机器学习与深度学习面试系列十六(自动编码器)1

需积分: 0 87 浏览量
更新于2022-08-03
收藏 542KB PDF 举报
【自动编码器(Auto-Encoder,AE)】自动编码器是一种无监督学习方法,用于学习数据的有效编码,即从原始输入数据中提取出有意义的表示。它由两个主要部分组成:编码器(Encoder)和解码器(Decoder)。编码器将高维度数据压缩成低维度的编码表示,而解码器则尝试从编码表示重构原始输入数据。学习目标是通过最小化重构误差来优化模型。
【深度自编码器(Deep Auto-Encoder)】当自编码器的结构包含多层神经网络时,就形成了深度自编码器。这种结构可以捕获数据的更深层次语义,从而提供更抽象的表示。深度自编码器在处理复杂数据时表现更优,因为它们有能力学习到更复杂的特征结构。
【堆叠自编码器(Stacked Auto-Encoder,SAE)】堆叠自编码器是通过逐层训练多个浅层自编码器来构建的深层网络。训练第一个编码器和最后一个解码器形成一个浅层自编码器,然后使用其编码层的输出作为下一层的输入,继续训练下一层的编码器和解码器,如此递进,直至达到所需的深度。这种贪婪训练方法使得每一层都能够专注于学习特定层次的特征。
【欠完备自编码器(Undercomplete Auto-Encoder)】欠完备自编码器指的是编码器的输出维度小于输入数据的维度。这样,自编码器无法简单地复制输入,必须学习识别和保留输入数据的关键特征。当解码器是线性且损失函数为均方误差时,欠完备自编码器可以学到与主成分分析(PCA)相似的子空间,而在非线性情况下的自编码器则能学习到更强大的PCA推广。
【正则自编码器】为了迫使自编码器学习更有用的表示,可以引入正则化技术。比如,稀疏自编码器和降噪自编码器。
【稀疏自编码器(Sparse Auto-Encoder)】在中间隐藏层的维度大于输入样本维度的情况下,稀疏自编码器通过正则化损失函数强制编码层输出保持稀疏。这有助于学习数据的显著特征,适用于后续的分类等任务。
【降噪自编码器(Denoising Auto-Encoder)】降噪自编码器通过在输入数据中引入噪声来提高模型的鲁棒性。训练时,模型试图从损坏或带有噪声的数据中重构原始无损输入。这有助于学习数据的内在结构,即使在部分信息丢失的情况下也能恢复原始信息。
【自编码器的Encoder和Decoder对称性】早期的研究中,人们通常让编码器和解码器的结构对称,权重也相同。但这不是必需的。现在,自编码器的设计更灵活,可以采用不对称结构,如卷积自编码器中,编码器可能使用卷积层,而解码器可能使用反卷积层,或者在其他结构中进行创新设计,以适应特定任务的需求。捆绑权重(Tied Weight)策略是早期常见的做法,即编码器和解码器的权重矩阵共享,减少了模型参数,同时也起到了正则化的效果。然而,现代自编码器模型并不局限于这一约束。
机
器
学
习
与
深
度
学
习
⾯
试
系
列
⼗
六
(
⾃
动
编
码
器
)
什么
是
⾃
编
码
器
(
AE
)?
⾃
编
码
器
(
A
uto
-
E
n
c
o
de
r
,
AE
)
是
通过
⽆
监督的
⽅
式
来
学
习
⼀
组
数据
的
有
效
编
码
(
或
表
示
)
。
深
度
学
习
⼤
⽜
L
e
C
un
认
为
这
⾥
叫
⾃
监督
学
习
(
S
elf
-
sup
e
rv
i
s
ed
L
ea
rn
i
n
g
)
更
为
准
确
。
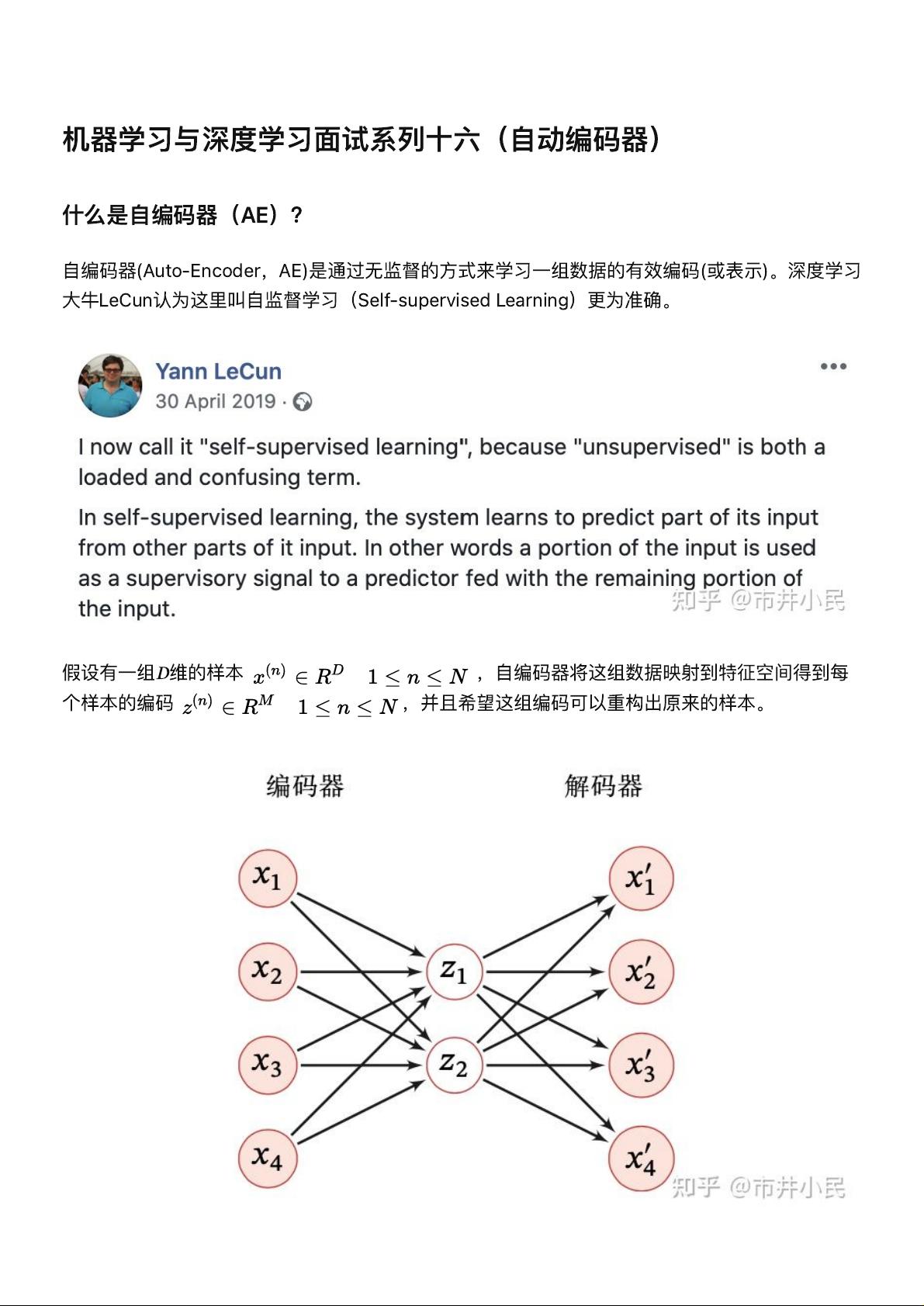
假
设
有
⼀
组
𝐷
维
的
样本
,
⾃
编
码
器
将
这
组
数据
映
射
到
特
征
空
间
得
到
每
个
样本
的
编
码
,
并
且
希
望
这
组编
码
可
以
重
构
出
原
来
的
样本
。
下载后可阅读完整内容,剩余3页未读,立即下载
181 浏览量
128 浏览量
2022-08-03 上传
178 浏览量
110 浏览量
115 浏览量
139 浏览量
151 浏览量
2019-05-26 上传
2024-06-13 上传
2020-04-09 上传
2023-10-16 上传
2020-01-19 上传
2021-05-10 上传
2018-05-04 上传
122 浏览量
2024-05-06 上传
159 浏览量
2018-07-27 上传
186 浏览量
资源评论


葡萄的眼泪
- 粉丝: 19
- 资源: 303









最新资源
- 集装箱吊车门机起重机电气电器图纸一套这是调试后的最终版图纸,含程序,元件清单,集装箱的,供学习参考用,这是电气图纸,没有机械的 plc是315-2dp,行车图纸有很多,串电阻的,各种变频,plc通讯
- 用html表单元素画的一棵旋转圣诞树
- 本地磁盘随意学习提供使用
- 职业与睡眠健康.zip
- 本地磁盘随意学习提供使用
- 墙外unity下载报错,版本2021.3.1f1
- 基于支持向量机(SVM)的手写字母识别 matlab代码
- Cursor安装包,想学习的Cursor可以免费使用
- Yealink VC Desktop1.28.0.72, 免费,局域网,IP电话, SIP, VOIP, 视频通话,可与手机互通,手机上也安装 yealink, apk包
- 日常业务完整版.pdf
- 基于S7-200 PLC和组态王组态切片机控制系统 带解释的梯形图程序,接线图原理图图纸,io分配,组态画面
- 全自动热封冷切制袋机x_t全套技术开发资料100%好用.zip
- CSDN项目管理系统 2024-11-01T15-51-11+011800.html
- 12.27ppt.zip
- FURIN Promoter 甲基化水平预测糖尿病.zip
- 热水壶自动ZN-Q5卷边机sw14可编辑全套技术开发资料100%好用.zip
