大数据工具011
需积分: 0 198 浏览量
2022-08-08
22:00:26
上传
评论
收藏 777KB DOCX 举报

一共 81 个,开源大数据处理工具汇总(上)
作者:大数据女神-诺蓝(微信公号:dashujunvshen)。本文是 36 大数据专稿,转
载必须标明来源 36 大数据。
本文一共分为上下两部分。我们将针对大数据开源工具不同的用处来进行分类,并且附
上了官网和部分下载链接,希望能给做大数据的朋友做个参考。下面是第一部分。
查询引擎
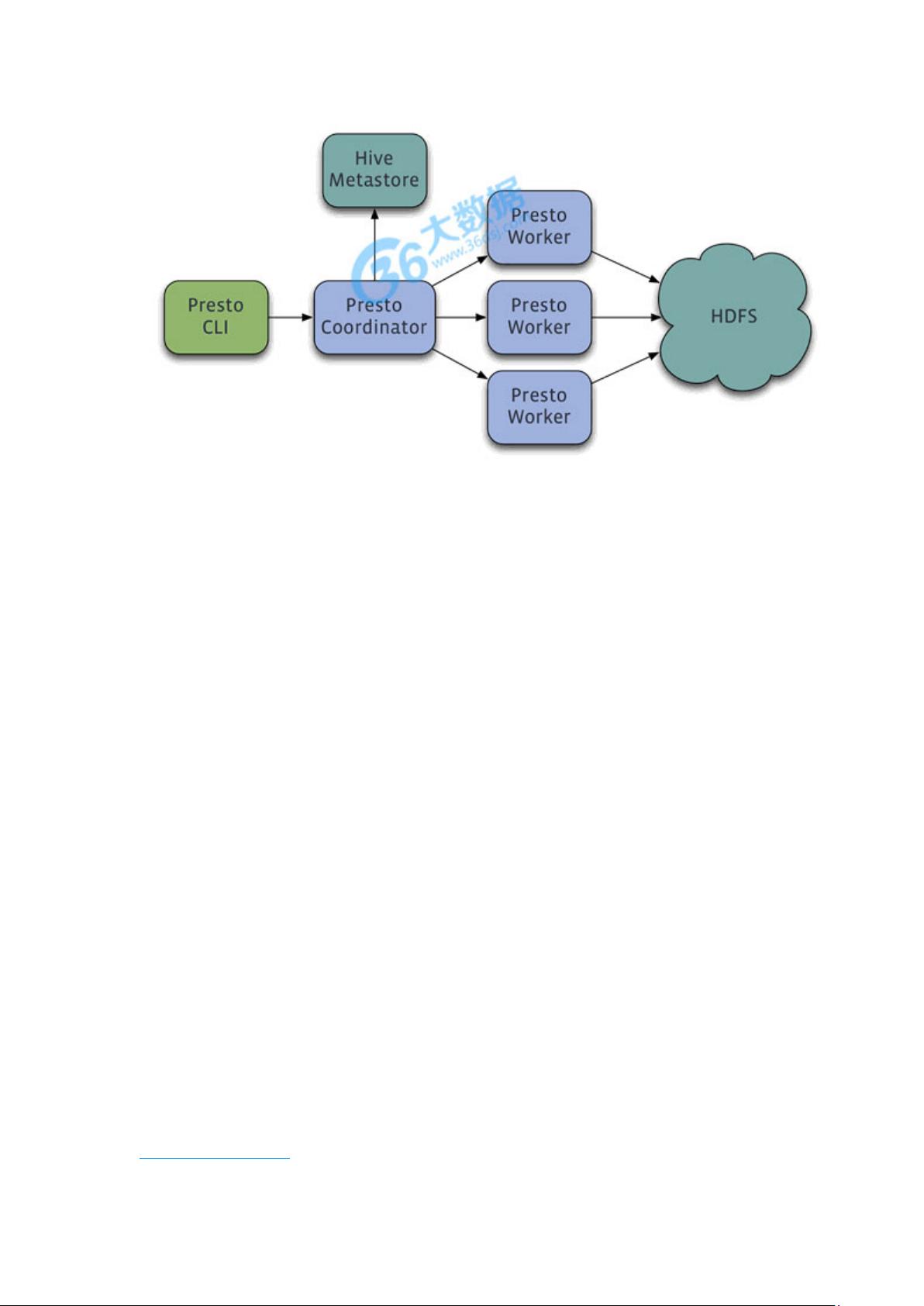
一、Phoenix
贡献者::Salesforce
简介:这是一个 Java 中间层,可以让开发者在 Apache HBase 上执行 SQL 查询。Phoenix
完全使用 Java 编写,代码位于 GitHub 上,并且提供了一个客户端可嵌入的 JDBC 驱
动。
Phoenix 查询引擎会将 SQL 查询转换为一个或多个 HBase scan,并编排执行以生成标
准的 JDBC 结果集。直接使用 HBase API、协同处理器与自定义过滤器,对于简单查询
来说,其性能量级是毫秒,对于百万级别的行数来说,其性能量级是秒。
Phoenix 最值得关注的一些特性有:
❶嵌入式的 JDBC 驱动,实现了大部分的 java.sql 接口,包括元数据 API
❷可以通过多部行键或是键/值单元对列进行建模
❸完善的查询支持,可以使用多个谓词以及优化的扫描键
❹DDL 支持:通过 CREATE TABLE、DROP TABLE 及 ALTER TABLE 来添加/删除列
❺版本化的模式仓库:当写入数据时,快照查询会使用恰当的模式
❻DML 支持:用于逐行插入的 UPSERT VALUES、用于相同或不同表之间大量数据传
输的 UPSERT ❼SELECT、用于删除行的 DELETE
❽通过客户端的批处理实现的有限的事务支持
❾单表——还没有连接,同时二级索引也在开发当中
➓紧跟 ANSI SQL 标准
Phoenix 官方网站>>>
二、Stinger
剩余28页未读,继续阅读

尹子先生
- 粉丝: 18
- 资源: 324









最新资源
- 农村信用社联合社计算机信息系统投产与变更管理办.docx
- 农村信用社联合社计算机信息系统数据管理办法.docx
- 利用SPSS作临床效度分析线上计算网站介绍-医学研究部统计谘.(医学PPT课件).ppt
- 利用Zabbix监控mysqldump定时备份数据库状态.docx
- 利用计算机解决问题的基本过程.doc
- 化工铁路通信工程总结.doc
- 北京大学网络教育软件工程作业.docx
- 医药公司(连锁店)计算机操作规程未新系统的自行按照旧制修改-新系统过制的编号加修模版.doc
- 医药公司(连锁店)计算机系统操作规程模版.doc
- 医药连锁门店计算机系统的操作和管理程序未新系统的自行按照旧制修改-新系统过制的编号加修模版.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0