22.自己动手做一个智能音箱1

需积分: 0 91 浏览量
更新于2022-08-08
收藏 433KB DOCX 举报
在这个教程中,我们将逐步了解如何制作一个自制的智能音箱,主要分为三个部分:整体架构、snowboy 和 speech_recognition 的安装以及完成主程序架构。这个项目的目标是创建一个功能类似于普通智能音箱的设备,利用开源和成熟的技术,同时保持组装和配置的灵活性。
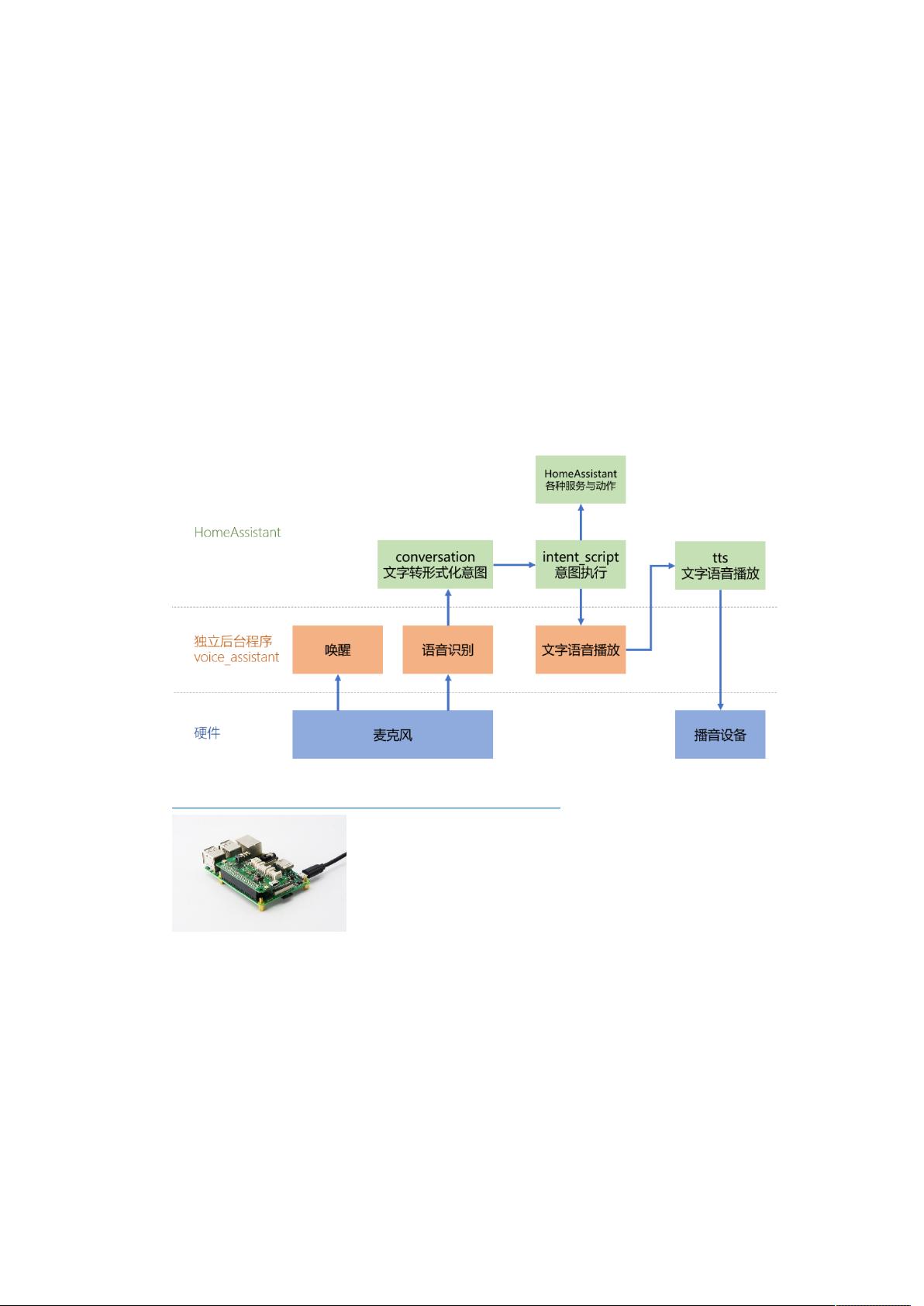
**整体架构**
智能音箱的核心组成部分包括拾音设备、播音设备、语音识别和响应系统。在本项目中,我们使用的是基于树莓派的 seeed 双麦克风扩展板,它提供了两个高质量的麦克风用于拾音。硬件安装过程中,需要安装驱动,可以通过运行提供的 `install.sh` 脚本来完成。此外,音箱还需要能够播放音频,可以使用 `arecord` 和 `aplay` 命令来测试录音和播放设备。
**硬件安装**
1. **项目目标**:打造一个拥有常见智能音箱功能的设备,如语音唤醒、语音识别等。
2. **拾音与播音设备**:使用 seeed 双麦克风树莓派扩展板,通过安装驱动确保其正常工作。
3. **设置音频输入输出**:使用 `arecord` 和 `aplay` 查看并选择合适的录音和播放设备。
**软件安装**
1. **基础库**:安装必要的 Python 库,如 `python-pyaudio`, `python3-pyaudio`, `flac`, `libpcre3`, `libpcre3-dev`, `libatlas-base-dev` 和 `swig`,为后续的语音处理做准备。
2. **snowboy**:这是一个语音唤醒服务,通过 `git clone` 下载源代码,进入 `swig/Python3` 目录编译并测试。
3. **SpeechRecognition**:用于语音识别的 Python 库,通过 `pip3 install SpeechRecognition` 安装,然后修改库文件以解决可能存在的问题。
- 测试语音识别:创建 `voice_assistant.py` 文件,使用 `speech_recognition` 库进行语音识别,识别结果可调用 Google 的中文语音识别服务。
**主程序架构**
1. **文件结构**:创建合理的文件结构,例如 `sb/resources` 目录用于存放资源文件。
2. **唤醒后识别**:实现当音箱被唤醒后开始进行语音识别。
3. **提示音**:添加唤醒后的提示音,增强用户体验。
4. **无限循环**:构建一个唤醒-识别的无限循环,使得音箱可以持续监听并响应用户的语音指令。
在实际操作中,可能会遇到某些 USB 麦克风不支持 16000Hz 采样率的问题,此时需要根据实际情况调整程序参数或寻找其他解决方案。项目参考了 `SnowBoy` 和 `SpeechRecognition` 项目,这两个项目分别提供了唤醒词服务和语音识别服务,它们都是开源且广泛使用的工具。
通过这个教程,我们可以学习到如何集成硬件和软件,构建一个基本的智能音箱原型。这只是一个起点,你还可以进一步定制化,比如增加更多功能,优化识别准确率,或者接入第三方服务,如智能家居控制系统,使其成为一个真正的智能家庭助手。
DIY 智能音箱(1)——整体架构、硬件安装
【操作步骤】
1. 项目目标
2. 整体架构讲解
3. 拾音与播音设备安装
4. 设置缺省音频输入与输出,并进行测试
【参考】
项目目标
具有一般智能音箱的功能
尽量使用成熟的开源的开放的项目
架构模块化,保持组装与配置的自由度
架构图
seeed 双麦克树莓派扩展板
http://wiki.seeedstudio.com/ReSpeaker_2_Mics_Pi_HAT/
驱动安装:
git clone https://github.com/respeaker/seeed-voicecard
cd seeed-voicecard
sudo ./install.sh
sudo reboot
播放与录音命令
arecord -l #列出所有录音设备
arecord -f cd -d 6 -Dhw:1,0 test.wav #以 cd 音质录制 6 秒钟音频,保存到 test.wav 文件,hw:1,0 为录音设备
aplay -l #列出所有播放设备
aplay test.wav #播放 test.wav
注:如果大家不使用本地麦克风,直接使用远程麦克风,可以参见后续的视频《音乐灯
带》与《远程麦克风》

剩余12页未读,继续阅读
2009-03-10 上传
157 浏览量
2013-03-14 上传
196 浏览量
2024-08-08 上传
2021-01-11 上传
2010-11-09 上传
168 浏览量
148 浏览量
2019-12-23 上传
108 浏览量
130 浏览量
102 浏览量
179 浏览量
149 浏览量
资源评论


glowlaw
- 粉丝: 27
- 资源: 274









