分布式锁实现方式1

需积分: 0 71 浏览量
更新于2022-08-03
收藏 84KB PDF 举报
分布式锁是一种在分布式系统中实现同步访问同一资源的机制,主要解决的是在多台服务器上进行数据一致性控制的问题。在微服务和云计算环境下,分布式锁是必不可少的组件,用于协调不同节点之间的操作,确保对共享资源的互斥访问。本文将深入探讨三种常见的分布式锁实现方式:数据库实现、Redis缓存实现以及ZooKeeper实现,并分析它们各自的优缺点及适用场景。
我们来看数据库实现方式。这种方式通常是在数据库中创建一张专门的锁表,对于需要锁定的临界资源设置唯一性约束。当需要加锁时,尝试插入一条新的记录,释放锁时则删除对应的记录。这种方法简单直观,易于理解。然而,它的缺点也很明显,如容易出现单点故障,如果数据库挂掉,整个锁机制也会失效;同时,由于涉及数据库的读写操作,可能会引发死锁问题,且性能较低,不适合高并发场景。因此,数据库实现的分布式锁更适合并发量低、对性能要求不高的应用。
Redis缓存实现方式使用了Redis提供的`setnx`命令,这个命令能够在键不存在的情况下设置键值对。键作为锁的标识,值包含当前时间加上超时时间,这样可以避免锁无法释放的问题。如果`setnx`返回1,表示成功获取锁,返回0则表示失败。这种方式的优点是性能高,可跨集群部署,无单点故障,实现相对简单。但其锁失效时间的控制并不稳定,依赖于客户端的准确计算,而且其可靠性和ZooKeeper相比稍弱,对于锁的理解也相对复杂。适用于高并发、对性能有较高要求的场景。
ZooKeeper是一种分布式协调服务,它提供了分布式锁的实现。在ZooKeeper中,每个进程会在共享的`shared_lock`目录下创建一个临时顺序节点,节点编号最小的获得锁。这种方式的优点是无单点故障,能解决不可重入和死锁问题,可靠性较高,实现相对简单。然而,性能方面相比Redis缓存略逊一筹,理解和使用难度也较大。ZooKeeper适合大部分分布式场景,但对于性能要求极高的应用可能不太合适。
总结来说,不同的分布式锁实现方式各有优势和局限性。数据库实现适合简单的低并发场景,Redis缓存实现适合高性能需求,而ZooKeeper实现则在可靠性与复杂性之间找到了平衡,适用于大多数分布式环境。在选择合适的分布式锁实现时,应根据实际应用的需求,如并发量、性能要求、容错性等因素综合考虑。
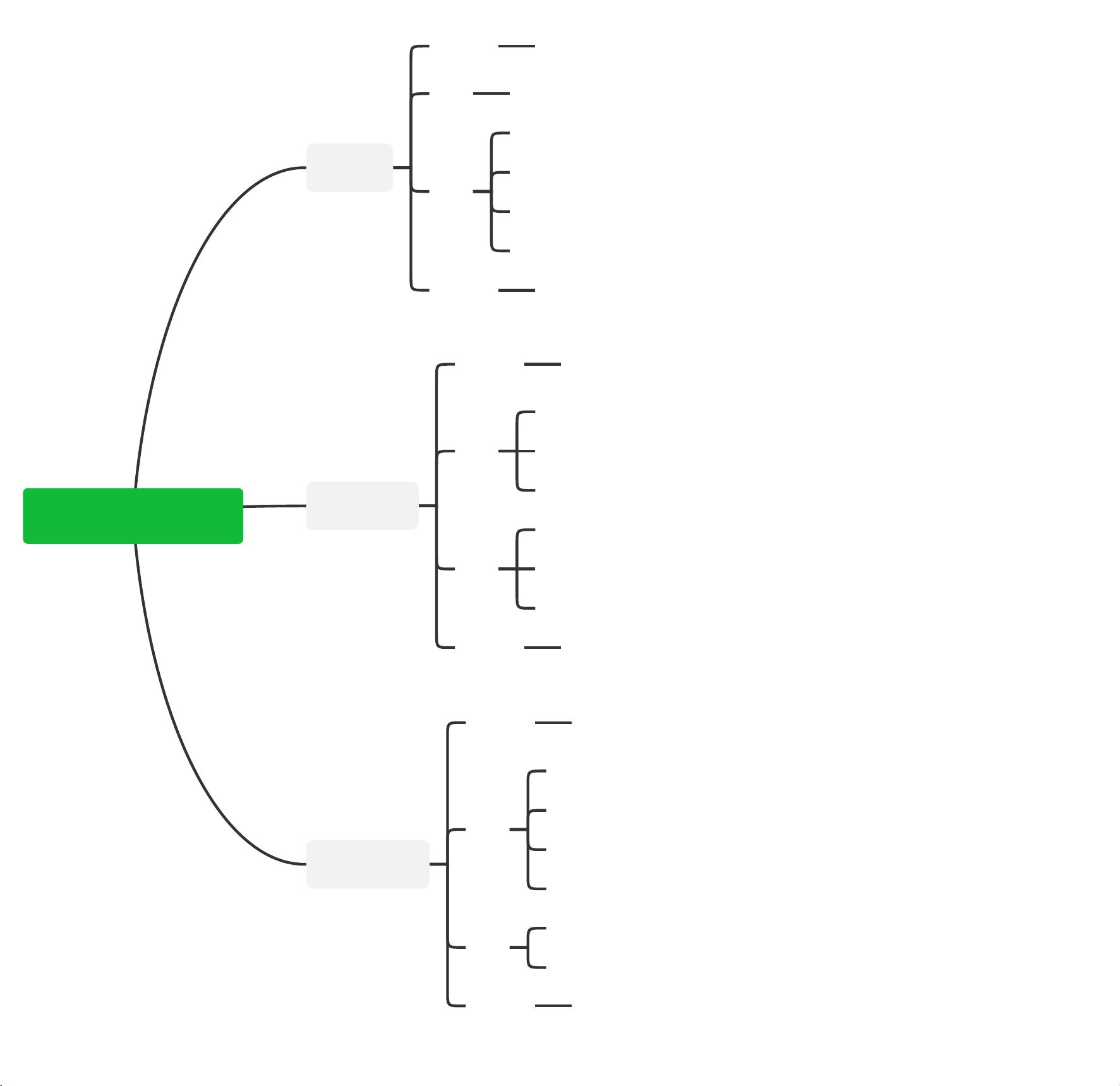
分布式锁实现方式
数据库
实现方式
创建一张锁表,对临界资源做唯一性约束;
要锁住某资源时就增加一条记录,释放铁时删除记录
优点
容易理解
缺点
易出现单点故障问题、死锁问题
实现复杂
性能低
可靠性低
应用场景
适用于并发量低、性能要求低的场景
Redis缓存
实现方式
通过函数setnx(key,value)实现,key表示锁id,value为当前时间+超时时间;
setnx返回1则表示获得key所代表的锁,返回0则表示获取失败
优点
性能高
可以跨集群部署,无单点故障问题
易于实现
缺点
锁失效时间的控制不稳定
可靠性不如ZooKeeper
不易理解
应用场景
适用于高并发、对性能要求高的场景
ZooKeeper
实现方式
在对应的持久节点shared_lock的目录下为每个进程创建一个临时顺序节点,每个节
点确定的编号是否最小,若最小,则获得锁;否则等待更小编号节点释放锁
优点
无单点故障、不可重入、死锁问题
几乎解决了数据库锁和缓存式锁的不足
可靠性高
易于实现
缺点
性能没有缓存式分布式锁好
难以理解
应用场景
ZooKeeper适用于大部分分布式场景,但是不适用于对性能要求极高的场景
下载后可阅读完整内容,剩余0页未读,立即下载
101 浏览量
2020-08-19 上传
110 浏览量
2022-08-03 上传
2018-09-26 上传
2018-02-28 上传
2017-09-20 上传
156 浏览量
150 浏览量
170 浏览量
资源评论











