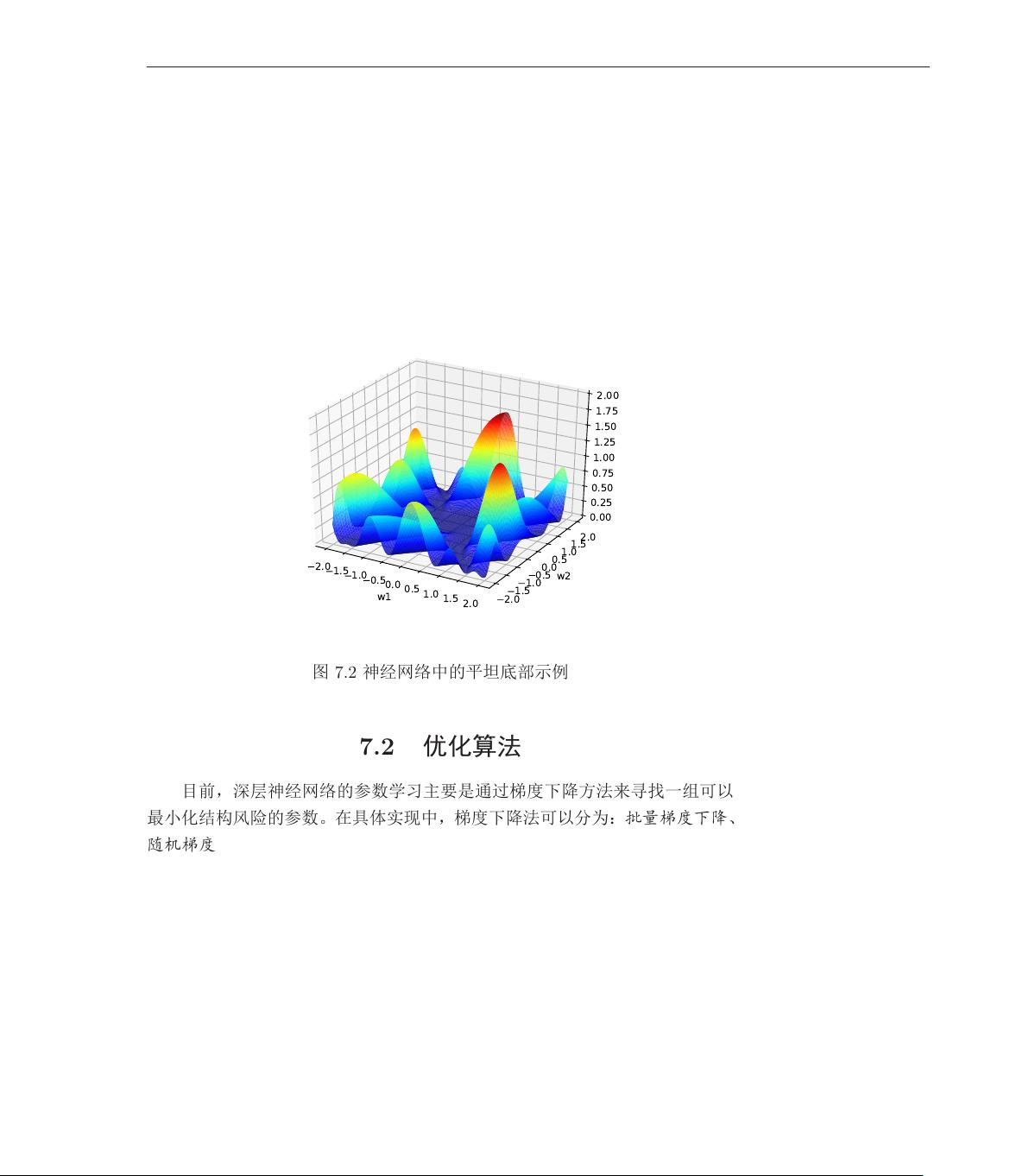
平坦底部 深层神经网络的参数非常多,并且有一定的冗余性,这导致每单个参
数对最终损失的影响都比较小,这导致了损失函数在局部最优点附近是一个平
坦的区域,称为平坦最小值(Flat Minima)[Hochreiter and Schmidhuber, 1997,
Li et al., 2017a]。并且在非常大的神经网络中,大部分的局部最小值是相等的。
虽然神经网络有一定概率收敛于比较差的局部最小值,但随着网络规模增加,网
络陷入局部最小值的概率大大降低 [Choromanska et al., 2015]。图7.2给出了一
种简单的平坦底部示例。
w1
2.0
1.5
1.0
0.5
0.0
0.5
1.0
1.5
2.0
w2
2.0
1.5
1.0
0.5
0.0
0.5
1.0
1.5
2.0
0.00
0.25
0.50
0.75
1.00
1.25
1.50
1.75
2.00
图 7.2 神经网络中的平坦底部示例
7.2 优化算法
目前,深层神经网络的参数学习主要是通过梯度下降方法来寻找一组可以
最小化结构风险的参数。在具体实现中,梯度下降法可以分为:批量梯度下降、
随机梯度下降以及小批量梯度下降三种形式。根据不同的数据量和参数量,可
以选择一种具体的实现形式。除了在收敛效果和效率上的差异,这三种方法都
存在一些共同的问题,比如 1)如何初始化参数;2)预处理数据;3)如何选择
合适的学习率,避免陷入局部最优等。
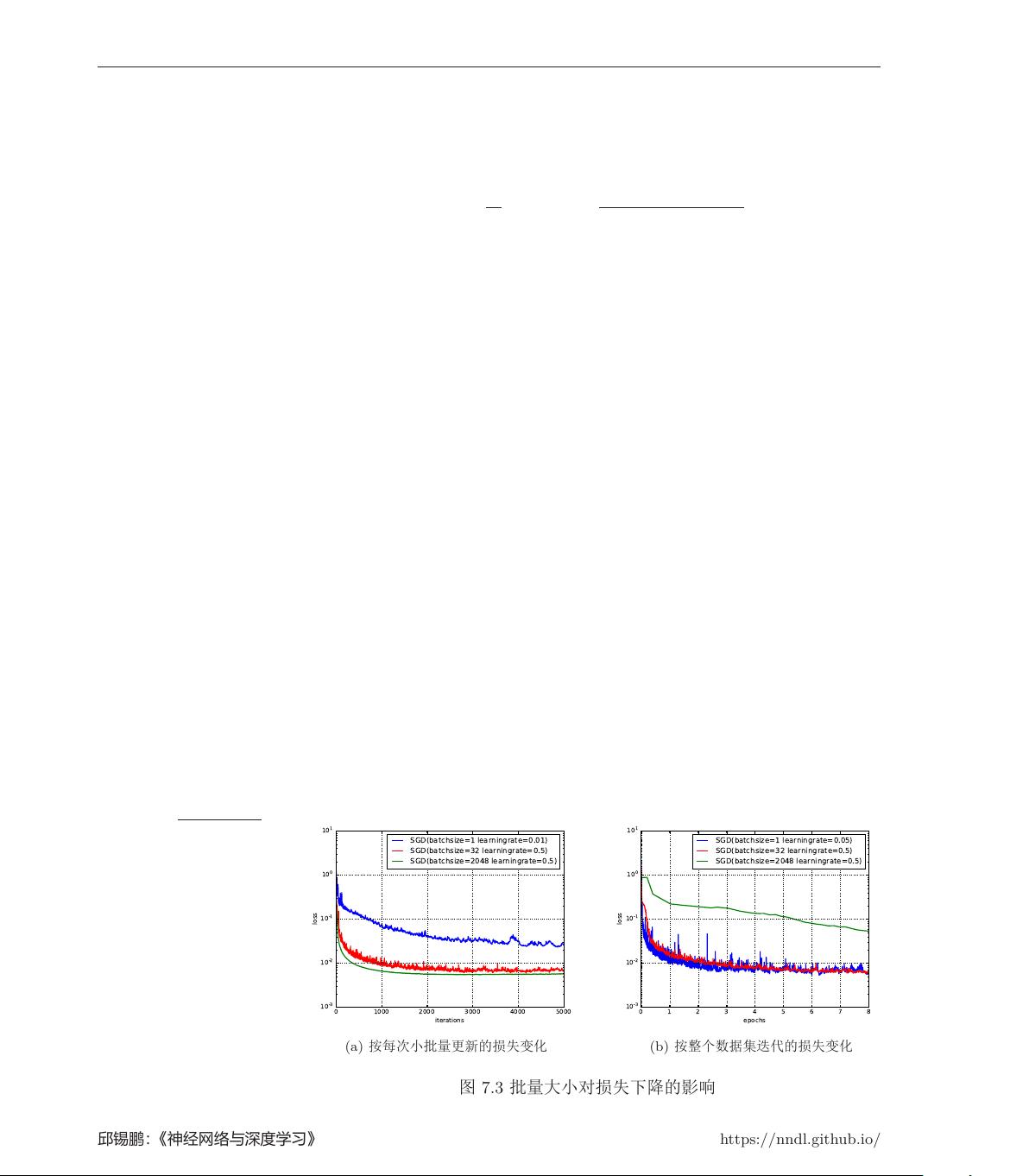
7.2.1 小批量梯度下降
目前,在训练深层神经网络时,训练数据的规模比较大。如果在梯度下降
时,每次迭代都要计算整个训练数据上的梯度需要比较多的计算资源。此外,大
规模训练集中的数据通常也会非常冗余,也没有必要在整个训练集上计算梯度。
因此,在训练深层神经网络时,经常使用小批量梯度下降算法。
邱锡鹏:《神经网络与深度学习》 https://nndl.github.io/
















评论0