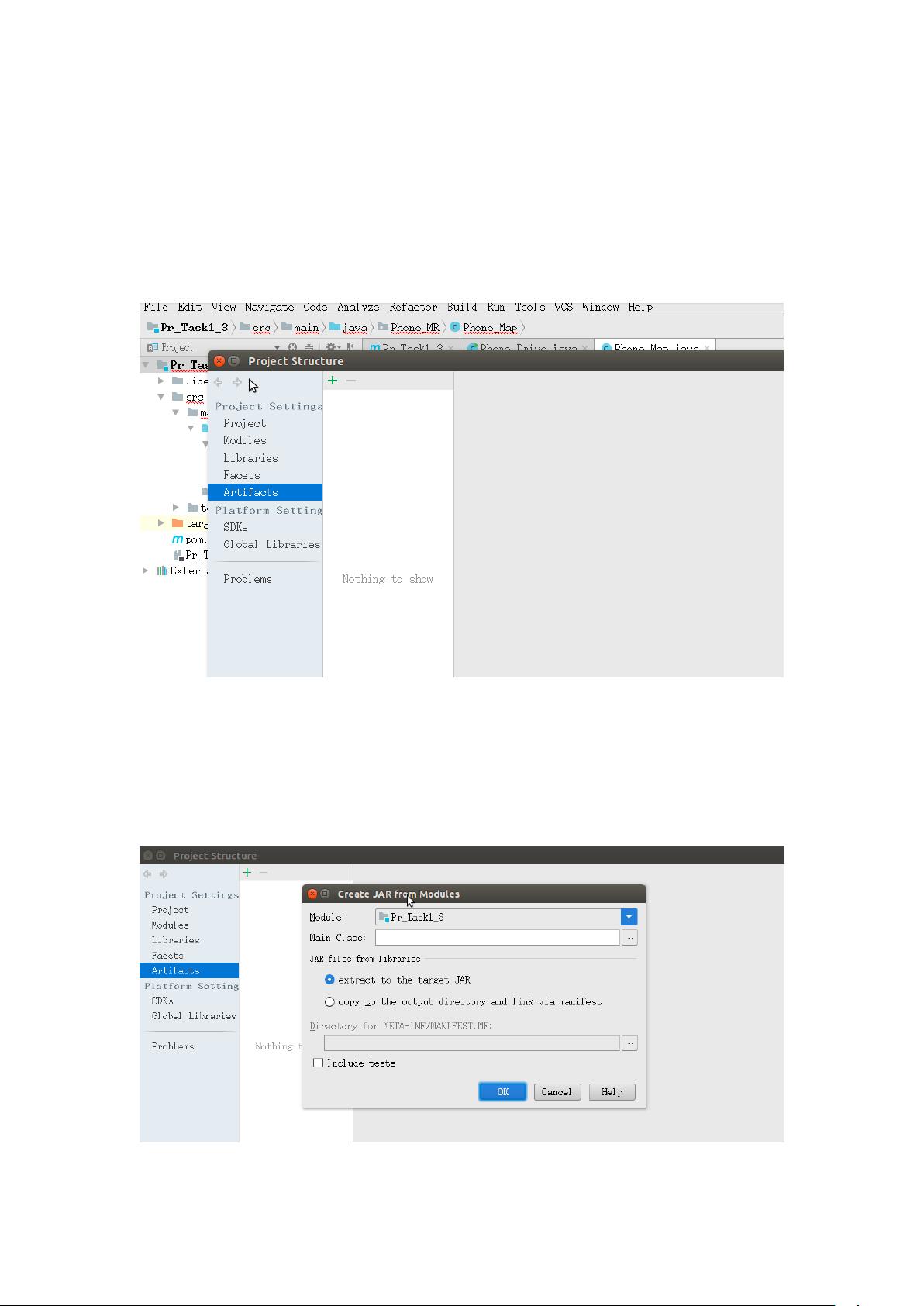
: "Hadoop MapReduce程序的打包与运行指南" : 在Hadoop环境中,开发MapReduce程序后,需要将其打包成JAR文件才能在集群上运行。本指南将详细介绍如何进行这一过程,并最终在Master节点上执行Hadoop MapReduce任务。 【正文】: 1. **MapReduce程序打包流程**: - **步骤1**: 打开IDE(如IntelliJ IDEA或Eclipse),在主菜单中选择“File”然后点击“Project Structure”。这将打开项目结构配置界面。 - **步骤2**: 在Project Structure界面中,点击"+"按钮以添加新的项目元素。选择“JAR”并进一步选择“From modules with dependencies”。这将启动创建JAR包的向导。 - **步骤3**: 在“Create JAR from Modules”窗口中,指定主类。点击“Main Class”后的选项按钮,从项目中选择你的MapReduce程序的主驱动类。例如,这里我们选择“test”包下的“drive”类。 - **步骤4**: 确认设置无误后,点击“OK”。返回Project Structure界面,你会看到新生成的JAR包,如“Pr_Task3_3.jar”。 - **步骤5**: 打包完成后,IDE的主界面将显示新增加的“META-INF”文件夹,这是JAR文件的标准目录结构之一,包含元数据信息。 - **步骤6**: 接下来,进行构建操作。转到“Build”菜单,选择“Build Artifacts”,然后按照提示进行,这将生成你的JAR包,如“Pr_Task1_3.jar”。 2. **将JAR文件上传至Master节点**: 使用命令行工具,如`scp`,将生成的JAR文件从本地机器复制到Hadoop集群的Master节点。例如,运行以下命令: ``` scp -r /home/developer/Desktop/src/out/Pr_Task3_3.jar root@192.168.3.100:/home/ ``` 这将把JAR文件发送到IP地址为192.168.3.100的Master节点的/home目录下。 3. **运行Hadoop MapReduce任务**: 在Master节点上,使用Hadoop的`jar`命令来运行MapReduce任务。格式如下: ``` hadoop jar /path/to/jar/file/main_class input_directory output_directory ``` 对应于我们的示例,命令可能是: ``` hadoop jar /home/Pr_Task3_3.jar Phone_MR.Phone_Drive input_directory output_directory ``` 其中,“Phone_MR.Phone_Drive”是MapReduce程序的主类名,“input_directory”是输入数据所在的目录,而“output_directory”则是结果输出的位置。 总结来说,Hadoop MapReduce程序的打包涉及到项目结构配置、主类指定、JAR生成、文件传输以及最后在Hadoop集群上的执行。这个过程对于理解和部署Hadoop解决方案至关重要,确保了分布式环境中的正确运行。理解这些步骤对于任何在Hadoop生态系统中工作的开发者都是必不可少的基础知识。
本内容试读结束,登录后可阅读更多
下载后可阅读完整内容,剩余3页未读,立即下载














评论0