推荐算法——从FM到XDeepFM1
需积分: 0 122 浏览量
2022-08-03
21:15:11
上传
评论
收藏 1.2MB PDF 举报

1.
手
动
提
取
特
征
的
缺
点
挖掘高质量的交互特征需要非常专业的领域知识并且需要做大量尝试,耗费时间和精力。
在大型推荐系统中,原生特征非常庞大,手动挖掘交叉特征几乎不可能。
挖掘不出肉眼不可见的交叉特征。
2. FM
系
列
模
型
FM
模
型
:提取隐向量然后做内积的形式来提取交叉特征,扩展的FM模型更是可以提取随机的高维特征
(DeepFM),
缺
点
:
会
学
习
所
有
交
叉
特
征
,
其
中
肯
定
会
包
含
无
用
的
交
叉
组
合
,
这
些
组
合
会
引
入
噪
音
降
低
模
型
的
表
现
。
(
前
期
的
特
征
选
择
很
重
要
)
针对FM、FFM模型的缺点,随后又出现了几种针对改进的模型:
2.1 FwFM
FFM 算法按照 field 对 latent vector 进行区分,从而提升模型的效果。但是 FFM
算
法
没
有
区
分
不
同
特
征
交
叉
的
重
要
性
,
此
模
型
针
对
不
同
特
征
交
叉
赋
予不
同
的
权
重
,从而达到更精细的计算交叉特征的
目的。
其中, 表示 field 交叉特征的重要性。
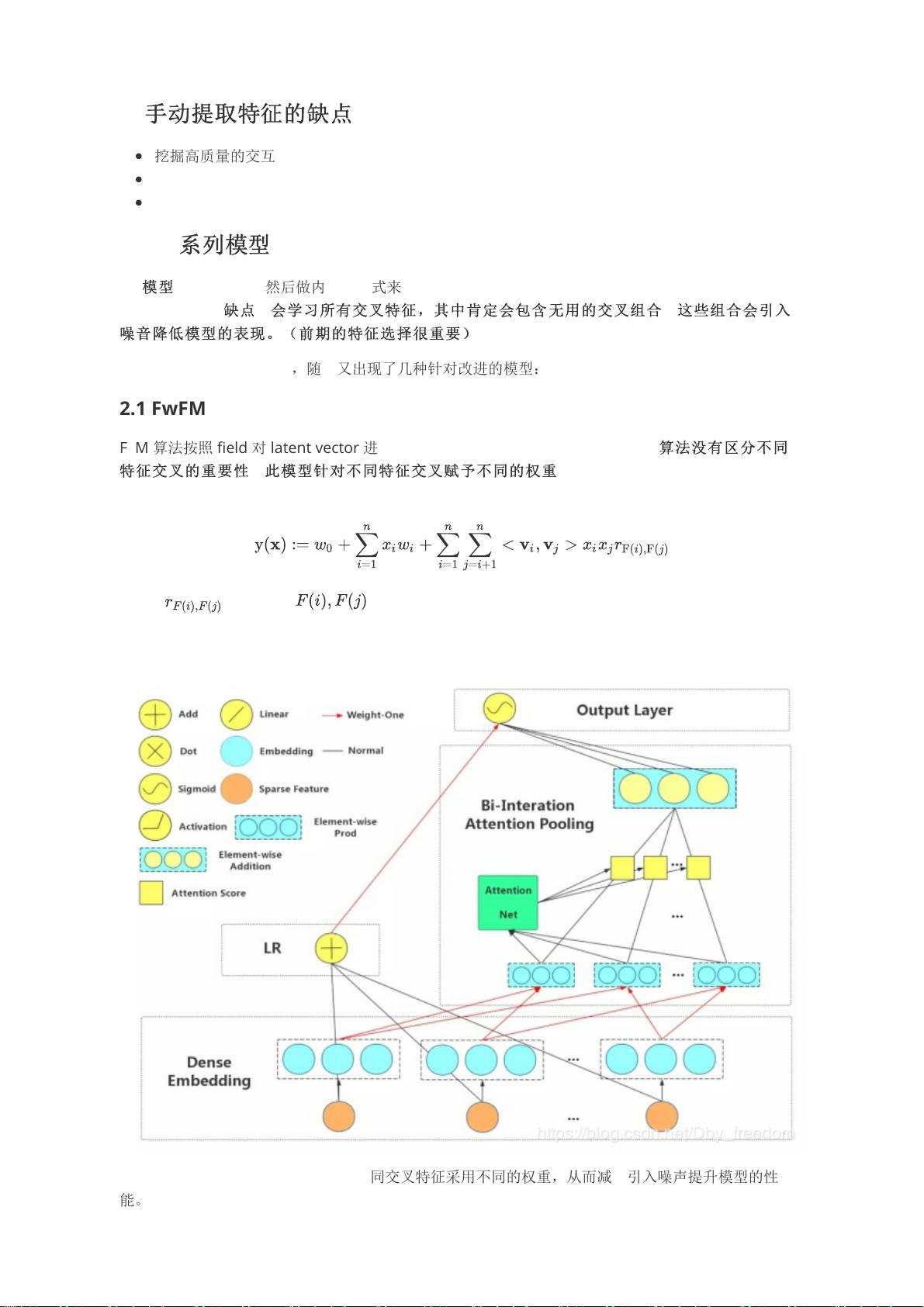
2.2 AFM
AFM 和 FwFM 类似,目标是希望对不同交叉特征采用不同的权重,从而减少引入噪声提升模型的性
能。













评论0