chap3-线性模型1
需积分: 0 45 浏览量
2022-08-03
12:12:45
上传
评论
收藏 770KB PDF 举报


第 3 章 线性模型
正确的判断来自于经验,而经验来自于错误的判断。
— Frederick P. Brooks
线性模型(Linear Model)是机器学习中应用最广泛的模型,指通过样本
特征的线性组合来进行预测的模型。给定一个
d
维样本
[
x
1
,
···
, x
d
]
T
,其线性组
合函数为
f(x, w) = w
1
x
1
+ w
2
x
2
+ ··· + w
d
x
d
+ b (3.1)
= w
T
x + b, (3.2)
简单起见,这里用 f(x, w) 来
表示 f (x, w, b)。
其中 w = [w
1
, ··· , w
d
]
T
为 d 维的权重向量,b 为偏置。上一章中介绍的线性回
归就是典型的线性模型,直接用 f(x, w) 来预测输出目标 y = f(x, w)。
在分类问题中,由于输出目标 y 是一些离散的标签,而 f(x, w) 的值域为
实数,因此无法直接用 f(x, w) 来进行预测,需要引入一个非线性的决策函数
(decision function)g(·) 来预测输出目标
y = g
f(x, w)
, (3.3)
其中 f(x, w) 也称为判别函数(discriminant function)。
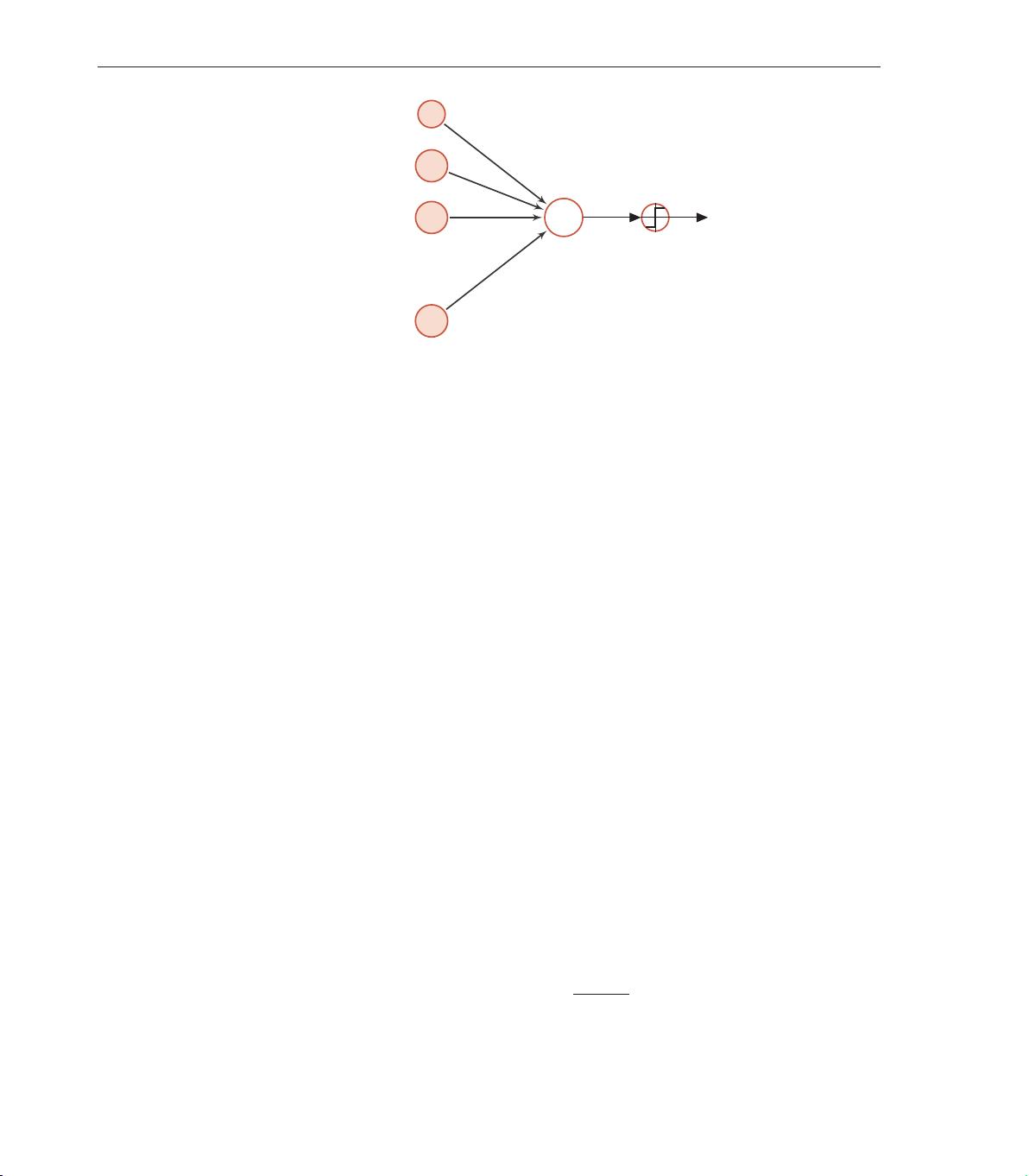
对于两类分类问题,g(·) 可以是符号函数(sign function)
g
f(x, w)
= sgn
f(x, w)
(3.4)
,
+1 if f(x, w) > 0,
−1 if f(x, w) < 0.
(3.5)
当 f(x, w) = 0 时不进行预测。公式 (3.5) 定义了一个典型的两类分类问题的决
策函数,其结构如图3.1所示。


剩余25页未读,继续阅读













评论0