【课程笔记】分布式消息通讯之Kafka的实现原理1

需积分: 0 73 浏览量
更新于2022-08-04
收藏 17.45MB PDF 举报
分布式消息通讯之Kafka的实现原理
Kafka是一种高吞吐量、可持久化、可水平扩展、支持多分区的分布式消息队列系统。其核心实现原理可以分为两大部分:副本数据同步原理和副本leader选举原理。
副本数据同步原理:
Kafka中每个Topic都可以被分为多个Partition,每个Partition都有一个Leader和多个Follower。Producer在发布消息时,会将消息发送到该Partition的Leader,Leader会将该消息写入其本地Log,然后每个Follower从Leader pull数据,以保持数据顺序的一致性。Follower在收到该消息并写入其Log后,向Leader发送ACK,一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW(HighWatermark)并且向Producer发送ACK。
ISR(In-Sync Replica)是Kafka中的一种机制,用于确保已经commit的数据不丢失。在ISR中至少有一个follower时,Kafka可以确保已经commit的数据不丢失,但如果某个Partition的所有Replica都宕机了,就无法保证数据不丢失了。
副本leader选举原理:
在ISR中至少有一个follower时,Kafka可以选择第一个“活”过来的Replica作为Leader,如果ISR中的所有Replica都无法“活”过来了,或者数据都丢失了,这个Partition将永远不可用。选择第一个“活”过来的Replica作为Leader,而这个Replica不是ISR中的Replica,那即使它并不保证已经包含了所有已commit的消息,它也会成为Leader而作为consumer的数据源。
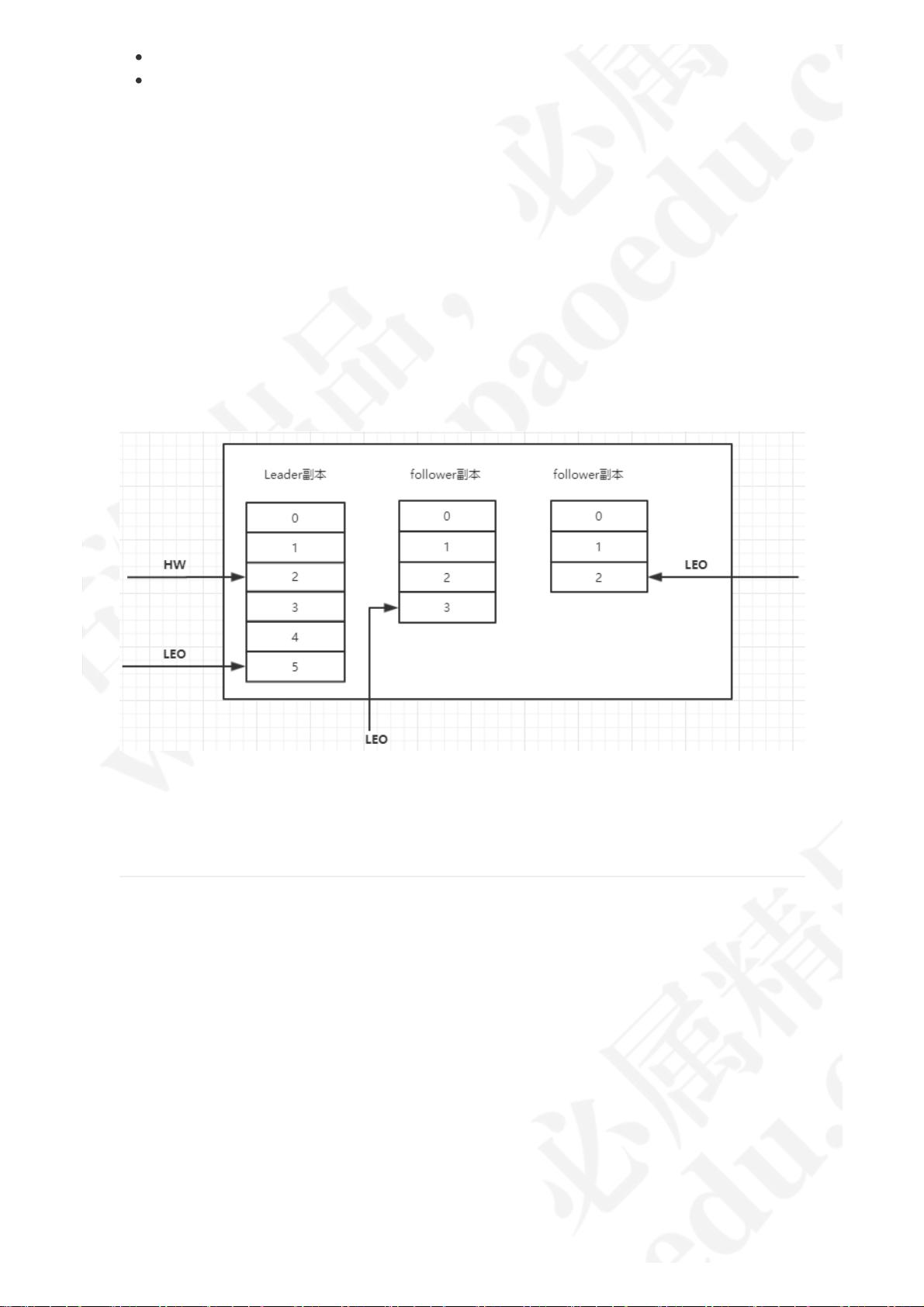
LEO(Log End Offset)和HW(High Watermark)是Kafka中两种重要的概念。LEO记录了该副本底层日志中下一条消息的位移值,HW记录了已经commit的消息的位移值。leader LEO和follower LEO的更新是有区别的,小于等于HW值的所有消息都被认为是“已备份”的(replicated)。
在副本数据同步过程中,follower副本的LEO会不断地追赶到leader副本,以保持数据的一致性。这也会使得被踢出的follower副本重新加入到ISR集合中,并且可以使得这个Partition的HW发生变化。
初始状态下,leader和follower的HW和LEO都是0,leader副本会保存remote LEO,表示所有follower LEO,也会被初始化为0。follower会不断地向leader发送FETCH请求,以获取数据,但如果没有数据,这个请求会被leader寄存,直到指定的时间之后会强制完成请求。
Kafka的分布式消息通讯机制可以确保消息的可靠性和可用性,同时也提供了高吞吐量和可水平扩展的特性。

如何处理所有的Replica不工作的情况
在ISR中至少有一个follower时,Kafka可以确保已经commit的数据不丢失,但如果某个Partition的所
有Replica都宕机了,就无法保证数据不丢失了
1. 等待ISR中的任一个Replica“活”过来,并且选它作为Leader
2. 选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader
这就需要在可用性和一致性当中作出一个简单的折衷。
如果一定要等待ISR中的Replica“活”过来,那不可用的时间就可能会相对较长。而且如果ISR中的所有
Replica都无法“活”过来了,或者数据都丢失了,这个Partition将永远不可用。
选择第一个“活”过来的Replica作为Leader,而这个Replica不是ISR中的Replica,那即使它并不保证已
经包含了所有已commit的消息,它也会成为Leader而作为consumer的数据源(前文有说明,所有读
写都由Leader完成)。在我们课堂讲的版本中,使用的是第一种策略。
副本数据同步原理
了解了副本的协同过程以后,还有一个最重要的机制,就是数据的同步过程。它需要解决
1. 怎么传播消息
2. 在向消息发送端返回ack之前需要保证多少个Replica已经接收到这个消息
数据的处理过程是
下图中,深红色部分表示test_replica分区的leader副本,另外两个节点上浅色部分表示follower副本
Producer在发布消息到某个Partition时,
先通过ZooKeeper找到该Partition的Leader get
/brokers/topics/<topic>/partitions/2/state ,然后无论该Topic的Replication Factor为多
少(也即该Partition有多少个Replica),Producer只将该消息发送到该Partition的Leader。
Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower
存储的数据顺序与Leader保持一致。
剩余11页未读,继续阅读
资源评论


两斤香菜
- 粉丝: 22
- 资源: 297









