

Lucene FST 算法流程
FST 简介
FST(Finite State Transducer,一种有限自动机,或者称为 Mealy
machine)是 lucene 中的一个核心算法,用于检索 term 信息存储的位
置。在 lucene 中,term 按照其字典顺序排序(term 在存储时称为
input), term 相关的信息按照 term 排序的次序存储在磁盘上(其存
储的位置为 outPut), <input,output>二元组将以 FST 的形式存储在内
存中(input 和 output 都是有序的)。检索时,根据 input,通过计算
FST 中的路径上的权值信息,获取到 output 数据,最终在磁盘上定位
term 的其它附加信息。同时 FST 还能够快速的判断一个 term 是否在
lucene 中。
实际上 FST 相当于 term 在内存中的一个索引,lucene 使用 FST 能够
快速确定系统中是否存在查询的 term,如果存在,能够快速定位其
信息存放的具体位置。
FST 与 trie tree 结构提供相似的功能,但是,在内存中存储更高效。
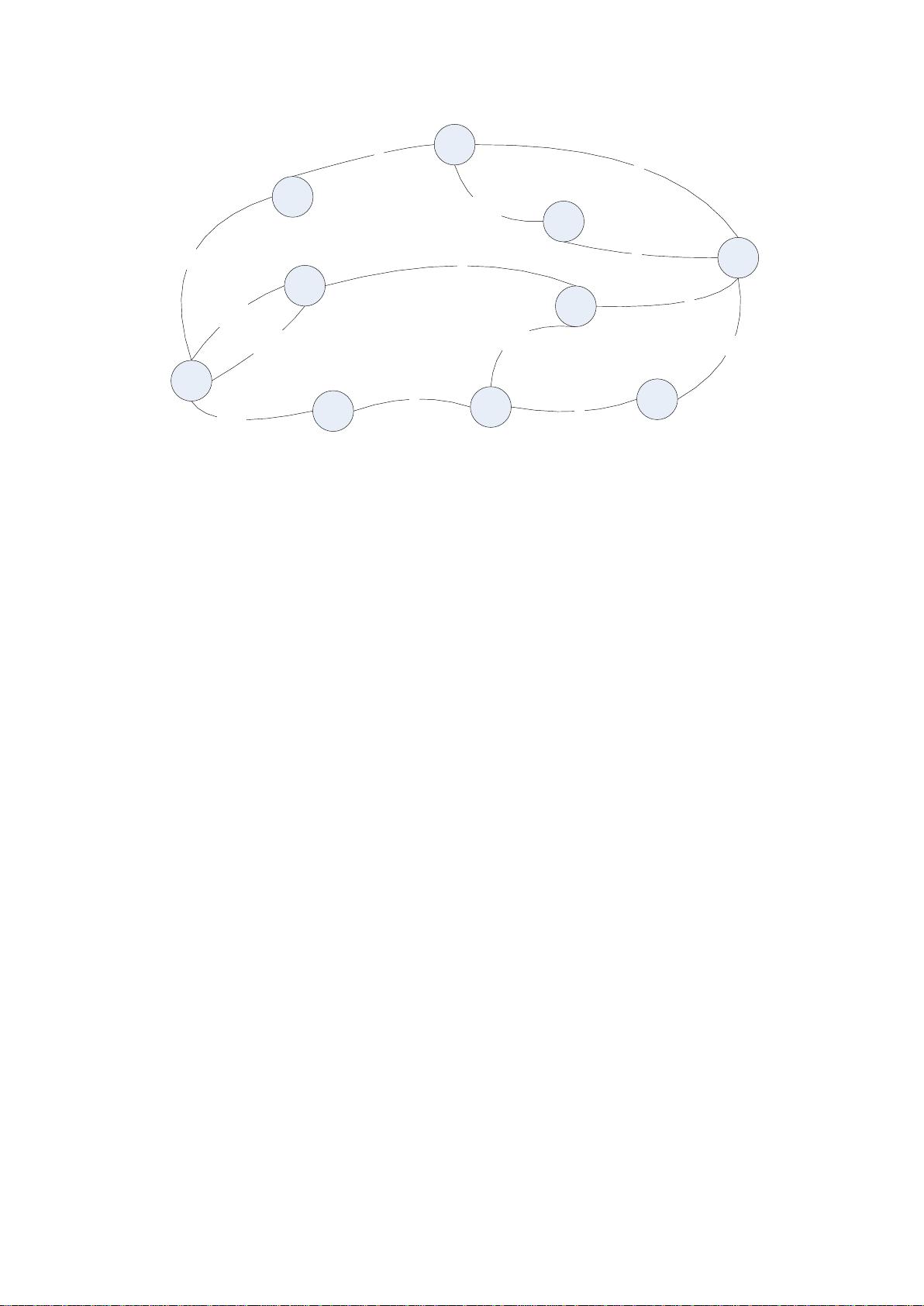
输入到 FST 中的数据为:
String inputValues[] = {"mop","moth","pop","star","stop","top"};
long outputValues[] = {0,1,2,3,4,5};
生成的 FST 图为:

剩余15页未读,继续阅读

芊暖
- 粉丝: 28
- 资源: 339









最新资源
- (178047214)基于springboot图书管理系统.zip
- 张郅奇 的Python学习过程
- (23775420)欧姆龙PLC CP1H-E CP1L-E CJ2M CP1E 以太网通讯.zip
- (174590622)计算机课程设计-IP数据包解析
- (175550824)泛海三江全系调试软件PCSet-All2.0.3 1
- (172742832)实验1 - LC并联谐振回路仿真实验报告1
- 网络搭建练习题.pkt
- 搜索引擎soler的相关介绍 从事搜索行业程序研发、人工智能、存储等技术人员和企业
- 搜索引擎lucen的相关介绍 从事搜索行业程序研发、人工智能、存储等技术人员和企业
- 基于opencv-dnn和一些超过330 FPS的npu
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0