(有启发意义的文章)EE with Generative Adversarial Imitation Learning1
需积分: 0 165 浏览量
2022-08-03
12:31:08
上传
评论
收藏 963KB PDF 举报


Joint Entity and Event Extraction with
Generative Adversarial Imitation Learning
Tongtao Zhang
†
, Heng Ji
†
and Avirup Sil
∗
†
Computer Science Department, Rensselaer Polytechnic Institute
∗
IBM Research AI
Abstract
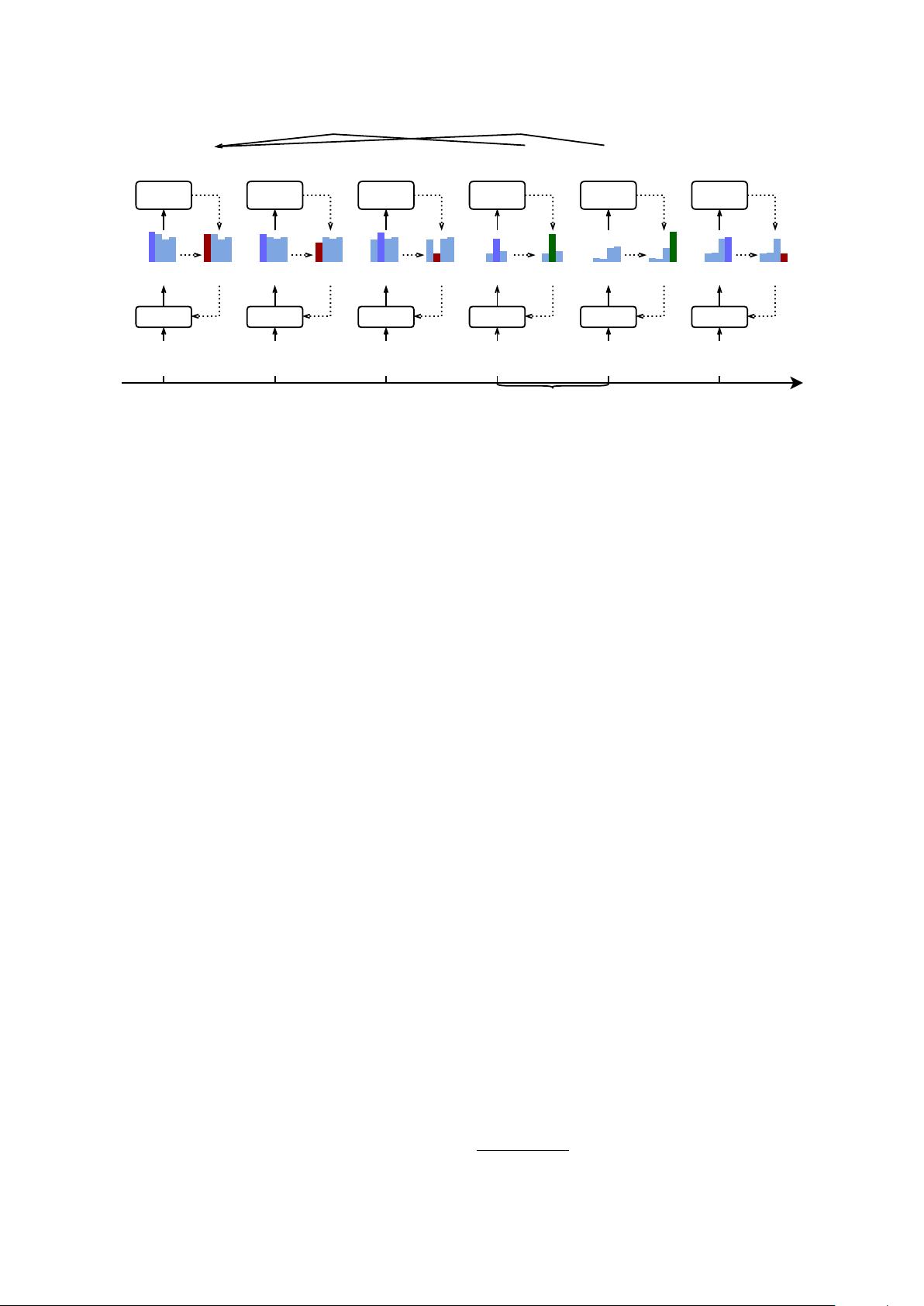
We propose a new framework for entity and
event extraction based on generative adversar-
ial imitation learning – an inverse reinforce-
ment learning method using generative adver-
sarial network (GAN). We assume that in-
stances and labels yield to various extents of
difficulty and the gains and penalties (rewards)
are expected to be diverse. We utilize discrim-
inators to estimate proper rewards according
to the difference between the labels committed
by the ground-truth (expert) and the extractor
(agent). Our experiments demonstrate that the
proposed framework outperforms state-of-the-
art methods.
1 Introduction
Event extraction (EE) is a crucial information ex-
traction (IE) task that focuses on extracting struc-
tured information (i.e., a structure of event trigger
and arguments, “what is happening”, and “who or
what is involved”) from unstructured texts. For
example, in the sentence “Masih’s alleged com-
ments of blasphemy are punishable by death un-
der Pakistan Penal Code” shown in Figure 1,
there is a Sentence event (“punishable”) and
Execute event (“death”) involving the person
entity “Masih”. Most event extraction research
has been in the context of the 2005 NIST Au-
tomatic Content Extraction (ACE) sentence-level
event mention task (Walker et al., 2006), which
also provides the standard corpus. The annotation
guideline of the ACE program defines an event as
a specific occurrence of something that happens
involving participants, often described as a change
of state. More recently, the TAC KBP community
has introduced document-level event argument ex-
traction shared tasks for 2014 and 2015 (KBP EA).
In the last five years, many event extraction
approaches have brought forth encouraging re-
sults by retrieving additional related text docu-
ments (Song et al., 2015), introducing rich fea-
tures of multiple categories (Li et al., 2013; Zhang
et al., 2017b), incorporating relevant information
within or beyond context (Yang and Mitchell,
2016; Judea and Strube, 2016; Yang and Mitchell,
2017; Duan et al., 2017) and adopting neural net-
work frameworks (Chen et al., 2015; Nguyen and
Grishman, 2015; Feng et al., 2016; Nguyen et al.,
2016; Huang et al., 2016; Nguyen and Grish-
man, 2018; Sha et al., 2018; Huang et al., 2018;
Hong et al., 2018; Zhao et al., 2018; Nguyen and
Nguyen, 2018).
However, there are still challenging cases: for
example, in the following sentences: “Masih’s al-
leged comments of blasphemy are punishable by
death under Pakistan Penal Code” and “Scott is
charged with first-degree homicide for the death
of an infant.”, the word death can trigger an
Execute event in the former sentence and a Die
event in the latter one. With similar local infor-
mation (word embeddings) or contextual features
(both sentences include legal events), supervised
models pursue the probability distribution which
resembles that in the training set (e.g., we have
overwhelmingly more Die annotation on death
than Execute), and will label both as a Die
event, causing error in the former instance.
Such mistake is due to the lack of a mecha-
nism that explicitly deals with wrong and confus-
ing labels. Many multi-classification approaches
utilize cross-entropy loss, which aims at boost-
ing the probability of the correct labels and usu-
ally treat wrong labels equally and merely inhibits
them indirectly. Models are trained to capture fea-
tures and weights to pursue correct labels, but will
become vulnerable and unable to avoid mistakes
when facing ambiguous instances, where the prob-
abilities of the confusing and wrong labels are not
sufficiently “suppressed”. Therefore, exploring in-
formation from wrong labels is a key to make the

剩余12页未读,继续阅读
资源评论













